 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposable Visual Tokenizers with Generator-Free Diagnostics of Learnability
Feb 03, 2026We introduce CompTok, a training framework for learning visual tokenizers whose tokens are enhanced for compositionality. CompTok uses a token-conditioned diffusion decoder. By employing an InfoGAN-style objective, where we train a recognition model to predict the tokens used to condition the diffusion decoder using the decoded images, we enforce the decoder to not ignore any of the tokens. To promote compositional control, besides the original images, CompTok also trains on tokens formed by swapping token subsets between images, enabling more compositional control of the token over the decoder. As the swapped tokens between images do not have ground truth image targets, we apply a manifold constraint via an adversarial flow regularizer to keep unpaired swap generations on the natural-image distribution. The resulting tokenizer not only achieves state-of-the-art performance on image class-conditioned generation, but also demonstrates properties such as swapping tokens between images to achieve high level semantic editing of an image. Additionally, we propose two metrics that measures the landscape of the token space that can be useful to describe not only the compositionality of the tokens, but also how easy to learn the landscape is for a generator to be trained on this space. We show in experiments that CompTok can improve on both of the metrics as well as supporting state-of-the-art generators for class conditioned generation.
Comparative Study of Large Language Models on Chinese Film Script Continuation: An Empirical Analysis Based on GPT-5.2 and Qwen-Max
Jan 21, 2026As large language models (LLMs) are increasingly applied to creative writing, their performance on culturally specific narrative tasks warrants systematic investigation. This study constructs the first Chinese film script continuation benchmark comprising 53 classic films, and designs a multi-dimensional evaluation framework comparing GPT-5.2 and Qwen-Max-Latest. Using a "first half to second half" continuation paradigm with 3 samples per film, we obtained 303 valid samples (GPT-5.2: 157, 98.7% validity; Qwen-Max: 146, 91.8% validity). Evaluation integrates ROUGE-L, Structural Similarity, and LLM-as-Judge scoring (DeepSeek-Reasoner). Statistical analysis of 144 paired samples reveals: Qwen-Max achieves marginally higher ROUGE-L (0.2230 vs 0.2114, d=-0.43); however, GPT-5.2 significantly outperforms in structural preservation (0.93 vs 0.75, d=0.46), overall quality (44.79 vs 25.72, d=1.04), and composite scores (0.50 vs 0.39, d=0.84). The overall quality effect size reaches large effect level (d>0.8). GPT-5.2 excels in character consistency, tone-style matching, and format preservation, while Qwen-Max shows deficiencies in generation stability. This study provides a reproducible framework for LLM evaluation in Chinese creative writing.
Unlocking Large Audio-Language Models for Interactive Language Learning
Jan 21, 2026Achieving pronunciation proficiency in a second language (L2) remains a challenge, despite the development of Computer-Assisted Pronunciation Training (CAPT) systems. Traditional CAPT systems often provide unintuitive feedback that lacks actionable guidance, limiting its effectiveness. Recent advancements in audio-language models (ALMs) offer the potential to enhance these systems by providing more user-friendly feedback. In this work, we investigate ALMs for chat-based pronunciation training by introducing L2-Arctic-plus, an English dataset with detailed error explanations and actionable suggestions for improvement. We benchmark cascaded ASR+LLMs and existing ALMs on this dataset, specifically in detecting mispronunciation and generating actionable feedback. To improve the performance, we further propose to instruction-tune ALMs on L2-Arctic-plus. Experimental results demonstrate that our instruction-tuned models significantly outperform existing baselines on mispronunciation detection and suggestion generation in terms of both objective and human evaluation, highlighting the value of the proposed dataset.
Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
Jan 19, 2026We introduce Being-H0.5, a foundational Vision-Language-Action (VLA) model designed for robust cross-embodiment generalization across diverse robotic platforms. While existing VLAs often struggle with morphological heterogeneity and data scarcity, we propose a human-centric learning paradigm that treats human interaction traces as a universal "mother tongue" for physical interaction. To support this, we present UniHand-2.0, the largest embodied pre-training recipe to date, comprising over 35,000 hours of multimodal data across 30 distinct robotic embodiments. Our approach introduces a Unified Action Space that maps heterogeneous robot controls into semantically aligned slots, enabling low-resource robots to bootstrap skills from human data and high-resource platforms. Built upon this human-centric foundation, we design a unified sequential modeling and multi-task pre-training paradigm to bridge human demonstrations and robotic execution. Architecturally, Being-H0.5 utilizes a Mixture-of-Transformers design featuring a novel Mixture-of-Flow (MoF) framework to decouple shared motor primitives from specialized embodiment-specific experts. Finally, to make cross-embodiment policies stable in the real world, we introduce Manifold-Preserving Gating for robustness under sensory shift and Universal Async Chunking to universalize chunked control across embodiments with different latency and control profiles. We empirically demonstrate that Being-H0.5 achieves state-of-the-art results on simulated benchmarks, such as LIBERO (98.9%) and RoboCasa (53.9%), while also exhibiting strong cross-embodiment capabilities on five robotic platforms.
