 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Jan 21, 2025


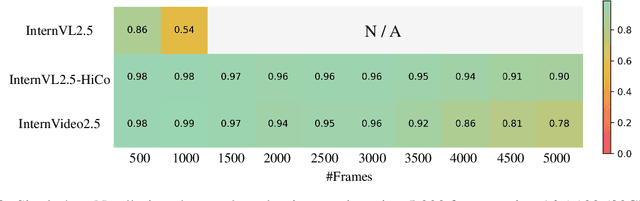
This paper aims to improve the performance of video multimodal large language models (MLLM) via long and rich context (LRC) modeling. As a result, we develop a new version of InternVideo2.5 with a focus on enhancing the original MLLMs' ability to perceive fine-grained details and capture long-form temporal structure in videos. Specifically, our approach incorporates dense vision task annotations into MLLMs using direct preference optimization and develops compact spatiotemporal representations through adaptive hierarchical token compression. Experimental results demonstrate this unique design of LRC greatly improves the results of video MLLM in mainstream video understanding benchmarks (short & long), enabling the MLLM to memorize significantly longer video inputs (at least 6x longer than the original), and master specialized vision capabilities like object tracking and segmentation. Our work highlights the importance of multimodal context richness (length and fineness) in empowering MLLM's innate abilites (focus and memory), providing new insights for future research on video MLLM. Code and models are available at https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5
DiffVSR: Enhancing Real-World Video Super-Resolution with Diffusion Models for Advanced Visual Quality and Temporal Consistency
Jan 17, 2025
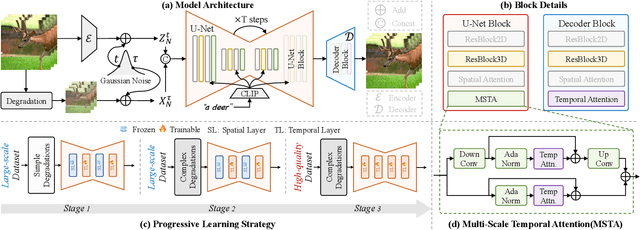
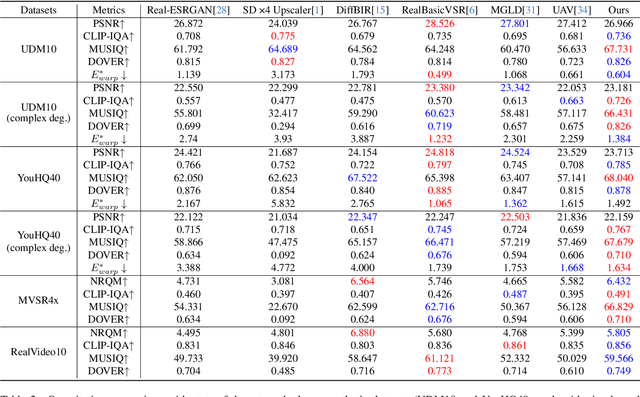
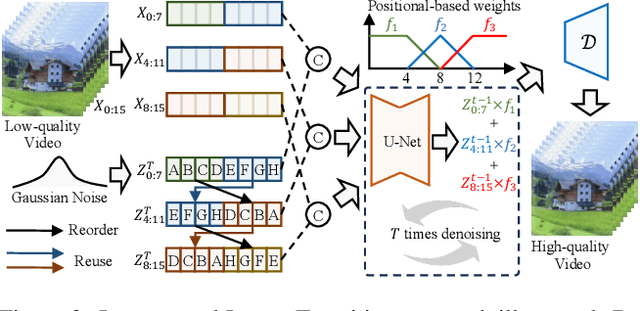
Diffusion models have demonstrated exceptional capabilities in image generation and restoration, yet their application to video super-resolution faces significant challenges in maintaining both high fidelity and temporal consistency. We present DiffVSR, a diffusion-based framework for real-world video super-resolution that effectively addresses these challenges through key innovations. For intra-sequence coherence, we develop a multi-scale temporal attention module and temporal-enhanced VAE decoder that capture fine-grained motion details. To ensure inter-sequence stability, we introduce a noise rescheduling mechanism with an interweaved latent transition approach, which enhances temporal consistency without additional training overhead. We propose a progressive learning strategy that transitions from simple to complex degradations, enabling robust optimization despite limited high-quality video data. Extensive experiments demonstrate that DiffVSR delivers superior results in both visual quality and temporal consistency, setting a new performance standard in real-world video super-resolution.
MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning
Jan 16, 2025



