 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnGAP: Uncertainty-Guided Affine Prompting for Real-Time Crack Segmentation
May 04, 2026Real-time crack segmentation is vital for structural health monitoring but is plagued by aleatoric uncertainties arising from varying lighting, blur, and texture ambiguity. Current uncertainty-aware approaches typically treat uncertainty estimation as a passive endpoint for post-hoc analysis, failing to close the loop by feeding this information back to refine feature representations. We contend that independent pixel-wise heteroscedastic modeling is uniquely suited for crack segmentation, as cracks are defined by fine-grained local gradients rather than the global semantic coherence relied upon in general object segmentation. However, this approach suffers from a structural optimization pathology: high predicted variance attenuates loss gradients, effectively causing the model to ignore difficult samples and under-fit complex boundaries. To address these challenges, we propose UnGAP, a novel framework that establishes a closed-loop mechanism between uncertainty estimation and feature learning. Central to our approach is the Uncertainty-Prompted Feature Modulator (UPFM), which treats aleatoric uncertainty as an active visual prompt rather than a mere output. UPFM dynamically calibrates feature distributions through pixel-wise affine transformations. Crucially, this mechanism mitigates the heteroscedastic pathology by transforming high variance, which would otherwise indicate gradient suppression, into a constructive signal for stronger feature rectification in ambiguous regions. Additionally, a boundary-aware detection head is introduced to further constrain prediction precision. Extensive experiments demonstrate that UnGAP balances superior segmentation accuracy with real-time inference speed, effectively validating the benefit of transforming uncertainty from a passive metric into an active calibration tool.
MECD+: Unlocking Event-Level Causal Graph Discovery for Video Reasoning
Jan 16, 2025



Video causal reasoning aims to achieve a high-level understanding of videos from a causal perspective. However, it exhibits limitations in its scope, primarily executed in a question-answering paradigm and focusing on brief video segments containing isolated events and basic causal relations, lacking comprehensive and structured causality analysis for videos with multiple interconnected events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relations between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD identifies the causal associations between these events to derive a comprehensive and structured event-level video causal graph explaining why and how the result event occurred. To address the challenges of MECD, we devise a novel framework inspired by the Granger Causality method, incorporating an efficient mask-based event prediction model to perform an Event Granger Test. It estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to mitigate challenges in MECD like causality confounding and illusory causality. Additionally, context chain reasoning is introduced to conduct more robust and generalized reasoning. Experiments validate the effectiveness of our framework in reasoning complete causal relations, outperforming GPT-4o and VideoChat2 by 5.77% and 2.70%, respectively. Further experiments demonstrate that causal relation graphs can also contribute to downstream video understanding tasks such as video question answering and video event prediction.
Variational Pedestrian Detection
Apr 26, 2021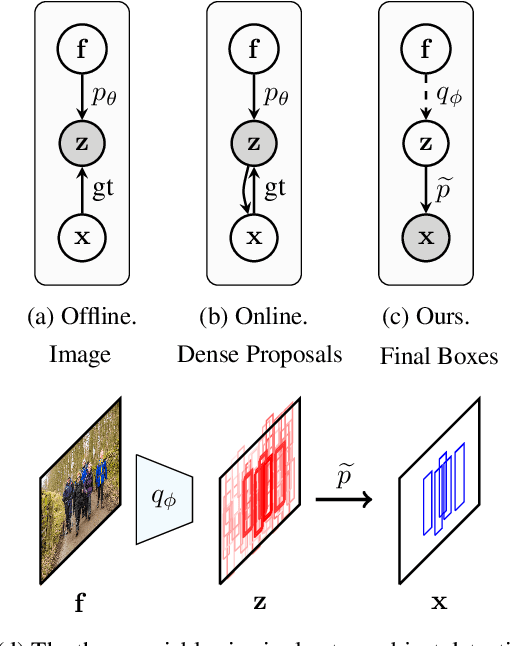
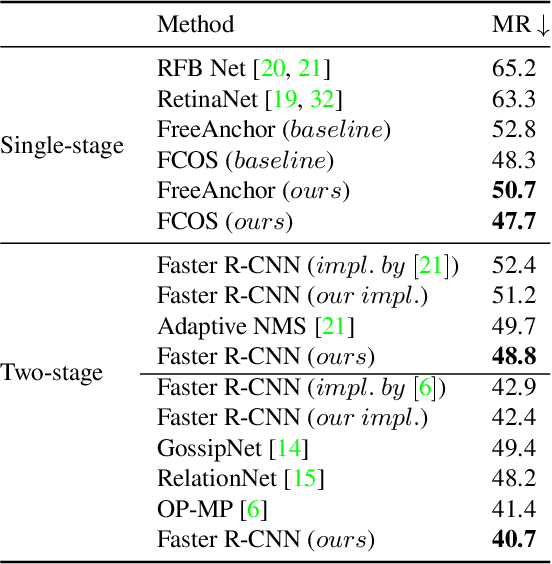
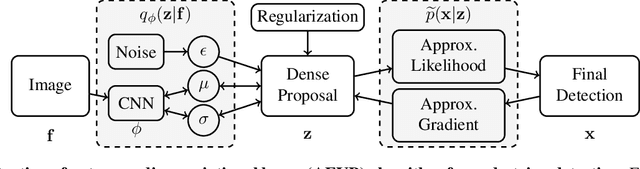
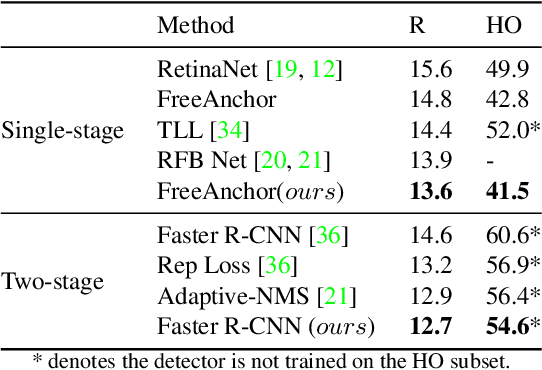
Pedestrian detection in a crowd is a challenging task due to a high number of mutually-occluding human instances, which brings ambiguity and optimization difficulties to the current IoU-based ground truth assignment procedure in classical object detection methods. In this paper, we develop a unique perspective of pedestrian detection as a variational inference problem. We formulate a novel and efficient algorithm for pedestrian detection by modeling the dense proposals as a latent variable while proposing a customized Auto Encoding Variational Bayes (AEVB) algorithm. Through the optimization of our proposed algorithm, a classical detector can be fashioned into a variational pedestrian detector. Experiments conducted on CrowdHuman and CityPersons datasets show that the proposed algorithm serves as an efficient solution to handle the dense pedestrian detection problem for the case of single-stage detectors. Our method can also be flexibly applied to two-stage detectors, achieving notable performance enhancement.