 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonizing Generalization and Specialization: Uncertainty-Informed Collaborative Learning for Semi-supervised Medical Image Segmentation
Dec 15, 2025Vision foundation models have demonstrated strong generalization in medical image segmentation by leveraging large-scale, heterogeneous pretraining. However, they often struggle to generalize to specialized clinical tasks under limited annotations or rare pathological variations, due to a mismatch between general priors and task-specific requirements. To address this, we propose Uncertainty-informed Collaborative Learning (UnCoL), a dual-teacher framework that harmonizes generalization and specialization in semi-supervised medical image segmentation. Specifically, UnCoL distills both visual and semantic representations from a frozen foundation model to transfer general knowledge, while concurrently maintaining a progressively adapting teacher to capture fine-grained and task-specific representations. To balance guidance from both teachers, pseudo-label learning in UnCoL is adaptively regulated by predictive uncertainty, which selectively suppresses unreliable supervision and stabilizes learning in ambiguous regions. Experiments on diverse 2D and 3D segmentation benchmarks show that UnCoL consistently outperforms state-of-the-art semi-supervised methods and foundation model baselines. Moreover, our model delivers near fully supervised performance with markedly reduced annotation requirements.
ADHint: Adaptive Hints with Difficulty Priors for Reinforcement Learning
Dec 15, 2025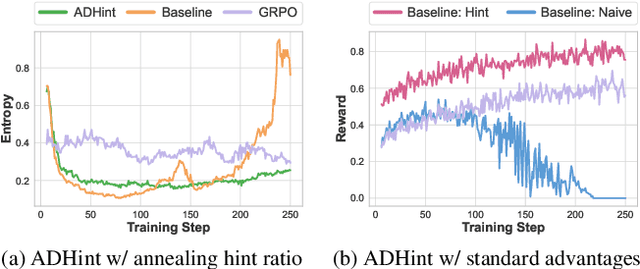
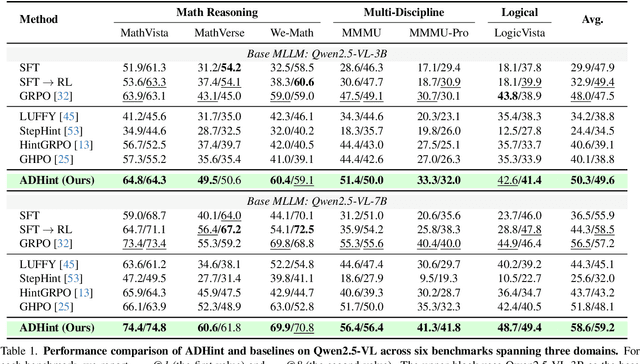
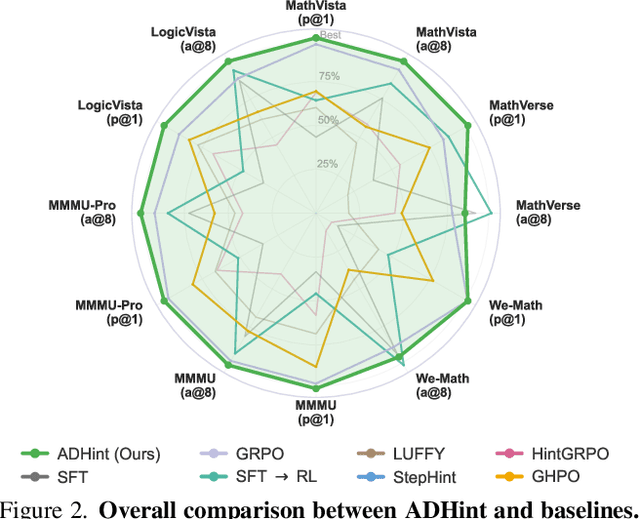
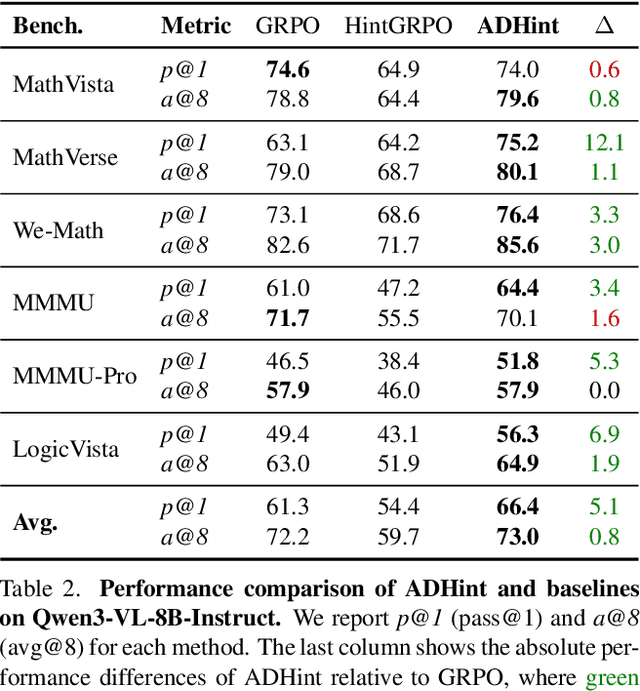
To combine the advantages of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), recent methods have integrated ''hints'' into post-training, which are prefix segments of complete reasoning trajectories, aiming for powerful knowledge expansion and reasoning generalization. However, existing hint-based RL methods typically ignore difficulty when scheduling hint ratios and estimating relative advantages, leading to unstable learning and excessive imitation of off-policy hints. In this work, we propose ADHint, which treats difficulty as a key factor in both hint-ratio schedule and relative-advantage estimation to achieve a better trade-off between exploration and imitation. Specifically, we propose Adaptive Hint with Sample Difficulty Prior, which evaluates each sample's difficulty under the policy model and accordingly schedules an appropriate hint ratio to guide its rollouts. We also introduce Consistency-based Gradient Modulation and Selective Masking for Hint Preservation to modulate token-level gradients within hints, preventing biased and destructive updates. Additionally, we propose Advantage Estimation with Rollout Difficulty Posterior, which leverages the relative difficulty of rollouts with and without hints to estimate their respective advantages, thereby achieving more balanced updates. Extensive experiments across diverse modalities, model scales, and domains demonstrate that ADHint delivers superior reasoning ability and out-of-distribution generalization, consistently surpassing existing methods in both pass@1 and avg@8. Our code and dataset will be made publicly available upon paper acceptance.