Video causal reasoning aims to achieve a high-level understanding of videos from a causal perspective. However, it exhibits limitations in its scope, primarily executed in a question-answering paradigm and focusing on brief video segments containing isolated events and basic causal relations, lacking comprehensive and structured causality analysis for videos with multiple interconnected events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relations between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD identifies the causal associations between these events to derive a comprehensive and structured event-level video causal graph explaining why and how the result event occurred. To address the challenges of MECD, we devise a novel framework inspired by the Granger Causality method, incorporating an efficient mask-based event prediction model to perform an Event Granger Test. It estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to mitigate challenges in MECD like causality confounding and illusory causality. Additionally, context chain reasoning is introduced to conduct more robust and generalized reasoning. Experiments validate the effectiveness of our framework in reasoning complete causal relations, outperforming GPT-4o and VideoChat2 by 5.77% and 2.70%, respectively. Further experiments demonstrate that causal relation graphs can also contribute to downstream video understanding tasks such as video question answering and video event prediction.
Vchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Jan 14, 2025



We present Vchitect-2.0, a parallel transformer architecture designed to scale up video diffusion models for large-scale text-to-video generation. The overall Vchitect-2.0 system has several key designs. (1) By introducing a novel Multimodal Diffusion Block, our approach achieves consistent alignment between text descriptions and generated video frames, while maintaining temporal coherence across sequences. (2) To overcome memory and computational bottlenecks, we propose a Memory-efficient Training framework that incorporates hybrid parallelism and other memory reduction techniques, enabling efficient training of long video sequences on distributed systems. (3) Additionally, our enhanced data processing pipeline ensures the creation of Vchitect T2V DataVerse, a high-quality million-scale training dataset through rigorous annotation and aesthetic evaluation. Extensive benchmarking demonstrates that Vchitect-2.0 outperforms existing methods in video quality, training efficiency, and scalability, serving as a suitable base for high-fidelity video generation.
SELMA3D challenge: Self-supervised learning for 3D light-sheet microscopy image segmentation
Jan 07, 2025Recent innovations in light sheet microscopy, paired with developments in tissue clearing techniques, enable the 3D imaging of large mammalian tissues with cellular resolution. Combined with the progress in large-scale data analysis, driven by deep learning, these innovations empower researchers to rapidly investigate the morphological and functional properties of diverse biological samples. Segmentation, a crucial preliminary step in the analysis process, can be automated using domain-specific deep learning models with expert-level performance. However, these models exhibit high sensitivity to domain shifts, leading to a significant drop in accuracy when applied to data outside their training distribution. To address this limitation, and inspired by the recent success of self-supervised learning in training generalizable models, we organized the SELMA3D Challenge during the MICCAI 2024 conference. SELMA3D provides a vast collection of light-sheet images from cleared mice and human brains, comprising 35 large 3D images-each with over 1000^3 voxels-and 315 annotated small patches for finetuning, preliminary testing and final testing. The dataset encompasses diverse biological structures, including vessel-like and spot-like structures. Five teams participated in all phases of the challenge, and their proposed methods are reviewed in this paper. Quantitative and qualitative results from most participating teams demonstrate that self-supervised learning on large datasets improves segmentation model performance and generalization. We will continue to support and extend SELMA3D as an inaugural MICCAI challenge focused on self-supervised learning for 3D microscopy image segmentation.
Stochastically Constrained Best Arm Identification with Thompson Sampling
Jan 07, 2025We consider the problem of the best arm identification in the presence of stochastic constraints, where there is a finite number of arms associated with multiple performance measures. The goal is to identify the arm that optimizes the objective measure subject to constraints on the remaining measures. We will explore the popular idea of Thompson sampling (TS) as a means to solve it. To the best of our knowledge, it is the first attempt to extend TS to this problem. We will design a TS-based sampling algorithm, establish its asymptotic optimality in the rate of posterior convergence, and demonstrate its superior performance using numerical examples.
Salient Region Matching for Fully Automated MR-TRUS Registration
Jan 07, 2025Prostate cancer is a leading cause of cancer-related mortality in men. The registration of magnetic resonance (MR) and transrectal ultrasound (TRUS) can provide guidance for the targeted biopsy of prostate cancer. In this study, we propose a salient region matching framework for fully automated MR-TRUS registration. The framework consists of prostate segmentation, rigid alignment and deformable registration. Prostate segmentation is performed using two segmentation networks on MR and TRUS respectively, and the predicted salient regions are used for the rigid alignment. The rigidly-aligned MR and TRUS images serve as initialization for the deformable registration. The deformable registration network has a dual-stream encoder with cross-modal spatial attention modules to facilitate multi-modality feature learning, and a salient region matching loss to consider both structure and intensity similarity within the prostate region. Experiments on a public MR-TRUS dataset demonstrate that our method achieves satisfactory registration results, outperforming several cutting-edge methods. The code is publicly available at https://github.com/mock1ngbrd/salient-region-matching.
Interpretable Load Forecasting via Representation Learning of Geo-distributed Meteorological Factors
Jan 04, 2025



