 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Order Inversion: Rethinking Latent Multi-Hop Reasoning in Large Language Models
Jan 07, 2026Large language models (LLMs) perform well on multi-hop reasoning, yet how they internally compose multiple facts remains unclear. Recent work proposes \emph{hop-aligned circuit hypothesis}, suggesting that bridge entities are computed sequentially across layers before later-hop answers. Through systematic analyses on real-world multi-hop queries, we show that this hop-aligned assumption does not generalize: later-hop answer entities can become decodable earlier than bridge entities, a phenomenon we call \emph{layer-order inversion}, which strengthens with total hops. To explain this behavior, we propose a \emph{probabilistic recall-and-extract} framework that models multi-hop reasoning as broad probabilistic recall in shallow MLP layers followed by selective extraction in deeper attention layers. This framework is empirically validated through systematic probing analyses, reinterpreting prior layer-wise decoding evidence, explaining chain-of-thought gains, and providing a mechanistic diagnosis of multi-hop failures despite correct single-hop knowledge. Code is available at https://github.com/laquabe/Layer-Order-Inversion.
SweRank+: Multilingual, Multi-Turn Code Ranking for Software Issue Localization
Dec 23, 2025Maintaining large-scale, multilingual codebases hinges on accurately localizing issues, which requires mapping natural-language error descriptions to the relevant functions that need to be modified. However, existing ranking approaches are often Python-centric and perform a single-pass search over the codebase. This work introduces SweRank+, a framework that couples SweRankMulti, a cross-lingual code ranking tool, with SweRankAgent, an agentic search setup, for iterative, multi-turn reasoning over the code repository. SweRankMulti comprises a code embedding retriever and a listwise LLM reranker, and is trained using a carefully curated large-scale issue localization dataset spanning multiple popular programming languages. SweRankAgent adopts an agentic search loop that moves beyond single-shot localization with a memory buffer to reason and accumulate relevant localization candidates over multiple turns. Our experiments on issue localization benchmarks spanning various languages demonstrate new state-of-the-art performance with SweRankMulti, while SweRankAgent further improves localization over single-pass ranking.
SSR: Socratic Self-Refine for Large Language Model Reasoning
Nov 13, 2025



Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, yet existing test-time frameworks often rely on coarse self-verification and self-correction, limiting their effectiveness on complex tasks. In this paper, we propose Socratic Self-Refine (SSR), a novel framework for fine-grained evaluation and precise refinement of LLM reasoning. Our proposed SSR decomposes model responses into verifiable (sub-question, sub-answer) pairs, enabling step-level confidence estimation through controlled re-solving and self-consistency checks. By pinpointing unreliable steps and iteratively refining them, SSR produces more accurate and interpretable reasoning chains. Empirical results across five reasoning benchmarks and three LLMs show that SSR consistently outperforms state-of-the-art iterative self-refinement baselines. Beyond performance gains, SSR provides a principled black-box approach for evaluating and understanding the internal reasoning processes of LLMs. Code is available at https://github.com/SalesforceAIResearch/socratic-self-refine-reasoning.
Self-Abstraction from Grounded Experience for Plan-Guided Policy Refinement
Nov 08, 2025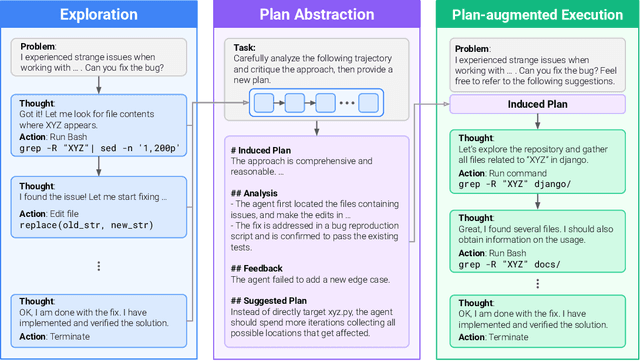

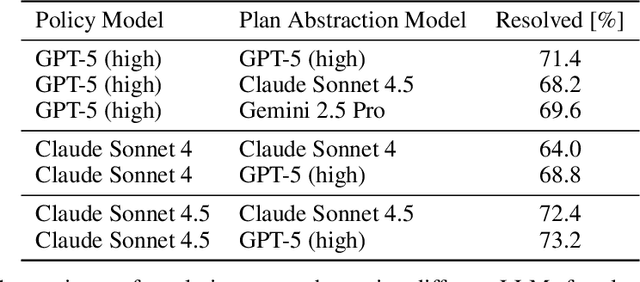
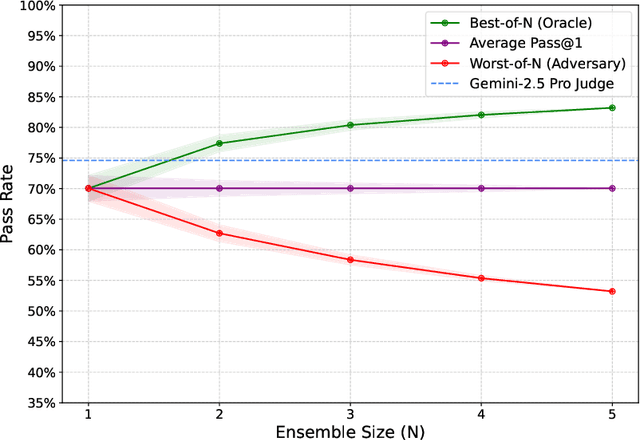