NeuroSketch: An Effective Framework for Neural Decoding via Systematic Architectural Optimization
Dec 10, 2025Neural decoding, a critical component of Brain-Computer Interface (BCI), has recently attracted increasing research interest. Previous research has focused on leveraging signal processing and deep learning methods to enhance neural decoding performance. However, the in-depth exploration of model architectures remains underexplored, despite its proven effectiveness in other tasks such as energy forecasting and image classification. In this study, we propose NeuroSketch, an effective framework for neural decoding via systematic architecture optimization. Starting with the basic architecture study, we find that CNN-2D outperforms other architectures in neural decoding tasks and explore its effectiveness from temporal and spatial perspectives. Building on this, we optimize the architecture from macro- to micro-level, achieving improvements in performance at each step. The exploration process and model validations take over 5,000 experiments spanning three distinct modalities (visual, auditory, and speech), three types of brain signals (EEG, SEEG, and ECoG), and eight diverse decoding tasks. Experimental results indicate that NeuroSketch achieves state-of-the-art (SOTA) performance across all evaluated datasets, positioning it as a powerful tool for neural decoding. Our code and scripts are available at https://github.com/Galaxy-Dawn/NeuroSketch.
Distilling Future Temporal Knowledge with Masked Feature Reconstruction for 3D Object Detection
Dec 09, 2025



Camera-based temporal 3D object detection has shown impressive results in autonomous driving, with offline models improving accuracy by using future frames. Knowledge distillation (KD) can be an appealing framework for transferring rich information from offline models to online models. However, existing KD methods overlook future frames, as they mainly focus on spatial feature distillation under strict frame alignment or on temporal relational distillation, thereby making it challenging for online models to effectively learn future knowledge. To this end, we propose a sparse query-based approach, Future Temporal Knowledge Distillation (FTKD), which effectively transfers future frame knowledge from an offline teacher model to an online student model. Specifically, we present a future-aware feature reconstruction strategy to encourage the student model to capture future features without strict frame alignment. In addition, we further introduce future-guided logit distillation to leverage the teacher's stable foreground and background context. FTKD is applied to two high-performing 3D object detection baselines, achieving up to 1.3 mAP and 1.3 NDS gains on the nuScenes dataset, as well as the most accurate velocity estimation, without increasing inference cost.
