 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELSA: Efficient LLM-Centric Split Aggregation for Privacy-Aware Hierarchical Federated Learning over Resource-Constrained Edge Networks
Jan 20, 2026Training large language models (LLMs) at the network edge faces fundamental challenges arising from device resource constraints, severe data heterogeneity, and heightened privacy risks. To address these, we propose ELSA (Efficient LLM-centric Split Aggregation), a novel framework that systematically integrates split learning (SL) and hierarchical federated learning (HFL) for distributed LLM fine-tuning over resource-constrained edge networks. ELSA introduces three key innovations. First, it employs a task-agnostic, behavior-aware client clustering mechanism that constructs semantic fingerprints using public probe inputs and symmetric KL divergence, further enhanced by prediction-consistency-based trust scoring and latency-aware edge assignment to jointly address data heterogeneity, client unreliability, and communication constraints. Second, it splits the LLM into three parts across clients and edge servers, with the cloud used only for adapter aggregation, enabling an effective balance between on-device computation cost and global convergence stability. Third, it incorporates a lightweight communication scheme based on computational sketches combined with semantic subspace orthogonal perturbation (SS-OP) to reduce communication overhead while mitigating privacy leakage during model exchanges. Experiments across diverse NLP tasks demonstrate that ELSA consistently outperforms state-of-the-art methods in terms of adaptability, convergence behavior, and robustness, establishing a scalable and privacy-aware solution for edge-side LLM fine-tuning under resource constraints.
One-Shot Hierarchical Federated Clustering
Jan 10, 2026Driven by the growth of Web-scale decentralized services, Federated Clustering (FC) aims to extract knowledge from heterogeneous clients in an unsupervised manner while preserving the clients' privacy, which has emerged as a significant challenge due to the lack of label guidance and the Non-Independent and Identically Distributed (non-IID) nature of clients. In real scenarios such as personalized recommendation and cross-device user profiling, the global cluster may be fragmented and distributed among different clients, and the clusters may exist at different granularities or even nested. Although Hierarchical Clustering (HC) is considered promising for exploring such distributions, the sophisticated recursive clustering process makes it more computationally expensive and vulnerable to privacy exposure, thus relatively unexplored under the federated learning scenario. This paper introduces an efficient one-shot hierarchical FC framework that performs client-end distribution exploration and server-end distribution aggregation through one-way prototype-level communication from clients to the server. A fine partition mechanism is developed to generate successive clusterlets to describe the complex landscape of the clients' clusters. Then, a multi-granular learning mechanism on the server is proposed to fuse the clusterlets, even when they have inconsistent granularities generated from different clients. It turns out that the complex cluster distributions across clients can be efficiently explored, and extensive experiments comparing state-of-the-art methods on ten public datasets demonstrate the superiority of the proposed method.
Embodied AI-Enhanced IoMT Edge Computing: UAV Trajectory Optimization and Task Offloading with Mobility Prediction
Dec 24, 2025



Due to their inherent flexibility and autonomous operation, unmanned aerial vehicles (UAVs) have been widely used in Internet of Medical Things (IoMT) to provide real-time biomedical edge computing service for wireless body area network (WBAN) users. In this paper, considering the time-varying task criticality characteristics of diverse WBAN users and the dual mobility between WBAN users and UAV, we investigate the dynamic task offloading and UAV flight trajectory optimization problem to minimize the weighted average task completion time of all the WBAN users, under the constraint of UAV energy consumption. To tackle the problem, an embodied AI-enhanced IoMT edge computing framework is established. Specifically, we propose a novel hierarchical multi-scale Transformer-based user trajectory prediction model based on the users' historical trajectory traces captured by the embodied AI agent (i.e., UAV). Afterwards, a prediction-enhanced deep reinforcement learning (DRL) algorithm that integrates predicted users' mobility information is designed for intelligently optimizing UAV flight trajectory and task offloading decisions. Real-word movement traces and simulation results demonstrate the superiority of the proposed methods in comparison with the existing benchmarks.
Break the Tie: Learning Cluster-Customized Category Relationships for Categorical Data Clustering
Nov 12, 2025



Categorical attributes with qualitative values are ubiquitous in cluster analysis of real datasets. Unlike the Euclidean distance of numerical attributes, the categorical attributes lack well-defined relationships of their possible values (also called categories interchangeably), which hampers the exploration of compact categorical data clusters. Although most attempts are made for developing appropriate distance metrics, they typically assume a fixed topological relationship between categories when learning distance metrics, which limits their adaptability to varying cluster structures and often leads to suboptimal clustering performance. This paper, therefore, breaks the intrinsic relationship tie of attribute categories and learns customized distance metrics suitable for flexibly and accurately revealing various cluster distributions. As a result, the fitting ability of the clustering algorithm is significantly enhanced, benefiting from the learnable category relationships. Moreover, the learned category relationships are proved to be Euclidean distance metric-compatible, enabling a seamless extension to mixed datasets that include both numerical and categorical attributes. Comparative experiments on 12 real benchmark datasets with significance tests show the superior clustering accuracy of the proposed method with an average ranking of 1.25, which is significantly higher than the 5.21 ranking of the current best-performing method.
