 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOsmosis Distillation: Model Hijacking with the Fewest Samples
Mar 05, 2026Transfer learning is devised to leverage knowledge from pre-trained models to solve new tasks with limited data and computational resources. Meanwhile, dataset distillation has emerged to synthesize a compact dataset that preserves critical information from the original large dataset. Therefore, a combination of transfer learning and dataset distillation offers promising performance in evaluations. However, a non-negligible security threat remains undiscovered in transfer learning using synthetic datasets generated by dataset distillation methods, where an adversary can perform a model hijacking attack with only a few poisoned samples in the synthetic dataset. To reveal this threat, we propose Osmosis Distillation (OD) attack, a novel model hijacking strategy that targets deep learning models using the fewest samples. Comprehensive evaluations on various datasets demonstrate that the OD attack attains high attack success rates in hidden tasks while preserving high model utility in original tasks. Furthermore, the distilled osmosis set enables model hijacking across diverse model architectures, allowing model hijacking in transfer learning with considerable attack performance and model utility. We argue that awareness of using third-party synthetic datasets in transfer learning must be raised.
Turning Black Box into White Box: Dataset Distillation Leaks
Mar 01, 2026Dataset distillation compresses a large real dataset into a small synthetic one, enabling models trained on the synthetic data to achieve performance comparable to those trained on the real data. Although synthetic datasets are assumed to be privacy-preserving, we show that existing distillation methods can cause severe privacy leakage because synthetic datasets implicitly encode the weight trajectories of the distilled model, they become over-informative and exploitable by adversaries. To expose this risk, we introduce the Information Revelation Attack (IRA) against state-of-the-art distillation techniques. Experiments show that IRA accurately predicts both the distillation algorithm and model architecture, and can successfully infer membership and recover sensitive samples from the real dataset.
MIRROR: Manifold Ideal Reference ReconstructOR for Generalizable AI-Generated Image Detection
Feb 02, 2026High-fidelity generative models have narrowed the perceptual gap between synthetic and real images, posing serious threats to media security. Most existing AI-generated image (AIGI) detectors rely on artifact-based classification and struggle to generalize to evolving generative traces. In contrast, human judgment relies on stable real-world regularities, with deviations from the human cognitive manifold serving as a more generalizable signal of forgery. Motivated by this insight, we reformulate AIGI detection as a Reference-Comparison problem that verifies consistency with the real-image manifold rather than fitting specific forgery cues. We propose MIRROR (Manifold Ideal Reference ReconstructOR), a framework that explicitly encodes reality priors using a learnable discrete memory bank. MIRROR projects an input into a manifold-consistent ideal reference via sparse linear combination, and uses the resulting residuals as robust detection signals. To evaluate whether detectors reach the "superhuman crossover" required to replace human experts, we introduce the Human-AIGI benchmark, featuring a psychophysically curated human-imperceptible subset. Across 14 benchmarks, MIRROR consistently outperforms prior methods, achieving gains of 2.1% on six standard benchmarks and 8.1% on seven in-the-wild benchmarks. On Human-AIGI, MIRROR reaches 89.6% accuracy across 27 generators, surpassing both lay users and visual experts, and further approaching the human perceptual limit as pretrained backbones scale. The code is publicly available at: https://github.com/349793927/MIRROR
Beyond Artifacts: Real-Centric Envelope Modeling for Reliable AI-Generated Image Detection
Dec 24, 2025The rapid progress of generative models has intensified the need for reliable and robust detection under real-world conditions. However, existing detectors often overfit to generator-specific artifacts and remain highly sensitive to real-world degradations. As generative architectures evolve and images undergo multi-round cross-platform sharing and post-processing (chain degradations), these artifact cues become obsolete and harder to detect. To address this, we propose Real-centric Envelope Modeling (REM), a new paradigm that shifts detection from learning generator artifacts to modeling the robust distribution of real images. REM introduces feature-level perturbations in self-reconstruction to generate near-real samples, and employs an envelope estimator with cross-domain consistency to learn a boundary enclosing the real image manifold. We further build RealChain, a comprehensive benchmark covering both open-source and commercial generators with simulated real-world degradation. Across eight benchmark evaluations, REM achieves an average improvement of 7.5% over state-of-the-art methods, and notably maintains exceptional generalization on the severely degraded RealChain benchmark, establishing a solid foundation for synthetic image detection under real-world conditions. The code and the RealChain benchmark will be made publicly available upon acceptance of the paper.
