 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2DiT: Sandwich Diffusion Transformer for Mobile Streaming Video Generation
Jan 19, 2026Diffusion Transformers (DiTs) have recently improved video generation quality. However, their heavy computational cost makes real-time or on-device generation infeasible. In this work, we introduce S2DiT, a Streaming Sandwich Diffusion Transformer designed for efficient, high-fidelity, and streaming video generation on mobile hardware. S2DiT generates more tokens but maintains efficiency with novel efficient attentions: a mixture of LinConv Hybrid Attention (LCHA) and Stride Self-Attention (SSA). Based on this, we uncover the sandwich design via a budget-aware dynamic programming search, achieving superior quality and efficiency. We further propose a 2-in-1 distillation framework that transfers the capacity of large teacher models (e.g., Wan 2.2-14B) to the compact few-step sandwich model. Together, S2DiT achieves quality on par with state-of-the-art server video models, while streaming at over 10 FPS on an iPhone.
SnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices
Jan 13, 2026Recent advances in diffusion transformers (DiTs) have set new standards in image generation, yet remain impractical for on-device deployment due to their high computational and memory costs. In this work, we present an efficient DiT framework tailored for mobile and edge devices that achieves transformer-level generation quality under strict resource constraints. Our design combines three key components. First, we propose a compact DiT architecture with an adaptive global-local sparse attention mechanism that balances global context modeling and local detail preservation. Second, we propose an elastic training framework that jointly optimizes sub-DiTs of varying capacities within a unified supernetwork, allowing a single model to dynamically adjust for efficient inference across different hardware. Finally, we develop Knowledge-Guided Distribution Matching Distillation, a step-distillation pipeline that integrates the DMD objective with knowledge transfer from few-step teacher models, producing high-fidelity and low-latency generation (e.g., 4-step) suitable for real-time on-device use. Together, these contributions enable scalable, efficient, and high-quality diffusion models for deployment on diverse hardware.
LayerComposer: Interactive Personalized T2I via Spatially-Aware Layered Canvas
Oct 23, 2025Despite their impressive visual fidelity, existing personalized generative models lack interactive control over spatial composition and scale poorly to multiple subjects. To address these limitations, we present LayerComposer, an interactive framework for personalized, multi-subject text-to-image generation. Our approach introduces two main contributions: (1) a layered canvas, a novel representation in which each subject is placed on a distinct layer, enabling occlusion-free composition; and (2) a locking mechanism that preserves selected layers with high fidelity while allowing the remaining layers to adapt flexibly to the surrounding context. Similar to professional image-editing software, the proposed layered canvas allows users to place, resize, or lock input subjects through intuitive layer manipulation. Our versatile locking mechanism requires no architectural changes, relying instead on inherent positional embeddings combined with a new complementary data sampling strategy. Extensive experiments demonstrate that LayerComposer achieves superior spatial control and identity preservation compared to the state-of-the-art methods in multi-subject personalized image generation.
Taming Diffusion Transformer for Real-Time Mobile Video Generation
Jul 17, 2025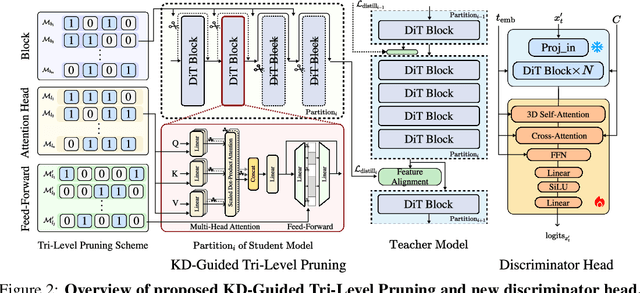
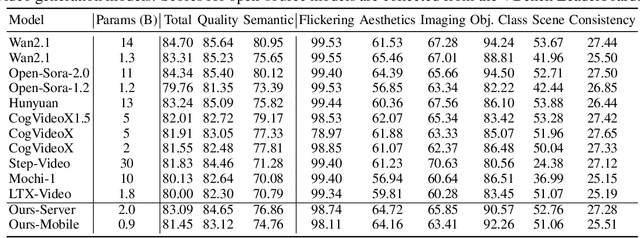

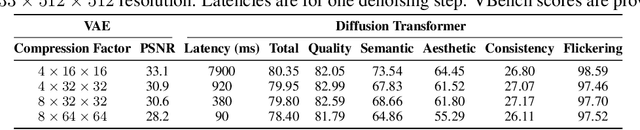
Diffusion Transformers (DiT) have shown strong performance in video generation tasks, but their high computational cost makes them impractical for resource-constrained devices like smartphones, and real-time generation is even more challenging. In this work, we propose a series of novel optimizations to significantly accelerate video generation and enable real-time performance on mobile platforms. First, we employ a highly compressed variational autoencoder (VAE) to reduce the dimensionality of the input data without sacrificing visual quality. Second, we introduce a KD-guided, sensitivity-aware tri-level pruning strategy to shrink the model size to suit mobile platform while preserving critical performance characteristics. Third, we develop an adversarial step distillation technique tailored for DiT, which allows us to reduce the number of inference steps to four. Combined, these optimizations enable our model to achieve over 10 frames per second (FPS) generation on an iPhone 16 Pro Max, demonstrating the feasibility of real-time, high-quality video generation on mobile devices.
Improving Progressive Generation with Decomposable Flow Matching
Jun 24, 2025



Generating high-dimensional visual modalities is a computationally intensive task. A common solution is progressive generation, where the outputs are synthesized in a coarse-to-fine spectral autoregressive manner. While diffusion models benefit from the coarse-to-fine nature of denoising, explicit multi-stage architectures are rarely adopted. These architectures have increased the complexity of the overall approach, introducing the need for a custom diffusion formulation, decomposition-dependent stage transitions, add-hoc samplers, or a model cascade. Our contribution, Decomposable Flow Matching (DFM), is a simple and effective framework for the progressive generation of visual media. DFM applies Flow Matching independently at each level of a user-defined multi-scale representation (such as Laplacian pyramid). As shown by our experiments, our approach improves visual quality for both images and videos, featuring superior results compared to prior multistage frameworks. On Imagenet-1k 512px, DFM achieves 35.2% improvements in FDD scores over the base architecture and 26.4% over the best-performing baseline, under the same training compute. When applied to finetuning of large models, such as FLUX, DFM shows faster convergence speed to the training distribution. Crucially, all these advantages are achieved with a single model, architectural simplicity, and minimal modifications to existing training pipelines.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).