GNN-Enabled Robust Hybrid Beamforming with Score-Based CSI Generation and Denoising
Nov 10, 2025Accurate Channel State Information (CSI) is critical for Hybrid Beamforming (HBF) tasks. However, obtaining high-resolution CSI remains challenging in practical wireless communication systems. To address this issue, we propose to utilize Graph Neural Networks (GNNs) and score-based generative models to enable robust HBF under imperfect CSI conditions. Firstly, we develop the Hybrid Message Graph Attention Network (HMGAT) which updates both node and edge features through node-level and edge-level message passing. Secondly, we design a Bidirectional Encoder Representations from Transformers (BERT)-based Noise Conditional Score Network (NCSN) to learn the distribution of high-resolution CSI, facilitating CSI generation and data augmentation to further improve HMGAT's performance. Finally, we present a Denoising Score Network (DSN) framework and its instantiation, termed DeBERT, which can denoise imperfect CSI under arbitrary channel error levels, thereby facilitating robust HBF. Experiments on DeepMIMO urban datasets demonstrate the proposed models' superior generalization, scalability, and robustness across various HBF tasks with perfect and imperfect CSI.
Agentic Graph Neural Networks for Wireless Communications and Networking Towards Edge General Intelligence: A Survey
Aug 12, 2025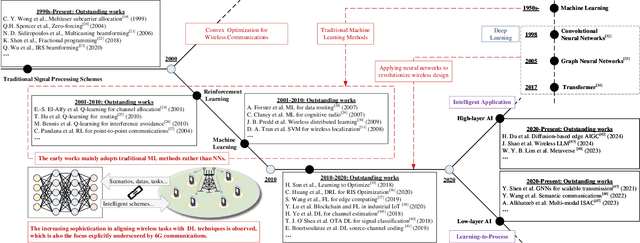
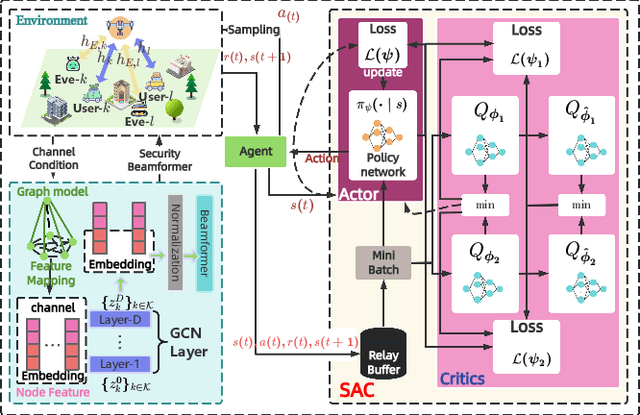
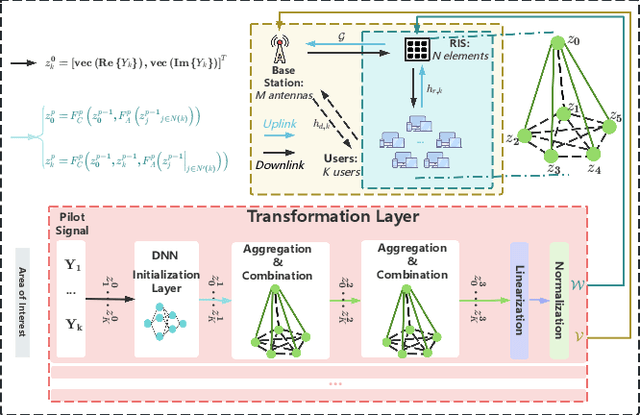
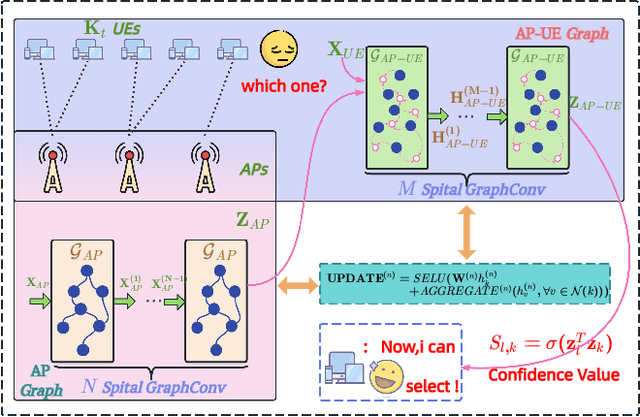
The rapid advancement of communication technologies has driven the evolution of communication networks towards both high-dimensional resource utilization and multifunctional integration. This evolving complexity poses significant challenges in designing communication networks to satisfy the growing quality-of-service and time sensitivity of mobile applications in dynamic environments. Graph neural networks (GNNs) have emerged as fundamental deep learning (DL) models for complex communication networks. GNNs not only augment the extraction of features over network topologies but also enhance scalability and facilitate distributed computation. However, most existing GNNs follow a traditional passive learning framework, which may fail to meet the needs of increasingly diverse wireless systems. This survey proposes the employment of agentic artificial intelligence (AI) to organize and integrate GNNs, enabling scenario- and task-aware implementation towards edge general intelligence. To comprehend the full capability of GNNs, we holistically review recent applications of GNNs in wireless communications and networking. Specifically, we focus on the alignment between graph representations and network topologies, and between neural architectures and wireless tasks. We first provide an overview of GNNs based on prominent neural architectures, followed by the concept of agentic GNNs. Then, we summarize and compare GNN applications for conventional systems and emerging technologies, including physical, MAC, and network layer designs, integrated sensing and communication (ISAC), reconfigurable intelligent surface (RIS) and cell-free network architecture. We further propose a large language model (LLM) framework as an intelligent question-answering agent, leveraging this survey as a local knowledge base to enable GNN-related responses tailored to wireless communication research.
Anyone Can Jailbreak: Prompt-Based Attacks on LLMs and T2Is