Large language model (LLM) based agents are increasingly used to tackle software engineering tasks that require multi-step reasoning and code modification, demonstrating promising yet limited performance. However, most existing LLM agents typically operate within static execution frameworks, lacking a principled mechanism to learn and self-improve from their own experience and past rollouts. As a result, their performance remains bounded by the initial framework design and the underlying LLM's capabilities. We propose Self-Abstraction from Grounded Experience (SAGE), a framework that enables agents to learn from their own task executions and refine their behavior through self-abstraction. After an initial rollout, the agent induces a concise plan abstraction from its grounded experience, distilling key steps, dependencies, and constraints. This learned abstraction is then fed back as contextual guidance, refining the agent's policy and supporting more structured, informed subsequent executions. Empirically, SAGE delivers consistent performance gains across diverse LLM backbones and agent architectures. Notably, it yields a 7.2% relative performance improvement over the strong Mini-SWE-Agent baseline when paired with the GPT-5 (high) backbone. SAGE further achieves strong overall performance on SWE-Bench Verified benchmark, reaching 73.2% and 74% Pass@1 resolve rates with the Mini-SWE-Agent and OpenHands CodeAct agent framework, respectively.
Self-Reflective Planning with Knowledge Graphs: Enhancing LLM Reasoning Reliability for Question Answering
May 26, 2025Recently, large language models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks, yet they remain prone to hallucinations when reasoning with insufficient internal knowledge. While integrating LLMs with knowledge graphs (KGs) provides access to structured, verifiable information, existing approaches often generate incomplete or factually inconsistent reasoning paths. To this end, we propose Self-Reflective Planning (SRP), a framework that synergizes LLMs with KGs through iterative, reference-guided reasoning. Specifically, given a question and topic entities, SRP first searches for references to guide planning and reflection. In the planning process, it checks initial relations and generates a reasoning path. After retrieving knowledge from KGs through a reasoning path, it implements iterative reflection by judging the retrieval result and editing the reasoning path until the answer is correctly retrieved. Extensive experiments on three public datasets demonstrate that SRP surpasses various strong baselines and further underscore its reliable reasoning ability.
Know3-RAG: A Knowledge-aware RAG Framework with Adaptive Retrieval, Generation, and Filtering
May 19, 2025Recent advances in large language models (LLMs) have led to impressive progress in natural language generation, yet their tendency to produce hallucinated or unsubstantiated content remains a critical concern. To improve factual reliability, Retrieval-Augmented Generation (RAG) integrates external knowledge during inference. However, existing RAG systems face two major limitations: (1) unreliable adaptive control due to limited external knowledge supervision, and (2) hallucinations caused by inaccurate or irrelevant references. To address these issues, we propose Know3-RAG, a knowledge-aware RAG framework that leverages structured knowledge from knowledge graphs (KGs) to guide three core stages of the RAG process, including retrieval, generation, and filtering. Specifically, we introduce a knowledge-aware adaptive retrieval module that employs KG embedding to assess the confidence of the generated answer and determine retrieval necessity, a knowledge-enhanced reference generation strategy that enriches queries with KG-derived entities to improve generated reference relevance, and a knowledge-driven reference filtering mechanism that ensures semantic alignment and factual accuracy of references. Experiments on multiple open-domain QA benchmarks demonstrate that Know3-RAG consistently outperforms strong baselines, significantly reducing hallucinations and enhancing answer reliability.