MeshRipple: Structured Autoregressive Generation of Artist-Meshes
Dec 09, 2025Meshes serve as a primary representation for 3D assets. Autoregressive mesh generators serialize faces into sequences and train on truncated segments with sliding-window inference to cope with memory limits. However, this mismatch breaks long-range geometric dependencies, producing holes and fragmented components. To address this critical limitation, we introduce MeshRipple, which expands a mesh outward from an active generation frontier, akin to a ripple on a surface. MeshRipple rests on three key innovations: a frontier-aware BFS tokenization that aligns the generation order with surface topology; an expansive prediction strategy that maintains coherent, connected surface growth; and a sparse-attention global memory that provides an effectively unbounded receptive field to resolve long-range topological dependencies. This integrated design enables MeshRipple to generate meshes with high surface fidelity and topological completeness, outperforming strong recent baselines.
See More, Change Less: Anatomy-Aware Diffusion for Contrast Enhancement
Dec 08, 2025Image enhancement improves visual quality and helps reveal details that are hard to see in the original image. In medical imaging, it can support clinical decision-making, but current models often over-edit. This can distort organs, create false findings, and miss small tumors because these models do not understand anatomy or contrast dynamics. We propose SMILE, an anatomy-aware diffusion model that learns how organs are shaped and how they take up contrast. It enhances only clinically relevant regions while leaving all other areas unchanged. SMILE introduces three key ideas: (1) structure-aware supervision that follows true organ boundaries and contrast patterns; (2) registration-free learning that works directly with unaligned multi-phase CT scans; (3) unified inference that provides fast and consistent enhancement across all contrast phases. Across six external datasets, SMILE outperforms existing methods in image quality (14.2% higher SSIM, 20.6% higher PSNR, 50% better FID) and in clinical usefulness by producing anatomically accurate and diagnostically meaningful images. SMILE also improves cancer detection from non-contrast CT, raising the F1 score by up to 10 percent.
DINO-Detect: A Simple yet Effective Framework for Blur-Robust AI-Generated Image Detection
Nov 18, 2025With growing concerns over image authenticity and digital safety, the field of AI-generated image (AIGI) detection has progressed rapidly. Yet, most AIGI detectors still struggle under real-world degradations, particularly motion blur, which frequently occurs in handheld photography, fast motion, and compressed video. Such blur distorts fine textures and suppresses high-frequency artifacts, causing severe performance drops in real-world settings. We address this limitation with a blur-robust AIGI detection framework based on teacher-student knowledge distillation. A high-capacity teacher (DINOv3), trained on clean (i.e., sharp) images, provides stable and semantically rich representations that serve as a reference for learning. By freezing the teacher to maintain its generalization ability, we distill its feature and logit responses from sharp images to a student trained on blurred counterparts, enabling the student to produce consistent representations under motion degradation. Extensive experiments benchmarks show that our method achieves state-of-the-art performance under both motion-blurred and clean conditions, demonstrating improved generalization and real-world applicability. Source codes will be released at: https://github.com/JiaLiangShen/Dino-Detect-for-blur-robust-AIGC-Detection.
