 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Mode Collapse in GANs via Manifold Entropy Estimation
Aug 25, 2022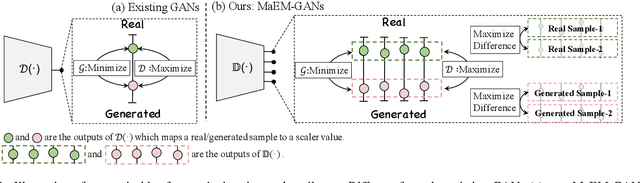
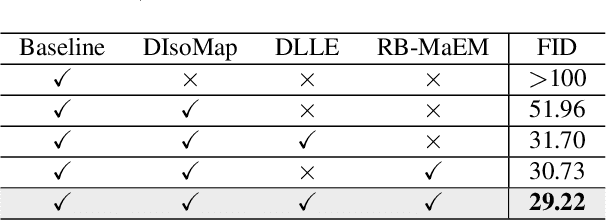
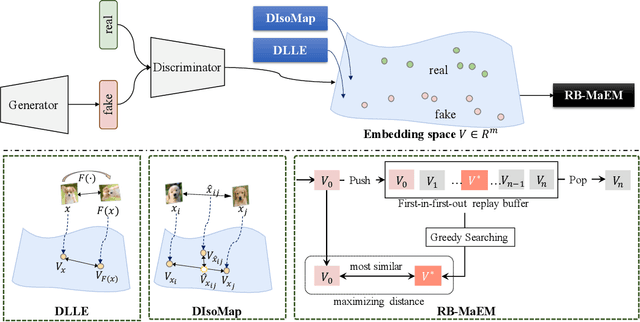
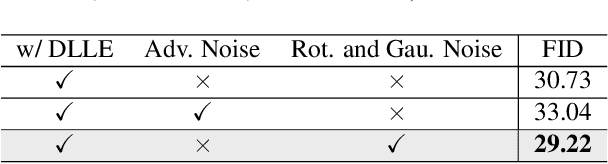
Generative Adversarial Networks (GANs) have shown compelling results in various tasks and applications in recent years. However, mode collapse remains a critical problem in GANs. In this paper, we propose a novel training pipeline to address the mode collapse issue of GANs. Different from existing methods, we propose to generalize the discriminator as feature embedding, and maximize the entropy of distributions in the embedding space learned by the discriminator. Specifically, two regularization terms, i.e.Deep Local Linear Embedding (DLLE) and Deep Isometric feature Mapping (DIsoMap), are designed to encourage the discriminator to learn the structural information embedded in the data, such that the embedding space learned by the discriminator can be well formed. Based on the well-learned embedding space supported by the discriminator, a non-parametric entropy estimator is designed to efficiently maximize the entropy of embedding vectors, playing as an approximation of maximizing the entropy of the generated distribution. Through improving the discriminator and maximizing the distance of the most similar samples in the embedding space, our pipeline effectively reduces the mode collapse without sacrificing the quality of generated samples. Extensive experimental results show the effectiveness of our method which outperforms the GAN baseline, MaF-GAN on CelebA (9.13 vs. 12.43 in FID) and surpasses the recent state-of-the-art energy-based model on the ANIME-FACE dataset (2.80 vs. 2.26 in Inception score).