Breaking the Batch Barrier (B3) of Contrastive Learning via Smart Batch Mining
May 16, 2025Contrastive learning (CL) is a prevalent technique for training embedding models, which pulls semantically similar examples (positives) closer in the representation space while pushing dissimilar ones (negatives) further apart. A key source of negatives are 'in-batch' examples, i.e., positives from other examples in the batch. Effectiveness of such models is hence strongly influenced by the size and quality of training batches. In this work, we propose 'Breaking the Batch Barrier' (B3), a novel batch construction strategy designed to curate high-quality batches for CL. Our approach begins by using a pretrained teacher embedding model to rank all examples in the dataset, from which a sparse similarity graph is constructed. A community detection algorithm is then applied to this graph to identify clusters of examples that serve as strong negatives for one another. The clusters are then used to construct batches that are rich in in-batch negatives. Empirical results on the MMEB multimodal embedding benchmark (36 tasks) demonstrate that our method sets a new state of the art, outperforming previous best methods by +1.3 and +2.9 points at the 7B and 2B model scales, respectively. Notably, models trained with B3 surpass existing state-of-the-art results even with a batch size as small as 64, which is 4-16x smaller than that required by other methods.
SweRank: Software Issue Localization with Code Ranking
May 07, 2025Software issue localization, the task of identifying the precise code locations (files, classes, or functions) relevant to a natural language issue description (e.g., bug report, feature request), is a critical yet time-consuming aspect of software development. While recent LLM-based agentic approaches demonstrate promise, they often incur significant latency and cost due to complex multi-step reasoning and relying on closed-source LLMs. Alternatively, traditional code ranking models, typically optimized for query-to-code or code-to-code retrieval, struggle with the verbose and failure-descriptive nature of issue localization queries. To bridge this gap, we introduce SweRank, an efficient and effective retrieve-and-rerank framework for software issue localization. To facilitate training, we construct SweLoc, a large-scale dataset curated from public GitHub repositories, featuring real-world issue descriptions paired with corresponding code modifications. Empirical results on SWE-Bench-Lite and LocBench show that SweRank achieves state-of-the-art performance, outperforming both prior ranking models and costly agent-based systems using closed-source LLMs like Claude-3.5. Further, we demonstrate SweLoc's utility in enhancing various existing retriever and reranker models for issue localization, establishing the dataset as a valuable resource for the community.
VideoMind: A Chain-of-LoRA Agent for Long Video Reasoning
Mar 17, 2025Videos, with their unique temporal dimension, demand precise grounded understanding, where answers are directly linked to visual, interpretable evidence. Despite significant breakthroughs in reasoning capabilities within Large Language Models, multi-modal reasoning - especially for videos - remains unexplored. In this work, we introduce VideoMind, a novel video-language agent designed for temporal-grounded video understanding. VideoMind incorporates two key innovations: (i) We identify essential capabilities for video temporal reasoning and develop a role-based agentic workflow, including a planner for coordinating different roles, a grounder for temporal localization, a verifier to assess temporal interval accuracy, and an answerer for question-answering. (ii) To efficiently integrate these diverse roles, we propose a novel Chain-of-LoRA strategy, enabling seamless role-switching via lightweight LoRA adaptors while avoiding the overhead of multiple models, thus balancing efficiency and flexibility. Extensive experiments on 14 public benchmarks demonstrate that our agent achieves state-of-the-art performance on diverse video understanding tasks, including 3 on grounded video question-answering, 6 on video temporal grounding, and 5 on general video question-answering, underscoring its effectiveness in advancing video agent and long-form temporal reasoning.
Towards Secure Program Partitioning for Smart Contracts with LLM's In-Context Learning
Feb 20, 2025



Smart contracts are highly susceptible to manipulation attacks due to the leakage of sensitive information. Addressing manipulation vulnerabilities is particularly challenging because they stem from inherent data confidentiality issues rather than straightforward implementation bugs. To tackle this by preventing sensitive information leakage, we present PartitionGPT, the first LLM-driven approach that combines static analysis with the in-context learning capabilities of large language models (LLMs) to partition smart contracts into privileged and normal codebases, guided by a few annotated sensitive data variables. We evaluated PartitionGPT on 18 annotated smart contracts containing 99 sensitive functions. The results demonstrate that PartitionGPT successfully generates compilable, and verified partitions for 78% of the sensitive functions while reducing approximately 30% code compared to function-level partitioning approach. Furthermore, we evaluated PartitionGPT on nine real-world manipulation attacks that lead to a total loss of 25 million dollars, PartitionGPT effectively prevents eight cases, highlighting its potential for broad applicability and the necessity for secure program partitioning during smart contract development to diminish manipulation vulnerabilities.