 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Test-time Inference for Visual Grounding
Jan 20, 2026Visual grounding is an essential capability of Visual Language Models (VLMs) to understand the real physical world. Previous state-of-the-art grounding visual language models usually have large model sizes, making them heavy for deployment and slow for inference. However, we notice that the sizes of visual encoders are nearly the same for small and large VLMs and the major difference is the sizes of the language models. Small VLMs fall behind larger VLMs in grounding because of the difference in language understanding capability rather than visual information handling. To mitigate the gap, we introduce 'Efficient visual Grounding language Models' (EGM): a method to scale the test-time computation (#generated tokens). Scaling the test-time computation of a small model is deployment-friendly, and yields better end-to-end latency as the cost of each token is much cheaper compared to directly running a large model. On the RefCOCO benchmark, our EGM-Qwen3-VL-8B demonstrates 91.4 IoU with an average of 737ms (5.9x faster) latency while Qwen3-VL-235B demands 4,320ms to achieve 90.5 IoU. To validate our approach's generality, we further set up a new amodal grounding setting that requires the model to predict both the visible and occluded parts of the objects. Experiments show our method can consistently and significantly improve the vanilla grounding and amodal grounding capabilities of small models to be on par with or outperform the larger models, thereby improving the efficiency for visual grounding.
Anti-Length Shift: Dynamic Outlier Truncation for Training Efficient Reasoning Models
Jan 07, 2026Large reasoning models enhanced by reinforcement learning with verifiable rewards have achieved significant performance gains by extending their chain-of-thought. However, this paradigm incurs substantial deployment costs as models often exhibit excessive verbosity on simple queries. Existing efficient reasoning methods relying on explicit length penalties often introduce optimization conflicts and leave the generative mechanisms driving overthinking largely unexamined. In this paper, we identify a phenomenon termed length shift where models increasingly generate unnecessary reasoning on trivial inputs during training. To address this, we introduce Dynamic Outlier Truncation (DOT), a training-time intervention that selectively suppresses redundant tokens. This method targets only the extreme tail of response lengths within fully correct rollout groups while preserving long-horizon reasoning capabilities for complex problems. To complement this intervention and ensure stable convergence, we further incorporate auxiliary KL regularization and predictive dynamic sampling. Experimental results across multiple model scales demonstrate that our approach significantly pushes the efficiency-performance Pareto frontier outward. Notably, on the AIME-24, our method reduces inference token usage by 78% while simultaneously increasing accuracy compared to the initial policy and surpassing state-of-the-art efficient reasoning methods.
Generalist vs Specialist Time Series Foundation Models: Investigating Potential Emergent Behaviors in Assessing Human Health Using PPG Signals
Oct 16, 2025



Foundation models are large-scale machine learning models that are pre-trained on massive amounts of data and can be adapted for various downstream tasks. They have been extensively applied to tasks in Natural Language Processing and Computer Vision with models such as GPT, BERT, and CLIP. They are now also increasingly gaining attention in time-series analysis, particularly for physiological sensing. However, most time series foundation models are specialist models - with data in pre-training and testing of the same type, such as Electrocardiogram, Electroencephalogram, and Photoplethysmogram (PPG). Recent works, such as MOMENT, train a generalist time series foundation model with data from multiple domains, such as weather, traffic, and electricity. This paper aims to conduct a comprehensive benchmarking study to compare the performance of generalist and specialist models, with a focus on PPG signals. Through an extensive suite of total 51 tasks covering cardiac state assessment, laboratory value estimation, and cross-modal inference, we comprehensively evaluate both models across seven dimensions, including win score, average performance, feature quality, tuning gain, performance variance, transferability, and scalability. These metrics jointly capture not only the models' capability but also their adaptability, robustness, and efficiency under different fine-tuning strategies, providing a holistic understanding of their strengths and limitations for diverse downstream scenarios. In a full-tuning scenario, we demonstrate that the specialist model achieves a 27% higher win score. Finally, we provide further analysis on generalization, fairness, attention visualizations, and the importance of training data choice.