DINO-Detect: A Simple yet Effective Framework for Blur-Robust AI-Generated Image Detection
Nov 18, 2025With growing concerns over image authenticity and digital safety, the field of AI-generated image (AIGI) detection has progressed rapidly. Yet, most AIGI detectors still struggle under real-world degradations, particularly motion blur, which frequently occurs in handheld photography, fast motion, and compressed video. Such blur distorts fine textures and suppresses high-frequency artifacts, causing severe performance drops in real-world settings. We address this limitation with a blur-robust AIGI detection framework based on teacher-student knowledge distillation. A high-capacity teacher (DINOv3), trained on clean (i.e., sharp) images, provides stable and semantically rich representations that serve as a reference for learning. By freezing the teacher to maintain its generalization ability, we distill its feature and logit responses from sharp images to a student trained on blurred counterparts, enabling the student to produce consistent representations under motion degradation. Extensive experiments benchmarks show that our method achieves state-of-the-art performance under both motion-blurred and clean conditions, demonstrating improved generalization and real-world applicability. Source codes will be released at: https://github.com/JiaLiangShen/Dino-Detect-for-blur-robust-AIGC-Detection.
A Machine Learning Approach for Predicting Human Preference for Graph Layouts
Mar 01, 2021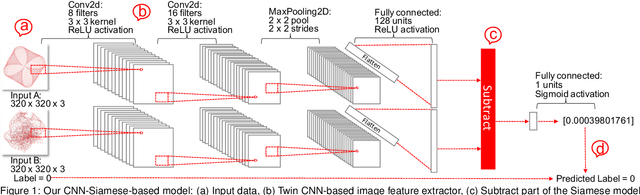
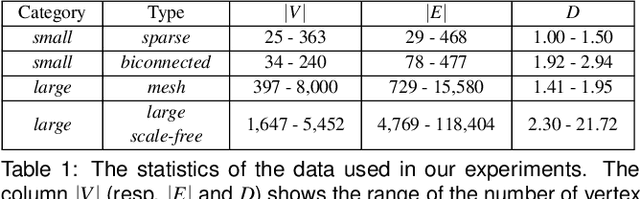
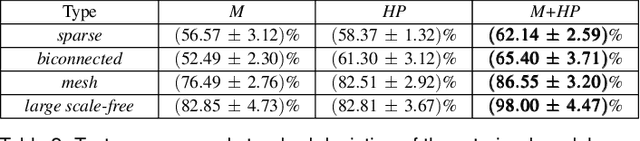
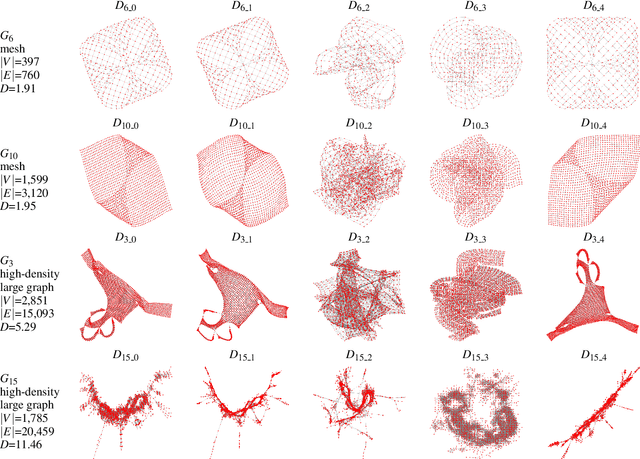
Understanding what graph layout human prefer and why they prefer is significant and challenging due to the highly complex visual perception and cognition system in human brain. In this paper, we present the first machine learning approach for predicting human preference for graph layouts. In general, the data sets with human preference labels are limited and insufficient for training deep networks. To address this, we train our deep learning model by employing the transfer learning method, e.g., exploiting the quality metrics, such as shape-based metrics, edge crossing and stress, which are shown to be correlated to human preference on graph layouts. Experimental results using the ground truth human preference data sets show that our model can successfully predict human preference for graph layouts. To our best knowledge, this is the first approach for predicting qualitative evaluation of graph layouts using human preference experiment data.