Dense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation
Jul 18, 2022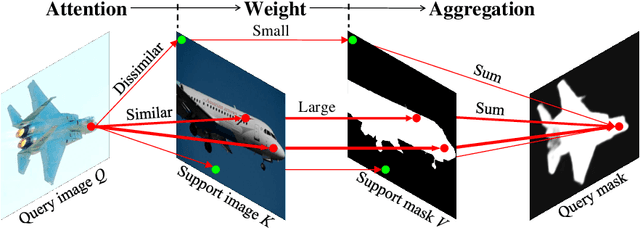
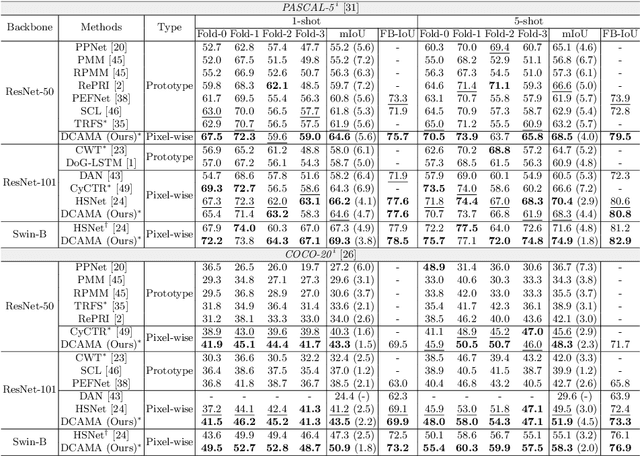
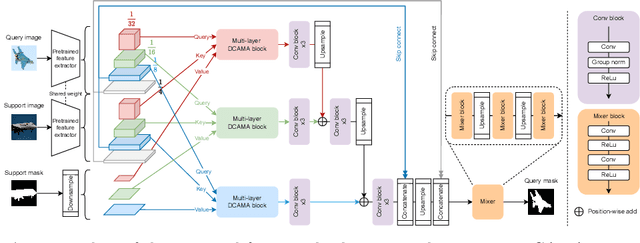
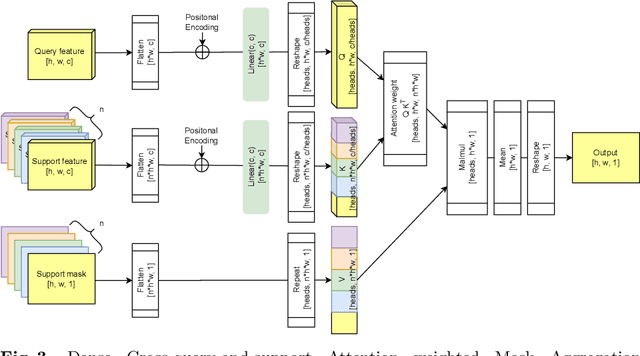
Research into Few-shot Semantic Segmentation (FSS) has attracted great attention, with the goal to segment target objects in a query image given only a few annotated support images of the target class. A key to this challenging task is to fully utilize the information in the support images by exploiting fine-grained correlations between the query and support images. However, most existing approaches either compressed the support information into a few class-wise prototypes, or used partial support information (e.g., only foreground) at the pixel level, causing non-negligible information loss. In this paper, we propose Dense pixel-wise Cross-query-and-support Attention weighted Mask Aggregation (DCAMA), where both foreground and background support information are fully exploited via multi-level pixel-wise correlations between paired query and support features. Implemented with the scaled dot-product attention in the Transformer architecture, DCAMA treats every query pixel as a token, computes its similarities with all support pixels, and predicts its segmentation label as an additive aggregation of all the support pixels' labels -- weighted by the similarities. Based on the unique formulation of DCAMA, we further propose efficient and effective one-pass inference for n-shot segmentation, where pixels of all support images are collected for the mask aggregation at once. Experiments show that our DCAMA significantly advances the state of the art on standard FSS benchmarks of PASCAL-5i, COCO-20i, and FSS-1000, e.g., with 3.1%, 9.7%, and 3.6% absolute improvements in 1-shot mIoU over previous best records. Ablative studies also verify the design DCAMA.