SelfAug: Mitigating Catastrophic Forgetting in Retrieval-Augmented Generation via Distribution Self-Alignment
Sep 04, 2025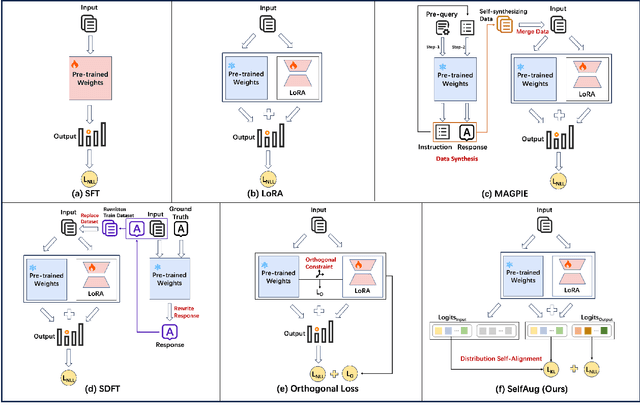
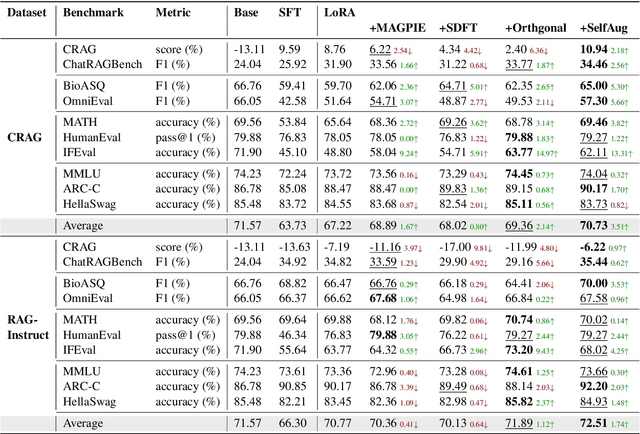
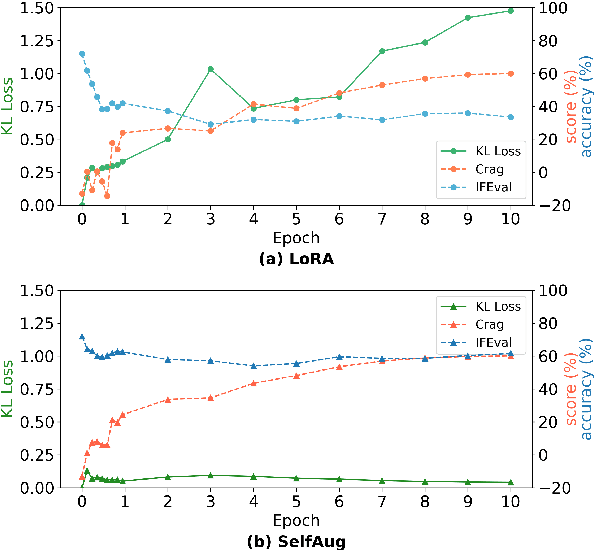
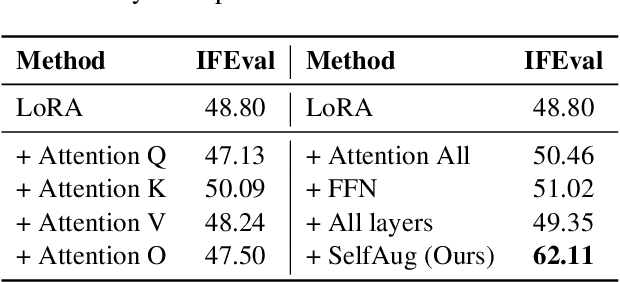
Recent advancements in large language models (LLMs) have revolutionized natural language processing through their remarkable capabilities in understanding and executing diverse tasks. While supervised fine-tuning, particularly in Retrieval-Augmented Generation (RAG) scenarios, effectively enhances task-specific performance, it often leads to catastrophic forgetting, where models lose their previously acquired knowledge and general capabilities. Existing solutions either require access to general instruction data or face limitations in preserving the model's original distribution. To overcome these limitations, we propose SelfAug, a self-distribution alignment method that aligns input sequence logits to preserve the model's semantic distribution, thereby mitigating catastrophic forgetting and improving downstream performance. Extensive experiments demonstrate that SelfAug achieves a superior balance between downstream learning and general capability retention. Our comprehensive empirical analysis reveals a direct correlation between distribution shifts and the severity of catastrophic forgetting in RAG scenarios, highlighting how the absence of RAG capabilities in general instruction tuning leads to significant distribution shifts during fine-tuning. Our findings not only advance the understanding of catastrophic forgetting in RAG contexts but also provide a practical solution applicable across diverse fine-tuning scenarios. Our code is publicly available at https://github.com/USTC-StarTeam/SelfAug.