Jul 29, 2025Despite significant advancements in alignment and content moderation, large language models (LLMs) and text-to-image (T2I) systems remain vulnerable to prompt-based attacks known as jailbreaks. Unlike traditional adversarial examples requiring expert knowledge, many of today's jailbreaks are low-effort, high-impact crafted by everyday users with nothing more than cleverly worded prompts. This paper presents a systems-style investigation into how non-experts reliably circumvent safety mechanisms through techniques such as multi-turn narrative escalation, lexical camouflage, implication chaining, fictional impersonation, and subtle semantic edits. We propose a unified taxonomy of prompt-level jailbreak strategies spanning both text-output and T2I models, grounded in empirical case studies across popular APIs. Our analysis reveals that every stage of the moderation pipeline, from input filtering to output validation, can be bypassed with accessible strategies. We conclude by highlighting the urgent need for context-aware defenses that reflect the ease with which these jailbreaks can be reproduced in real-world settings.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
Multi-Waveguide Pinching Antennas for ISAC
May 30, 2025



Recently, a novel flexible-antenna technology, called pinching antennas, has attracted growing academic interest. By inserting discrete dielectric materials, pinching antennas can be activated at arbitrary points along waveguides, allowing for flexible customization of large-scale path loss. This paper investigates a multi-waveguide pinching-antenna integrated sensing and communications (ISAC) system, where transmit pinching antennas (TPAs) and receive pinching antennas (RPAs) coordinate to simultaneously detect one potential target and serve one downlink user. We formulate a communication rate maximization problem subject to radar signal-to-noise ratio (SNR) requirement, transmit power budget, and the allowable movement region of the TPAs, by jointly optimizing TPA locations and transmit beamforming design. To address the non-convexity of the problem, we propose a novel fine-tuning approximation method to reformulate it into a tractable form, followed by a successive convex approximation (SCA)-based algorithm to obtain the solution efficiently. Extensive simulations validate both the system design and the proposed algorithm. Results show that the proposed method achieves near-optimal performance compared with the computational-intensive exhaustive search-based benchmark, and pinching-antenna ISAC systems exhibit a distinct communication-sensing trade-off compared with conventional systems.
Progressive Data Dropout: An Embarrassingly Simple Approach to Faster Training
May 28, 2025The success of the machine learning field has reliably depended on training on large datasets. While effective, this trend comes at an extraordinary cost. This is due to two deeply intertwined factors: the size of models and the size of datasets. While promising research efforts focus on reducing the size of models, the other half of the equation remains fairly mysterious. Indeed, it is surprising that the standard approach to training remains to iterate over and over, uniformly sampling the training dataset. In this paper we explore a series of alternative training paradigms that leverage insights from hard-data-mining and dropout, simple enough to implement and use that can become the new training standard. The proposed Progressive Data Dropout reduces the number of effective epochs to as little as 12.4% of the baseline. This savings actually do not come at any cost for accuracy. Surprisingly, the proposed method improves accuracy by up to 4.82%. Our approach requires no changes to model architecture or optimizer, and can be applied across standard training pipelines, thus posing an excellent opportunity for wide adoption. Code can be found here: https://github.com/bazyagami/LearningWithRevision