Deformer: Towards Displacement Field Learning for Unsupervised Medical Image Registration
Jul 07, 2022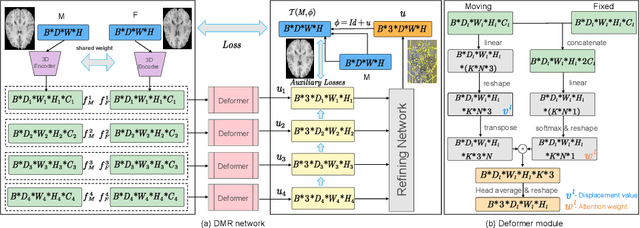
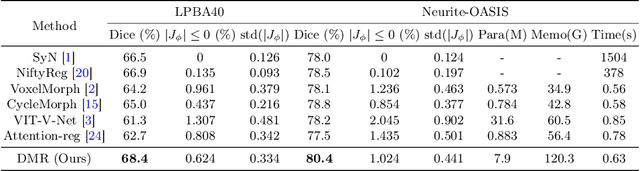
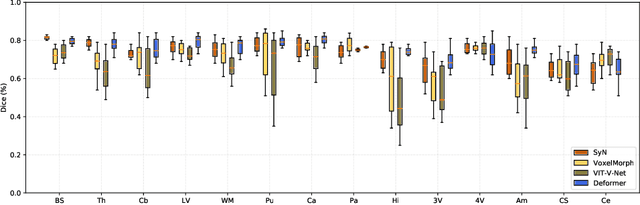
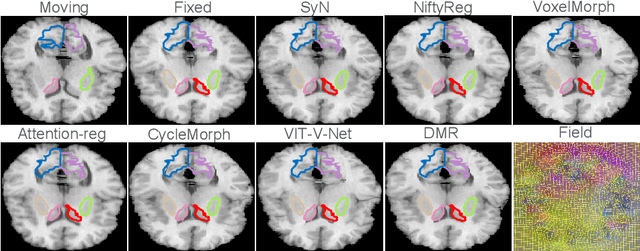
Recently, deep-learning-based approaches have been widely studied for deformable image registration task. However, most efforts directly map the composite image representation to spatial transformation through the convolutional neural network, ignoring its limited ability to capture spatial correspondence. On the other hand, Transformer can better characterize the spatial relationship with attention mechanism, its long-range dependency may be harmful to the registration task, where voxels with too large distances are unlikely to be corresponding pairs. In this study, we propose a novel Deformer module along with a multi-scale framework for the deformable image registration task. The Deformer module is designed to facilitate the mapping from image representation to spatial transformation by formulating the displacement vector prediction as the weighted summation of several bases. With the multi-scale framework to predict the displacement fields in a coarse-to-fine manner, superior performance can be achieved compared with traditional and learning-based approaches. Comprehensive experiments on two public datasets are conducted to demonstrate the effectiveness of the proposed Deformer module as well as the multi-scale framework.
mmFormer: Multimodal Medical Transformer for Incomplete Multimodal Learning of Brain Tumor Segmentation
Jun 06, 2022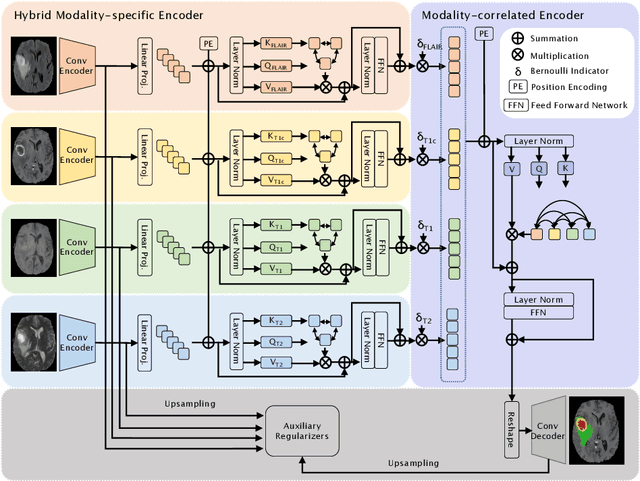
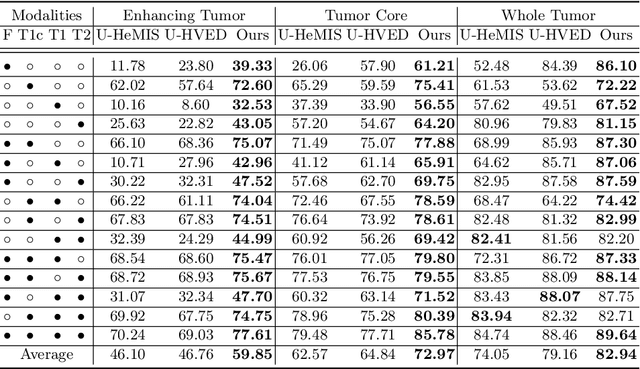

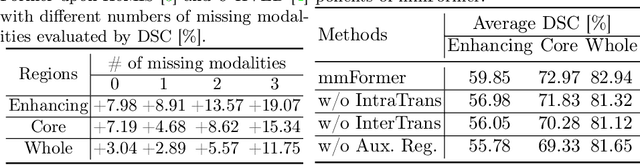
Accurate brain tumor segmentation from Magnetic Resonance Imaging (MRI) is desirable to joint learning of multimodal images. However, in clinical practice, it is not always possible to acquire a complete set of MRIs, and the problem of missing modalities causes severe performance degradation in existing multimodal segmentation methods. In this work, we present the first attempt to exploit the Transformer for multimodal brain tumor segmentation that is robust to any combinatorial subset of available modalities. Concretely, we propose a novel multimodal Medical Transformer (mmFormer) for incomplete multimodal learning with three main