 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Impairs the Balancedness of Foundation Models in Long-tailed Personalized Federated Learning
May 04, 2026Personalized federated learning (PFL) with foundation models has emerged as a promising paradigm enabling clients to adapt to heterogeneous data distributions. However, real-world scenarios often face the co-occurrence of non-IID data and long-tailed class distributions, presenting unique challenges that remain underexplored in PFL. In this paper, we investigate this long-tailed personalized federated learning and observe that current methods suffer from two limitations: (i) fine-tuning degrades performance below zero-shot baselines due to the erosion of inherent class balance in foundation models; (ii) conventional personalization techniques further transfer this bias to local models through parameter or feature-level fusion. To address these challenges, we propose Federated Learning via Gradient Purification and Residual Learning (FedPuReL), which preserves balanced knowledge in the global model while enabling unbiased personalization. Specifically, we purify local gradients using zero-shot predictions to maintain a class-balanced global model, and model personalization as residual correction atop the frozen global model. Extensive experiments demonstrate that FedPuReL consistently outperforms state-of-the-art methods, achieving superior performance on both global and personalized models across diverse long-tailed scenarios. The code is available at https://github.com/shihaohou/FedPuReL.
CoAction: Cross-task Correlation-aware Pareto Set Learning
May 03, 2026Pareto set learning (PSL) is an emerging paradigm in multi-objective optimization that trains neural networks to map preference vectors to Pareto optimal solutions. However, existing PSL methods primarily focus on solving a single multi-objective optimization problem at a time. This limitation not only increases computational costs in multi-objective multitask optimization scenarios by requiring a separate model for each task, but also fails to exploit the inter-task correlations across tasks. To address this, we propose a Cross-tAsk correlation-aware Pareto Set Learning (CoAction) framework, which leverages task-aware transformer to handle multiple tasks simultaneously. Specifically, by assigning task-specific embedding vectors to individual tasks, the model effectively distinguishes between tasks while facilitating knowledge sharing among them. We utilize a Transformer encoder as the backbone architecture to leverage its self-attention mechanism for capturing complex task dependencies. The proposed approach is evaluated on comprehensive multitask test suites covering both benchmark problems and real-world applications, demonstrating effectiveness and competitive performance in Hypervolume, Range, and Sparsity.
ELSA: Efficient LLM-Centric Split Aggregation for Privacy-Aware Hierarchical Federated Learning over Resource-Constrained Edge Networks
Jan 20, 2026Training large language models (LLMs) at the network edge faces fundamental challenges arising from device resource constraints, severe data heterogeneity, and heightened privacy risks. To address these, we propose ELSA (Efficient LLM-centric Split Aggregation), a novel framework that systematically integrates split learning (SL) and hierarchical federated learning (HFL) for distributed LLM fine-tuning over resource-constrained edge networks. ELSA introduces three key innovations. First, it employs a task-agnostic, behavior-aware client clustering mechanism that constructs semantic fingerprints using public probe inputs and symmetric KL divergence, further enhanced by prediction-consistency-based trust scoring and latency-aware edge assignment to jointly address data heterogeneity, client unreliability, and communication constraints. Second, it splits the LLM into three parts across clients and edge servers, with the cloud used only for adapter aggregation, enabling an effective balance between on-device computation cost and global convergence stability. Third, it incorporates a lightweight communication scheme based on computational sketches combined with semantic subspace orthogonal perturbation (SS-OP) to reduce communication overhead while mitigating privacy leakage during model exchanges. Experiments across diverse NLP tasks demonstrate that ELSA consistently outperforms state-of-the-art methods in terms of adaptability, convergence behavior, and robustness, establishing a scalable and privacy-aware solution for edge-side LLM fine-tuning under resource constraints.