Role-Playing Agents Driven by Large Language Models: Current Status, Challenges, and Future Trends
Jan 15, 2026In recent years, with the rapid advancement of large language models (LLMs), role-playing language agents (RPLAs) have emerged as a prominent research focus at the intersection of natural language processing (NLP) and human-computer interaction. This paper systematically reviews the current development and key technologies of RPLAs, delineating the technological evolution from early rule-based template paradigms, through the language style imitation stage, to the cognitive simulation stage centered on personality modeling and memory mechanisms. It summarizes the critical technical pathways supporting high-quality role-playing, including psychological scale-driven character modeling, memory-augmented prompting mechanisms, and motivation-situation-based behavioral decision control. At the data level, the paper further analyzes the methods and challenges of constructing role-specific corpora, focusing on data sources, copyright constraints, and structured annotation processes. In terms of evaluation, it collates multi-dimensional assessment frameworks and benchmark datasets covering role knowledge, personality fidelity, value alignment, and interactive hallucination, while commenting on the advantages and disadvantages of methods such as human evaluation, reward models, and LLM-based scoring. Finally, the paper outlines future development directions of role-playing agents, including personality evolution modeling, multi-agent collaborative narrative, multimodal immersive interaction, and integration with cognitive neuroscience, aiming to provide a systematic perspective and methodological insights for subsequent research.
Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos
Dec 15, 2025Vision-Language-Action (VLA) models provide a promising paradigm for robot learning by integrating visual perception with language-guided policy learning. However, most existing approaches rely on 2D visual inputs to perform actions in 3D physical environments, creating a significant gap between perception and action grounding. To bridge this gap, we propose a Spatial-Aware VLA Pretraining paradigm that performs explicit alignment between visual space and physical space during pretraining, enabling models to acquire 3D spatial understanding before robot policy learning. Starting from pretrained vision-language models, we leverage large-scale human demonstration videos to extract 3D visual and 3D action annotations, forming a new source of supervision that aligns 2D visual observations with 3D spatial reasoning. We instantiate this paradigm with VIPA-VLA, a dual-encoder architecture that incorporates a 3D visual encoder to augment semantic visual representations with 3D-aware features. When adapted to downstream robot tasks, VIPA-VLA achieves significantly improved grounding between 2D vision and 3D action, resulting in more robust and generalizable robotic policies.
FreeControl: Efficient, Training-Free Structural Control via One-Step Attention Extraction
Nov 07, 2025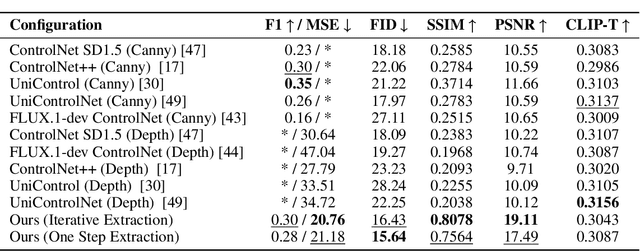
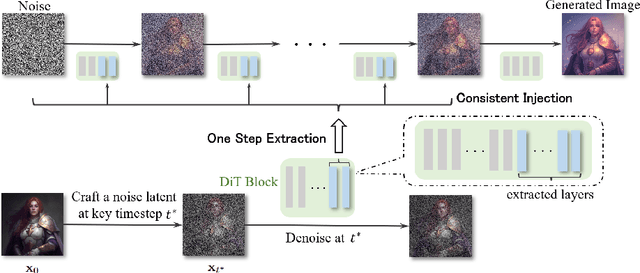
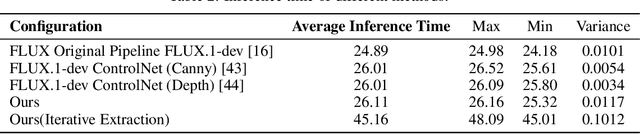

Controlling the spatial and semantic structure of diffusion-generated images remains a challenge. Existing methods like ControlNet rely on handcrafted condition maps and retraining, limiting flexibility and generalization. Inversion-based approaches offer stronger alignment but incur high inference cost due to dual-path denoising. We present FreeControl, a training-free framework for semantic structural control in diffusion models. Unlike prior methods that extract attention across multiple timesteps, FreeControl performs one-step attention extraction from a single, optimally chosen key timestep and reuses it throughout denoising. This enables efficient structural guidance without inversion or retraining. To further improve quality and stability, we introduce Latent-Condition Decoupling (LCD): a principled separation of the key timestep and the noised latent used in attention extraction. LCD provides finer control over attention quality and eliminates structural artifacts. FreeControl also supports compositional control via reference images assembled from multiple sources - enabling intuitive scene layout design and stronger prompt alignment. FreeControl introduces a new paradigm for test-time control, enabling structurally and semantically aligned, visually coherent generation directly from raw images, with the flexibility for intuitive compositional design and compatibility with modern diffusion models at approximately 5 percent additional cost.