components: the hybrid modality-specific encoders that bridge a convolutional encoder and an intra-modal Transformer for both local and global context modeling within each modality; an inter-modal Transformer to build and align the long-range correlations across modalities for modality-invariant features with global semantics corresponding to tumor region; a decoder that performs a progressive up-sampling and fusion with the modality-invariant features to generate robust segmentation. Besides, auxiliary regularizers are introduced in both encoder and decoder to further enhance the model's robustness to incomplete modalities. We conduct extensive experiments on the public BraTS $2018$ dataset for brain tumor segmentation. The results demonstrate that the proposed mmFormer outperforms the state-of-the-art methods for incomplete multimodal brain tumor segmentation on almost all subsets of incomplete modalities, especially by an average 19.07% improvement of Dice on tumor segmentation with only one available modality. The code is available at https://github.com/YaoZhang93/mmFormer.
Adaptive Convolutional Dictionary Network for CT Metal Artifact Reduction
May 16, 2022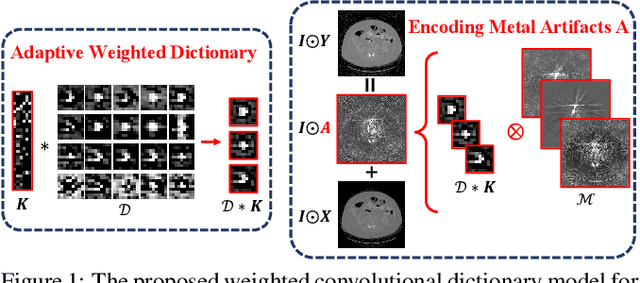
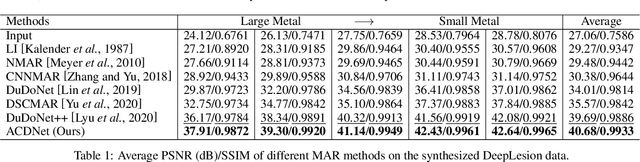
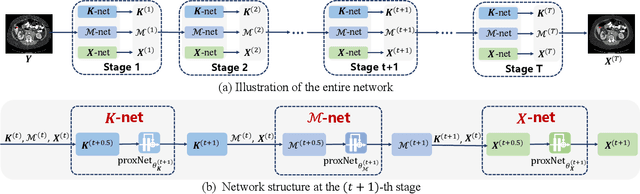

Inspired by the great success of deep neural networks, learning-based methods have gained promising performances for metal artifact reduction (MAR) in computed tomography (CT) images. However, most of the existing approaches put less emphasis on modelling and embedding the intrinsic prior knowledge underlying this specific MAR task into their network designs. Against this issue, we propose an adaptive convolutional dictionary network (ACDNet), which leverages both model-based and learning-based methods. Specifically, we explore the prior structures of metal artifacts, e.g., non-local repetitive streaking patterns, and encode them as an explicit weighted convolutional dictionary model. Then, a simple-yet-effective algorithm is carefully designed to solve the model. By unfolding every iterative substep of the proposed algorithm into a network module, we explicitly embed the prior structure into a deep network, \emph{i.e.,} a clear interpretability for the MAR task. Furthermore, our ACDNet can automatically learn the prior for artifact-free CT images via training data and