ASDN: A Deep Convolutional Network for Arbitrary Scale Image Super-Resolution
Oct 06, 2020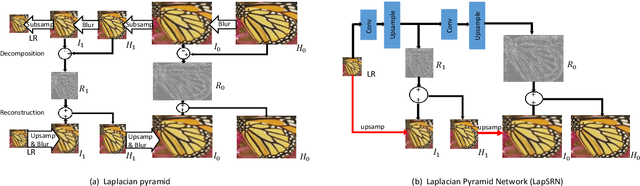
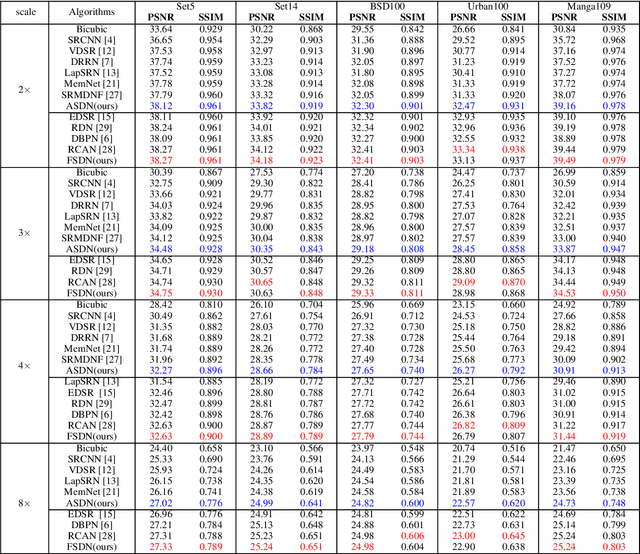
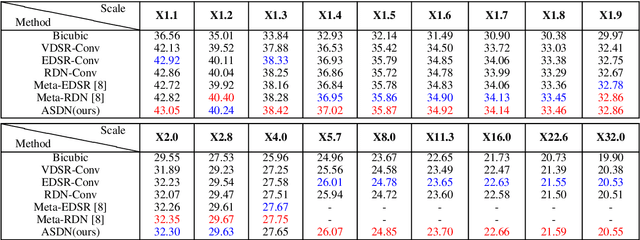
Deep convolutional neural networks have significantly improved the peak signal-to-noise ratio of SuperResolution (SR). However, image viewer applications commonly allow users to zoom the images to arbitrary magnification scales, thus far imposing a large number of required training scales at a tremendous computational cost. To obtain a more computationally efficient model for arbitrary scale SR, this paper employs a Laplacian pyramid method to reconstruct any-scale high-resolution (HR) images using the high-frequency image details in a Laplacian Frequency Representation. For SR of small-scales (between 1 and 2), images are constructed by interpolation from a sparse set of precalculated Laplacian pyramid levels. SR of larger scales is computed by recursion from small scales, which significantly reduces the computational cost. For a full comparison, fixed- and any-scale experiments are conducted using various benchmarks. At fixed scales, ASDN outperforms predefined upsampling methods (e.g., SRCNN, VDSR, DRRN) by about 1 dB in PSNR. At any-scale, ASDN generally exceeds Meta-SR on many scales.
Deep Bi-Dense Networks for Image Super-Resolution
Oct 11, 2018
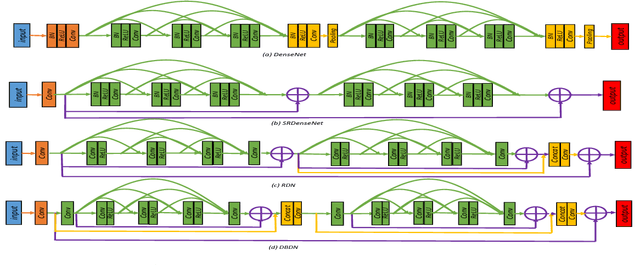
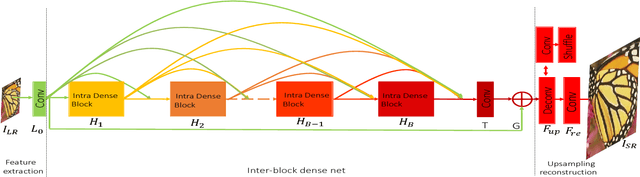
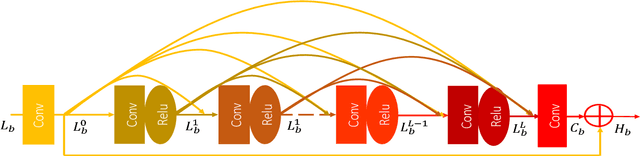
This paper proposes Deep Bi-Dense Networks (DBDN) for single image super-resolution. Our approach extends previous intra-block dense connection approaches by including novel inter-block dense connections. In this way, feature information propagates from a single dense block to all subsequent blocks, instead of to a single successor. To build a DBDN, we firstly construct intra-dense blocks, which extract and compress abundant local features via densely connected convolutional layers and compression layers for further feature learning. Then, we use an inter-block dense net to connect intra-dense blocks, which allow each intra-dense block propagates its own local features to all successors. Additionally, our bi-dense construction connects each block to the output, alleviating the vanishing gradient problems in training. The evaluation of our proposed method on five benchmark datasets shows that our DBDN outperforms the state of the art in SISR with a moderate number of network parameters.