DemoGrasp: Universal Dexterous Grasping from a Single Demonstration
Sep 26, 2025Universal grasping with multi-fingered dexterous hands is a fundamental challenge in robotic manipulation. While recent approaches successfully learn closed-loop grasping policies using reinforcement learning (RL), the inherent difficulty of high-dimensional, long-horizon exploration necessitates complex reward and curriculum design, often resulting in suboptimal solutions across diverse objects. We propose DemoGrasp, a simple yet effective method for learning universal dexterous grasping. We start from a single successful demonstration trajectory of grasping a specific object and adapt to novel objects and poses by editing the robot actions in this trajectory: changing the wrist pose determines where to grasp, and changing the hand joint angles determines how to grasp. We formulate this trajectory editing as a single-step Markov Decision Process (MDP) and use RL to optimize a universal policy across hundreds of objects in parallel in simulation, with a simple reward consisting of a binary success term and a robot-table collision penalty. In simulation, DemoGrasp achieves a 95% success rate on DexGraspNet objects using the Shadow Hand, outperforming previous state-of-the-art methods. It also shows strong transferability, achieving an average success rate of 84.6% across diverse dexterous hand embodiments on six unseen object datasets, while being trained on only 175 objects. Through vision-based imitation learning, our policy successfully grasps 110 unseen real-world objects, including small, thin items. It generalizes to spatial, background, and lighting changes, supports both RGB and depth inputs, and extends to language-guided grasping in cluttered scenes.
Being-M0.5: A Real-Time Controllable Vision-Language-Motion Model
Aug 11, 2025Human motion generation has emerged as a critical technology with transformative potential for real-world applications. However, existing vision-language-motion models (VLMMs) face significant limitations that hinder their practical deployment. We identify controllability as a main bottleneck, manifesting in five key aspects: inadequate response to diverse human commands, limited pose initialization capabilities, poor performance on long-term sequences, insufficient handling of unseen scenarios, and lack of fine-grained control over individual body parts. To overcome these limitations, we present Being-M0.5, the first real-time, controllable VLMM that achieves state-of-the-art performance across multiple motion generation tasks. Our approach is built upon HuMo100M, the largest and most comprehensive human motion dataset to date, comprising over 5 million self-collected motion sequences, 100 million multi-task instructional instances, and detailed part-level annotations that address a critical gap in existing datasets. We introduce a novel part-aware residual quantization technique for motion tokenization that enables precise, granular control over individual body parts during generation. Extensive experimental validation demonstrates Being-M0.5's superior performance across diverse motion benchmarks, while comprehensive efficiency analysis confirms its real-time capabilities. Our contributions include design insights and detailed computational analysis to guide future development of practical motion generators. We believe that HuMo100M and Being-M0.5 represent significant advances that will accelerate the adoption of motion generation technologies in real-world applications. The project page is available at https://beingbeyond.github.io/Being-M0.5.
DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Aug 07, 2025Although Vision Language Models (VLMs) exhibit strong perceptual abilities and impressive visual reasoning, they struggle with attention to detail and precise action planning in complex, dynamic environments, leading to subpar performance. Real-world tasks typically require complex interactions, advanced spatial reasoning, long-term planning, and continuous strategy refinement, usually necessitating understanding the physics rules of the target scenario. However, evaluating these capabilities in real-world scenarios is often prohibitively expensive. To bridge this gap, we introduce DeepPHY, a novel benchmark framework designed to systematically evaluate VLMs' understanding and reasoning about fundamental physical principles through a series of challenging simulated environments. DeepPHY integrates multiple physical reasoning environments of varying difficulty levels and incorporates fine-grained evaluation metrics. Our evaluation finds that even state-of-the-art VLMs struggle to translate descriptive physical knowledge into precise, predictive control.