adaptively adjust the representation kernels for each input CT image based on its content. Hence, our method inherits the clear interpretability of model-based methods and maintains the powerful representation ability of learning-based methods. Comprehensive experiments executed on synthetic and clinical datasets show the superiority of our ACDNet in terms of effectiveness and model generalization. {\color{blue}{{\textit{Code is available at {\url{https://github.com/hongwang01/ACDNet}}.}}}}
* https://github.com/hongwang01/ACDNet
Robust Representation via Dynamic Feature Aggregation
May 16, 2022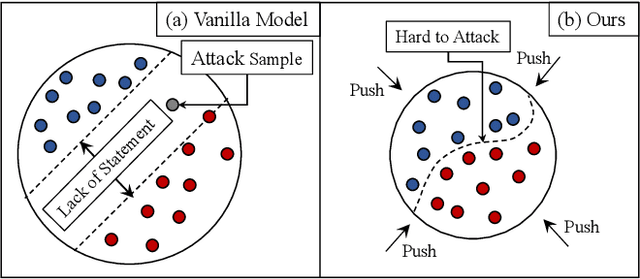
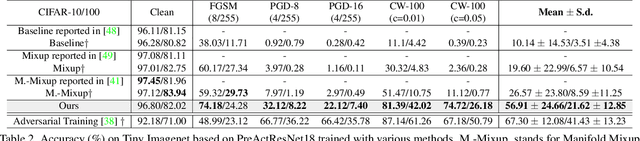
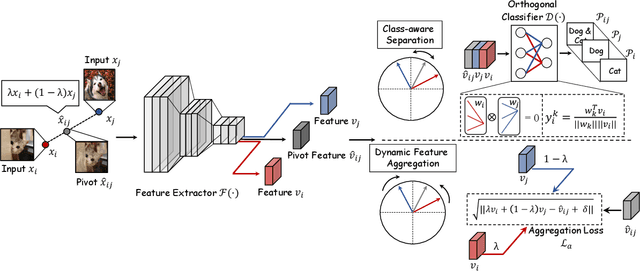
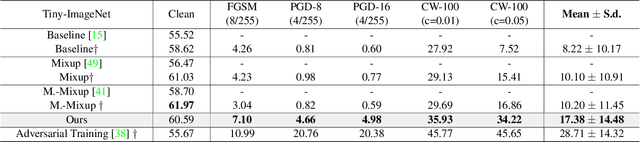
Deep convolutional neural network (CNN) based models are vulnerable to the adversarial attacks. One of the possible reasons is that the embedding space of CNN based model is sparse, resulting in a large space for the generation of adversarial samples. In this study, we propose a method, denoted as Dynamic Feature Aggregation, to compress the embedding space with a novel regularization. Particularly, the convex combination between two samples are regarded as the pivot for aggregation. In the embedding space, the selected samples are guided to be similar to the representation of the pivot. On the other side, to mitigate the trivial solution of such regularization, the last fully-connected layer of the model is replaced by an orthogonal classifier, in which the embedding codes for different classes are processed orthogonally and separately. With the regularization and orthogonal classifier, a more compact embedding space can be obtained, which accordingly improves the model robustness against adversarial attacks. An averaging accuracy of 56.91% is achieved by our method on CIFAR-10 against various attack methods, which significantly surpasses a solid baseline (Mixup) by a margin of 37.31%. More surprisingly, empirical results show that, the proposed method can also achieve the state-of-the-art performance for out-of-distribution (OOD) detection, due to the learned compact feature space. An F1 score of 0.937 is achieved by the proposed method, when adopting CIFAR-10 as in-distribution (ID) dataset and LSUN as OOD dataset. Code is available at https://github.com/HaozheLiu-ST/DynamicFeatureAggregation.