Iterative Prompt Relocation for Distribution-Adaptive Visual Prompt Tuning
Mar 10, 2025
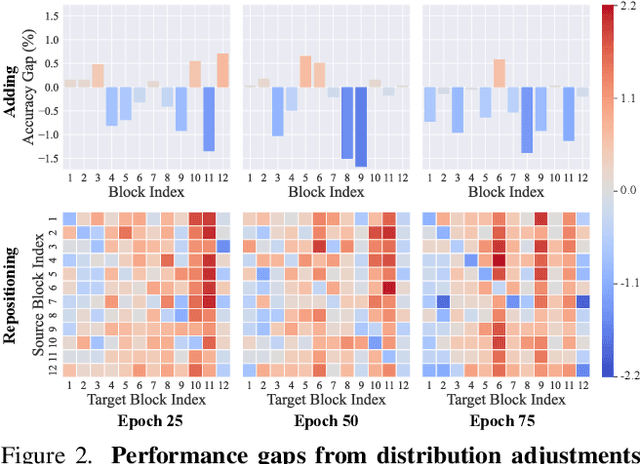
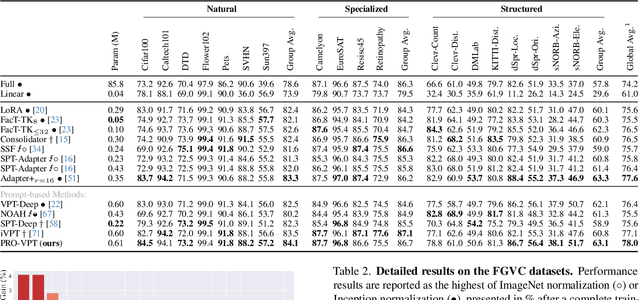

Visual prompt tuning (VPT) provides an efficient and effective solution for adapting pre-trained models to various downstream tasks by incorporating learnable prompts. However, most prior art indiscriminately applies a fixed prompt distribution across different tasks, neglecting the importance of each block differing depending on the task. In this paper, we investigate adaptive distribution optimization (ADO) by addressing two key questions: (1) How to appropriately and formally define ADO, and (2) How to design an adaptive distribution strategy guided by this definition? Through in-depth analysis, we provide an affirmative answer that properly adjusting the distribution significantly improves VPT performance, and further uncover a key insight that a nested relationship exists between ADO and VPT. Based on these findings, we propose a new VPT framework, termed PRO-VPT (iterative Prompt RelOcation-based VPT), which adaptively adjusts the distribution building upon a nested optimization formulation. Specifically, we develop a prompt relocation strategy for ADO derived from this formulation, comprising two optimization steps: identifying and pruning idle prompts, followed by determining the optimal blocks for their relocation. By iteratively performing prompt relocation and VPT, our proposal adaptively learns the optimal prompt distribution, thereby unlocking the full potential of VPT. Extensive experiments demonstrate that our proposal significantly outperforms state-of-the-art VPT methods, e.g., PRO-VPT surpasses VPT by 1.6% average accuracy, leading prompt-based methods to state-of-the-art performance on the VTAB-1k benchmark. The code is available at https://github.com/ckshang/PRO-VPT.
Collaborative Pareto Set Learning in Multiple Multi-Objective Optimization Problems
Apr 01, 2024Pareto Set Learning (PSL) is an emerging research area in multi-objective optimization, focusing on training neural networks to learn the mapping from preference vectors to Pareto optimal solutions. However, existing PSL methods are limited to addressing a single Multi-objective Optimization Problem (MOP) at a time. When faced with multiple MOPs, this limitation not only leads to significant inefficiencies but also fails to exploit the potential synergies across varying MOPs. In this paper, we propose a Collaborative Pareto Set Learning (CoPSL) framework, which simultaneously learns the Pareto sets of multiple MOPs in a collaborative manner. CoPSL employs an architecture consisting of shared and MOP-specific layers, where shared layers aim to capture common relationships among MOPs collaboratively, and MOP-specific layers process these relationships to generate solution sets for each MOP. This collaborative approach enables CoPSL to efficiently learn the Pareto sets of multiple MOPs in a single run while leveraging the relationships among various MOPs. To further understand these relationships, we experimentally demonstrate that there exist shareable representations among MOPs. Leveraging these collaboratively shared representations can effectively improve the capability to approximate Pareto sets. Extensive experiments underscore the superior efficiency and robustness of CoPSL in approximating Pareto sets compared to state-of-the-art approaches on a variety of synthetic and real-world MOPs. Code is available at https://github.com/ckshang/CoPSL.