Meteorological factors (MF) are crucial in day-ahead load forecasting as they significantly influence the electricity consumption behaviors of consumers. Numerous studies have incorporated MF into the load forecasting model to achieve higher accuracy. Selecting MF from one representative location or the averaged MF as the inputs of the forecasting model is a common practice. However, the difference in MF collected in various locations within a region may be significant, which poses a challenge in selecting the appropriate MF from numerous locations. A representation learning framework is proposed to extract geo-distributed MF while considering their spatial relationships. In addition, this paper employs the Shapley value in the graph-based model to reveal connections between MF collected in different locations and loads. To reduce the computational complexity of calculating the Shapley value, an acceleration method is adopted based on Monte Carlo sampling and weighted linear regression. Experiments on two real-world datasets demonstrate that the proposed method improves the day-ahead forecasting accuracy, especially in extreme scenarios such as the "accumulation temperature effect" in summer and "sudden temperature change" in winter. We also find a significant correlation between the importance of MF in different locations and the corresponding area's GDP and mainstay industry.
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Dec 31, 2024



Long-context modeling is a critical capability for multimodal large language models (MLLMs), enabling them to process long-form contents with implicit memorization. Despite its advances, handling extremely long videos remains challenging due to the difficulty in maintaining crucial features over extended sequences. This paper introduces a Hierarchical visual token Compression (HiCo) method designed for high-fidelity representation and a practical context modeling system VideoChat-Flash tailored for multimodal long-sequence processing. HiCo capitalizes on the redundancy of visual information in long videos to compress long video context from the clip-level to the video-level, reducing the compute significantly while preserving essential details. VideoChat-Flash features a multi-stage short-to-long learning scheme, a rich dataset of real-world long videos named LongVid, and an upgraded "Needle-In-A-video-Haystack" (NIAH) for evaluating context capacities. In extensive experiments, VideoChat-Flash shows the leading performance on both mainstream long and short video benchmarks at the 7B model scale. It firstly gets 99.1% accuracy over 10,000 frames in NIAH among open-source models.
Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment
Dec 26, 2024Current multimodal large language models (MLLMs) struggle with fine-grained or precise understanding of visuals though they give comprehensive perception and reasoning in a spectrum of vision applications. Recent studies either develop tool-using or unify specific visual tasks into the autoregressive framework, often at the expense of overall multimodal performance. To address this issue and enhance MLLMs with visual tasks in a scalable fashion, we propose Task Preference Optimization (TPO), a novel method that utilizes differentiable task preferences derived from typical fine-grained visual tasks. TPO introduces learnable task tokens that establish connections between multiple task-specific heads and the MLLM. By leveraging rich visual labels during training, TPO significantly enhances the MLLM's multimodal capabilities and task-specific performance. Through multi-task co-training within TPO, we observe synergistic benefits that elevate individual task performance beyond what is achievable through single-task training methodologies. Our instantiation of this approach with VideoChat and LLaVA demonstrates an overall 14.6% improvement in multimodal performance compared to baseline models. Additionally, MLLM-TPO demonstrates robust zero-shot capabilities across various tasks, performing comparably to state-of-the-art supervised models. The code will be released at https://github.com/OpenGVLab/TPO