"My nose is running.""Are you also coughing?": Building A Medical Diagnosis Agent with Interpretable Inquiry Logics
May 02, 2022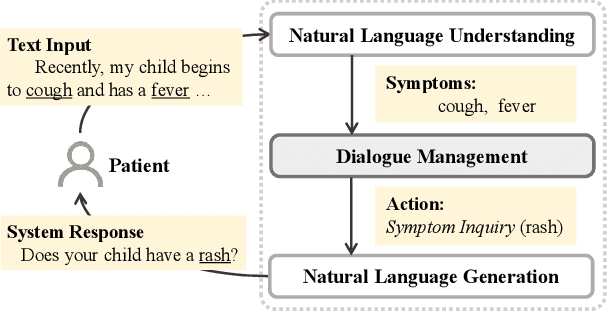
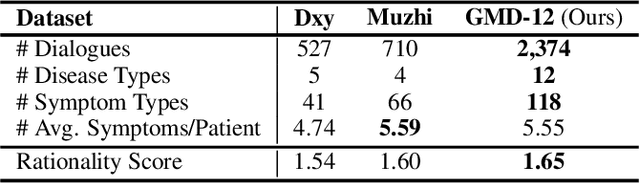
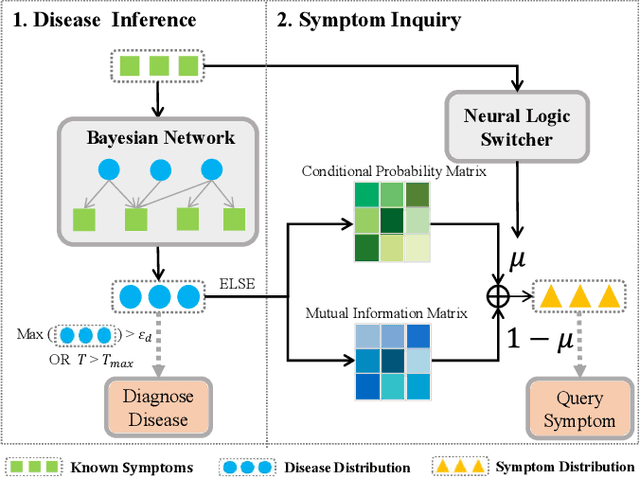
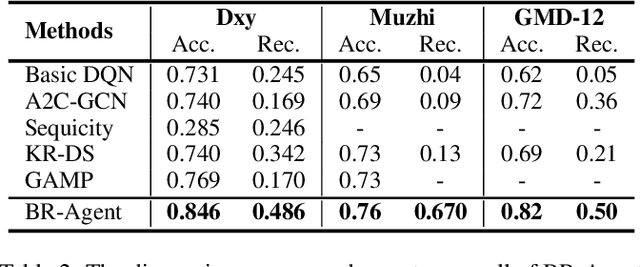
With the rise of telemedicine, the task of developing Dialogue Systems for Medical Diagnosis (DSMD) has received much attention in recent years. Different from early researches that needed to rely on extra human resources and expertise to help construct the system, recent researches focused on how to build DSMD in a purely data-driven manner. However, the previous data-driven DSMD methods largely overlooked the system interpretability, which is critical for a medical application, and they also suffered from the data sparsity issue at the same time. In this paper, we explore how to bring interpretability to data-driven DSMD. Specifically, we propose a more interpretable decision process to implement the dialogue manager of DSMD by reasonably mimicking real doctors' inquiry logics, and we devise a model with highly transparent components to conduct the inference. Moreover, we collect a new DSMD dataset, which has a much larger scale, more diverse patterns and is of higher quality than the existing ones. The experiments show that our method obtains 7.7%, 10.0%, 3.0% absolute improvement in diagnosis accuracy respectively on three datasets, demonstrating the effectiveness of its rational decision process and model design. Our codes and the GMD-12 dataset are available at https://github.com/lwgkzl/BR-Agent.
Learning Shape Priors by Pairwise Comparison for Robust Semantic Segmentation
Apr 23, 2022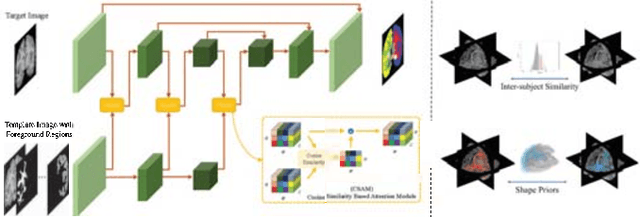
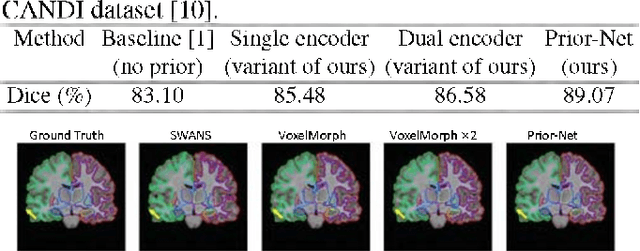
Semantic segmentation is important in medical image analysis. Inspired by the strong ability of traditional image analysis techniques in capturing shape priors and inter-subject similarity, many deep learning (DL) models have been recently proposed to exploit such prior information and achieved robust performance. However, these two types of important prior information are usually studied separately in existing models. In this paper, we propose a novel DL model to model both type of priors within a single framework. Specifically, we introduce an extra encoder into the classic encoder-decoder structure to form a Siamese structure for the encoders, where one of them takes a target image as input (the image-encoder), and the other concatenates a template image and its foreground regions as input (the template-encoder). The template-encoder encodes the shape priors and appearance characteristics of each foreground class in the template image. A cosine similarity based attention module is proposed to fuse the information from both encoders, to utilize both types of prior information encoded by the template-encoder and model the inter-subject similarity for each foreground class. Extensive experiments on two public datasets demonstrate that our proposed method can produce superior performance to competing methods.