ACT: Automated Constraint Targeting for Multi-Objective Recommender Systems
Sep 03, 2025Recommender systems often must maximize a primary objective while ensuring secondary ones satisfy minimum thresholds, or "guardrails." This is critical for maintaining a consistent user experience and platform ecosystem, but enforcing these guardrails despite orthogonal system changes is challenging and often requires manual hyperparameter tuning. We introduce the Automated Constraint Targeting (ACT) framework, which automatically finds the minimal set of hyperparameter changes needed to satisfy these guardrails. ACT uses an offline pairwise evaluation on unbiased data to find solutions and continuously retrains to adapt to system and user behavior changes. We empirically demonstrate its efficacy and describe its deployment in a large-scale production environment.
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL
Aug 13, 2025Recent advancements in LLM-based agents have demonstrated remarkable capabilities in handling complex, knowledge-intensive tasks by integrating external tools. Among diverse choices of tools, search tools play a pivotal role in accessing vast external knowledge. However, open-source agents still fall short of achieving expert-level Search Intelligence, the ability to resolve ambiguous queries, generate precise searches, analyze results, and conduct thorough exploration. Existing approaches fall short in scalability, efficiency, and data quality. For example, small turn limits in existing online RL methods, e.g. <=10, restrict complex strategy learning. This paper introduces ASearcher, an open-source project for large-scale RL training of search agents. Our key contributions include: (1) Scalable fully asynchronous RL training that enables long-horizon search while maintaining high training efficiency. (2) A prompt-based LLM agent that autonomously synthesizes high-quality and challenging QAs, creating a large-scale QA dataset. Through RL training, our prompt-based QwQ-32B agent achieves substantial improvements, with 46.7% and 20.8% Avg@4 gains on xBench and GAIA, respectively. Notably, our agent exhibits extreme long-horizon search, with tool calls exceeding 40 turns and output tokens exceeding 150k during training time. With a simple agent design and no external LLMs, ASearcher-Web-QwQ achieves Avg@4 scores of 42.1 on xBench and 52.8 on GAIA, surpassing existing open-source 32B agents. We open-source our models, training data, and codes in https://github.com/inclusionAI/ASearcher.
A Semantic Segmentation Algorithm for Pleural Effusion Based on DBIF-AUNet
Aug 08, 2025Pleural effusion semantic segmentation can significantly enhance the accuracy and timeliness of clinical diagnosis and treatment by precisely identifying disease severity and lesion areas. Currently, semantic segmentation of pleural effusion CT images faces multiple challenges. These include similar gray levels between effusion and surrounding tissues, blurred edges, and variable morphology. Existing methods often struggle with diverse image variations and complex edges, primarily because direct feature concatenation causes semantic gaps. To address these challenges, we propose the Dual-Branch Interactive Fusion Attention model (DBIF-AUNet). This model constructs a densely nested skip-connection network and innovatively refines the Dual-Domain Feature Disentanglement module (DDFD). The DDFD module orthogonally decouples the functions of dual-domain modules to achieve multi-scale feature complementarity and enhance characteristics at different levels. Concurrently, we design a Branch Interaction Attention Fusion module (BIAF) that works synergistically with the DDFD. This module dynamically weights and fuses global, local, and frequency band features, thereby improving segmentation robustness. Furthermore, we implement a nested deep supervision mechanism with hierarchical adaptive hybrid loss to effectively address class imbalance. Through validation on 1,622 pleural effusion CT images from Southwest Hospital, DBIF-AUNet achieved IoU and Dice scores of 80.1% and 89.0% respectively. These results outperform state-of-the-art medical image segmentation models U-Net++ and Swin-UNet by 5.7%/2.7% and 2.2%/1.5% respectively, demonstrating significant optimization in segmentation accuracy for complex pleural effusion CT images.