Fine-Grained Representation for Lane Topology Reasoning
Nov 18, 2025
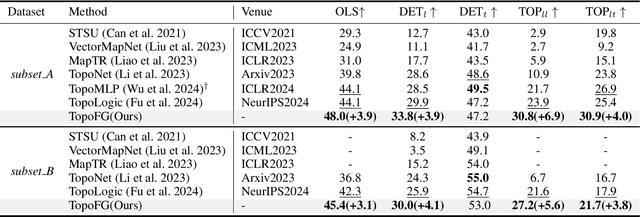
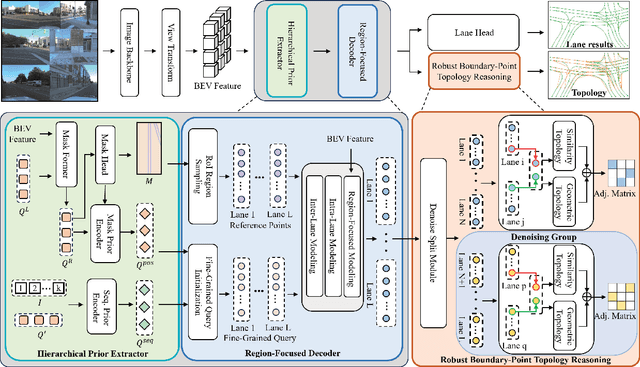
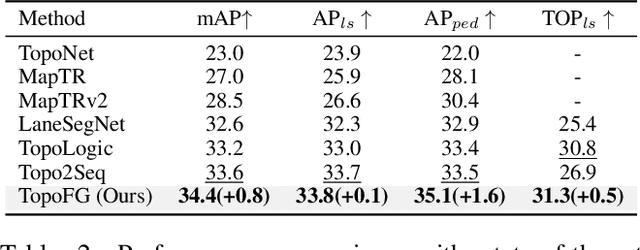
Precise modeling of lane topology is essential for autonomous driving, as it directly impacts navigation and control decisions. Existing methods typically represent each lane with a single query and infer topological connectivity based on the similarity between lane queries. However, this kind of design struggles to accurately model complex lane structures, leading to unreliable topology prediction. In this view, we propose a Fine-Grained lane topology reasoning framework (TopoFG). It divides the procedure from bird's-eye-view (BEV) features to topology prediction via fine-grained queries into three phases, i.e., Hierarchical Prior Extractor (HPE), Region-Focused Decoder (RFD), and Robust Boundary-Point Topology Reasoning (RBTR). Specifically, HPE extracts global spatial priors from the BEV mask and local sequential priors from in-lane keypoint sequences to guide subsequent fine-grained query modeling. RFD constructs fine-grained queries by integrating the spatial and sequential priors. It then samples reference points in RoI regions of the mask and applies cross-attention with BEV features to refine the query representations of each lane. RBTR models lane connectivity based on boundary-point query features and further employs a topological denoising strategy to reduce matching ambiguity. By integrating spatial and sequential priors into fine-grained queries and applying a denoising strategy to boundary-point topology reasoning, our method precisely models complex lane structures and delivers trustworthy topology predictions. Extensive experiments on the OpenLane-V2 benchmark demonstrate that TopoFG achieves new state-of-the-art performance, with an OLS of 48.0 on subsetA and 45.4 on subsetB.
Reaction Prediction via Interaction Modeling of Symmetric Difference Shingle Sets
Nov 16, 2025



Chemical reaction prediction remains a fundamental challenge in organic chemistry, where existing machine learning models face two critical limitations: sensitivity to input permutations (molecule/atom orderings) and inadequate modeling of substructural interactions governing reactivity. These shortcomings lead to inconsistent predictions and poor generalization to real-world scenarios. To address these challenges, we propose ReaDISH, a novel reaction prediction model that learns permutation-invariant representations while incorporating interaction-aware features. It introduces two innovations: (1) symmetric difference shingle encoding, which extends the differential reaction fingerprint (DRFP) by representing shingles as continuous high-dimensional embeddings, capturing structural changes while eliminating order sensitivity; and (2) geometry-structure interaction attention, a mechanism that models intra- and inter-molecular interactions at the shingle level. Extensive experiments demonstrate that ReaDISH improves reaction prediction performance across diverse benchmarks. It shows enhanced robustness with an average improvement of 8.76% on R$^2$ under permutation perturbations.
BSO: Binary Spiking Online Optimization Algorithm
Nov 16, 2025Binary Spiking Neural Networks (BSNNs) offer promising efficiency advantages for resource-constrained computing. However, their training algorithms often require substantial memory overhead due to latent weights storage and temporal processing requirements. To address this issue, we propose Binary Spiking Online (BSO) optimization algorithm, a novel online training algorithm that significantly reduces training memory. BSO directly updates weights through flip signals under the online training framework. These signals are triggered when the product of gradient momentum and weights exceeds a threshold, eliminating the need for latent weights during training. To enhance performance, we propose T-BSO, a temporal-aware variant that leverages the inherent temporal dynamics of BSNNs by capturing gradient information across time steps for adaptive threshold adjustment. Theoretical analysis establishes convergence guarantees for both BSO and T-BSO, with formal regret bounds characterizing their convergence rates. Extensive experiments demonstrate that both BSO and T-BSO achieve superior optimization performance compared to existing training methods for BSNNs. The codes are available at https://github.com/hamings1/BSO.