DFTR: Depth-supervised Fusion Transformer for Salient Object Detection
Apr 11, 2022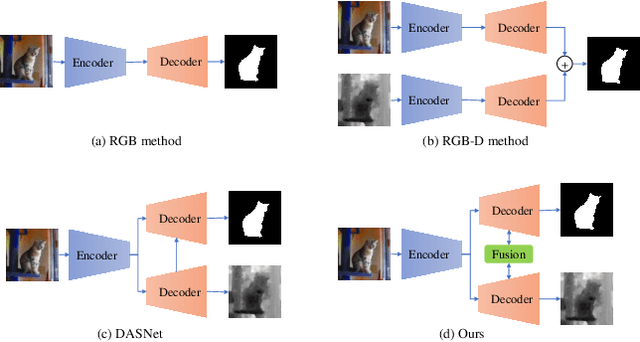
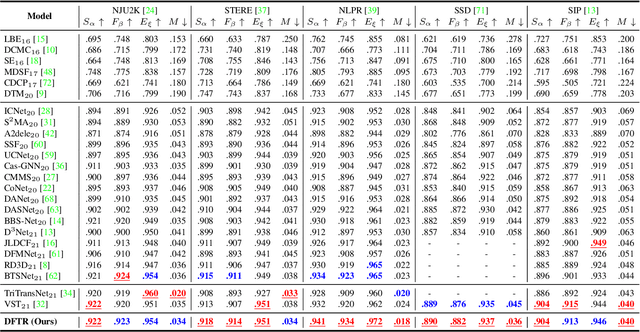
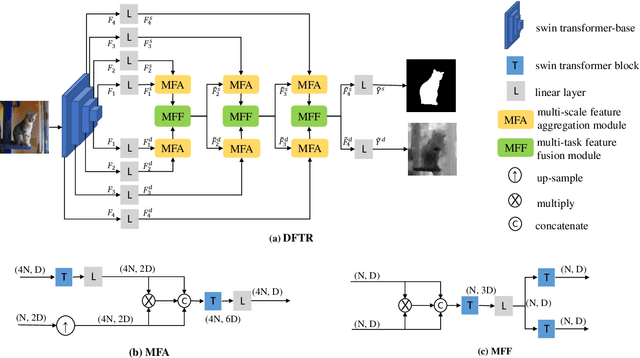
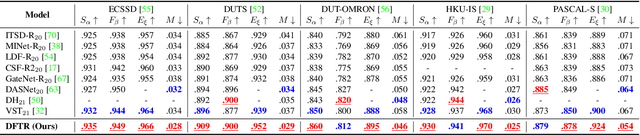
Automated salient object detection (SOD) plays an increasingly crucial role in many computer vision applications. By reformulating the depth information as supervision rather than as input, depth-supervised convolutional neural networks (CNN) have achieved promising results on both RGB and RGB-D SOD scenarios with the merits of no requirements for extra depth networks and depth inputs in the inference stage. This paper, for the first time, seeks to expand the applicability of depth supervision to the Transformer architecture. Specifically, we develop a Depth-supervised Fusion TRansformer (DFTR), to further improve the accuracy of both RGB and RGB-D SOD. The proposed DFTR involves three primary features: 1) DFTR, to the best of our knowledge, is the first pure Transformer-based model for depth-supervised SOD; 2) A multi-scale feature aggregation (MFA) module is proposed to fully exploit the multi-scale features encoded by the Swin Transformer in a coarse-to-fine manner; 3) To enable bidirectional information flow across different streams of features, a novel multi-stage feature fusion (MFF) module is further integrated into our DFTR with the emphasis on salient regions at different network learning stages. We extensively evaluate the proposed DFTR on ten benchmarking datasets. Experimental results show that our DFTR consistently outperforms the existing state-of-the-art methods for both RGB and RGB-D SOD tasks. The code and model will be made publicly available.