Estimating 2D Camera Motion with Hybrid Motion Basis
Jul 30, 2025Estimating 2D camera motion is a fundamental computer vision task that models the projection of 3D camera movements onto the 2D image plane. Current methods rely on either homography-based approaches, limited to planar scenes, or meshflow techniques that use grid-based local homographies but struggle with complex non-linear transformations. A key insight of our work is that combining flow fields from different homographies creates motion patterns that cannot be represented by any single homography. We introduce CamFlow, a novel framework that represents camera motion using hybrid motion bases: physical bases derived from camera geometry and stochastic bases for complex scenarios. Our approach includes a hybrid probabilistic loss function based on the Laplace distribution that enhances training robustness. For evaluation, we create a new benchmark by masking dynamic objects in existing optical flow datasets to isolate pure camera motion. Experiments show CamFlow outperforms state-of-the-art methods across diverse scenarios, demonstrating superior robustness and generalization in zero-shot settings. Code and datasets are available at our project page: https://lhaippp.github.io/CamFlow/.
QuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation
Jul 17, 2025Reinforcement learning (RL) has become a key component in training large language reasoning models (LLMs). However, recent studies questions its effectiveness in improving multi-step reasoning-particularly on hard problems. To address this challenge, we propose a simple yet effective strategy via Question Augmentation: introduce partial solutions during training to reduce problem difficulty and provide more informative learning signals. Our method, QuestA, when applied during RL training on math reasoning tasks, not only improves pass@1 but also pass@k-particularly on problems where standard RL struggles to make progress. This enables continual improvement over strong open-source models such as DeepScaleR and OpenMath Nemotron, further enhancing their reasoning capabilities. We achieve new state-of-the-art results on math benchmarks using 1.5B-parameter models: 67.1% (+5.3%) on AIME24, 59.5% (+10.0%) on AIME25, and 35.5% (+4.0%) on HMMT25. Further, we provide theoretical explanations that QuestA improves sample efficiency, offering a practical and generalizable pathway for expanding reasoning capability through RL.
How Far Are We from Optimal Reasoning Efficiency?
Jun 08, 2025Large Reasoning Models (LRMs) demonstrate remarkable problem-solving capabilities through extended Chain-of-Thought (CoT) reasoning but often produce excessively verbose and redundant reasoning traces. This inefficiency incurs high inference costs and limits practical deployment. While existing fine-tuning methods aim to improve reasoning efficiency, assessing their efficiency gains remains challenging due to inconsistent evaluations. In this work, we introduce the reasoning efficiency frontiers, empirical upper bounds derived from fine-tuning base LRMs across diverse approaches and training configurations. Based on these frontiers, we propose the Reasoning Efficiency Gap (REG), a unified metric quantifying deviations of any fine-tuned LRMs from these frontiers. Systematic evaluation on challenging mathematical benchmarks reveals significant gaps in current methods: they either sacrifice accuracy for short length or still remain inefficient under tight token budgets. To reduce the efficiency gap, we propose REO-RL, a class of Reinforcement Learning algorithms that minimizes REG by targeting a sparse set of token budgets. Leveraging numerical integration over strategically selected budgets, REO-RL approximates the full efficiency objective with low error using a small set of token budgets. Through systematic benchmarking, we demonstrate that our efficiency metric, REG, effectively captures the accuracy-length trade-off, with low-REG methods reducing length while maintaining accuracy. Our approach, REO-RL, consistently reduces REG by >=50 across all evaluated LRMs and matching Qwen3-4B/8B efficiency frontiers under a 16K token budget with minimal accuracy loss. Ablation studies confirm the effectiveness of our exponential token budget strategy. Finally, our findings highlight that fine-tuning LRMs to perfectly align with the efficiency frontiers remains an open challenge.