Domain Adaptation Meets Zero-Shot Learning: An Annotation-Efficient Approach to Multi-Modality Medical Image Segmentation
Mar 19, 2022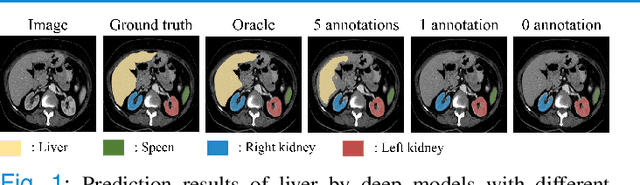
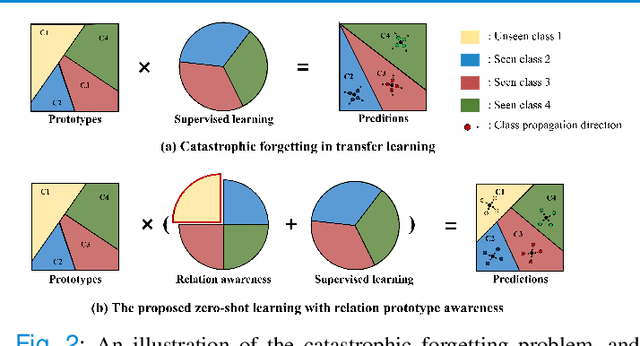
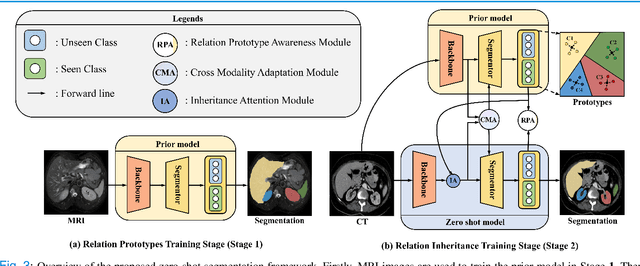
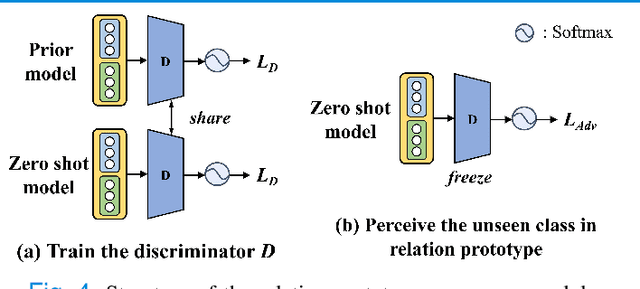
Due to the lack of properly annotated medical data, exploring the generalization capability of the deep model is becoming a public concern. Zero-shot learning (ZSL) has emerged in recent years to equip the deep model with the ability to recognize unseen classes. However, existing studies mainly focus on natural images, which utilize linguistic models to extract auxiliary information for ZSL. It is impractical to apply the natural image ZSL solutions directly to medical images, since the medical terminology is very domain-specific, and it is not easy to acquire linguistic models for the medical terminology. In this work, we propose a new paradigm of ZSL specifically for medical images utilizing cross-modality information. We make three main contributions with the proposed paradigm. First, we extract the prior knowledge about the segmentation targets, called relation prototypes, from the prior model and then propose a cross-modality adaptation module to inherit the prototypes to the zero-shot model. Second, we propose a relation prototype awareness module to make the zero-shot model aware of information contained in the prototypes. Last but not least, we develop an inheritance attention module to recalibrate the relation prototypes to enhance the inheritance process. The proposed framework is evaluated on two public cross-modality datasets including a cardiac dataset and an abdominal dataset. Extensive experiments show that the proposed framework significantly outperforms the state of the arts.