 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshRipple: Structured Autoregressive Generation of Artist-Meshes
Dec 09, 2025Meshes serve as a primary representation for 3D assets. Autoregressive mesh generators serialize faces into sequences and train on truncated segments with sliding-window inference to cope with memory limits. However, this mismatch breaks long-range geometric dependencies, producing holes and fragmented components. To address this critical limitation, we introduce MeshRipple, which expands a mesh outward from an active generation frontier, akin to a ripple on a surface. MeshRipple rests on three key innovations: a frontier-aware BFS tokenization that aligns the generation order with surface topology; an expansive prediction strategy that maintains coherent, connected surface growth; and a sparse-attention global memory that provides an effectively unbounded receptive field to resolve long-range topological dependencies. This integrated design enables MeshRipple to generate meshes with high surface fidelity and topological completeness, outperforming strong recent baselines.
Dexterous Manipulation Transfer via Progressive Kinematic-Dynamic Alignment
Nov 14, 2025The inherent difficulty and limited scalability of collecting manipulation data using multi-fingered robot hand hardware platforms have resulted in severe data scarcity, impeding research on data-driven dexterous manipulation policy learning. To address this challenge, we present a hand-agnostic manipulation transfer system. It efficiently converts human hand manipulation sequences from demonstration videos into high-quality dexterous manipulation trajectories without requirements of massive training data. To tackle the multi-dimensional disparities between human hands and dexterous hands, as well as the challenges posed by high-degree-of-freedom coordinated control of dexterous hands, we design a progressive transfer framework: first, we establish primary control signals for dexterous hands based on kinematic matching; subsequently, we train residual policies with action space rescaling and thumb-guided initialization to dynamically optimize contact interactions under unified rewards; finally, we compute wrist control trajectories with the objective of preserving operational semantics. Using only human hand manipulation videos, our system automatically configures system parameters for different tasks, balancing kinematic matching and dynamic optimization across dexterous hands, object categories, and tasks. Extensive experimental results demonstrate that our framework can automatically generate smooth and semantically correct dexterous hand manipulation that faithfully reproduces human intentions, achieving high efficiency and strong generalizability with an average transfer success rate of 73%, providing an easily implementable and scalable method for collecting robot dexterous manipulation data.
A Compositional Framework for On-the-Fly LTLf Synthesis
Aug 06, 2025Reactive synthesis from Linear Temporal Logic over finite traces (LTLf) can be reduced to a two-player game over a Deterministic Finite Automaton (DFA) of the LTLf specification. The primary challenge here is DFA construction, which is 2EXPTIME-complete in the worst case. Existing techniques either construct the DFA compositionally before solving the game, leveraging automata minimization to mitigate state-space explosion, or build the DFA incrementally during game solving to avoid full DFA construction. However, neither is dominant. In this paper, we introduce a compositional on-the-fly synthesis framework that integrates the strengths of both approaches, focusing on large conjunctions of smaller LTLf formulas common in practice. This framework applies composition during game solving instead of automata (game arena) construction. While composing all intermediate results may be necessary in the worst case, pruning these results simplifies subsequent compositions and enables early detection of unrealizability. Specifically, the framework allows two composition variants: pruning before composition to take full advantage of minimization or pruning during composition to guide on-the-fly synthesis. Compared to state-of-the-art synthesis solvers, our framework is able to solve a notable number of instances that other solvers cannot handle. A detailed analysis shows that both composition variants have unique merits.
On-the-fly Synthesis for LTL over Finite Traces: An Efficient Approach that Counts
Aug 14, 2024



We present an on-the-fly synthesis framework for Linear Temporal Logic over finite traces (LTLf) based on top-down deterministic automata construction. Existing approaches rely on constructing a complete Deterministic Finite Automaton (DFA) corresponding to the LTLf specification, a process with doubly exponential complexity relative to the formula size in the worst case. In this case, the synthesis procedure cannot be conducted until the entire DFA is constructed. This inefficiency is the main bottleneck of existing approaches. To address this challenge, we first present a method for converting LTLf into Transition-based DFA (TDFA) by directly leveraging LTLf semantics, incorporating intermediate results as direct components of the final automaton to enable parallelized synthesis and automata construction. We then explore the relationship between LTLf synthesis and TDFA games and subsequently develop an algorithm for performing LTLf synthesis using on-the-fly TDFA game solving. This algorithm traverses the state space in a global forward manner combined with a local backward method, along with the detection of strongly connected components. Moreover, we introduce two optimization techniques -- model-guided synthesis and state entailment -- to enhance the practical efficiency of our approach. Experimental results demonstrate that our on-the-fly approach achieves the best performance on the tested benchmarks and effectively complements existing tools and approaches.
C3D: Cascade Control with Change Point Detection and Deep Koopman Learning for Autonomous Surface Vehicles
Mar 14, 2024In this paper, we discuss the development and deployment of a robust autonomous system capable of performing various tasks in the maritime domain under unknown dynamic conditions. We investigate a data-driven approach based on modular design for ease of transfer of autonomy across different maritime surface vessel platforms. The data-driven approach alleviates issues related to a priori identification of system models that may become deficient under evolving system behaviors or shifting, unanticipated, environmental influences. Our proposed learning-based platform comprises a deep Koopman system model and a change point detector that provides guidance on domain shifts prompting relearning under severe exogenous and endogenous perturbations. Motion control of the autonomous system is achieved via an optimal controller design. The Koopman linearized model naturally lends itself to a linear-quadratic regulator (LQR) control design. We propose the C3D control architecture Cascade Control with Change Point Detection and Deep Koopman Learning. The framework is verified in station keeping task on an ASV in both simulation and real experiments. The approach achieved at least 13.9 percent improvement in mean distance error in all test cases compared to the methods that do not consider system changes.
Vision-driven Autonomous Flight of UAV Along River Using Deep Reinforcement Learning with Dynamic Expert Guidance
Jan 17, 2024Vision-driven autonomous flight and obstacle avoidance of Unmanned Aerial Vehicles (UAVs) along complex riverine environments for tasks like rescue and surveillance requires a robust control policy, which is yet difficult to obtain due to the shortage of trainable river environment simulators and reward sparsity in such environments. To easily verify the navigation controller performance for the river following task before real-world deployment, we developed a trainable photo-realistic dynamics-free riverine simulation environment using Unity. Successful river following trajectories in the environment are manually collected and Behavior Clone (BC) is used to train an Imitation Learning (IL) agent to mimic expert behavior and generate expert guidance. Finally, a framework is proposed to train a Deep Reinforcement Learning (DRL) agent using BC expert guidance and improve the expert policy online by sampling good demonstrations produced by the DRL to increase convergence rate and policy performance. This framework is able to solve the along-river autonomous navigation task and outperform baseline RL and IL methods. The code and trainable environments are available.
An Efficient Detection and Control System for Underwater Docking using Machine Learning and Realistic Simulation: A Comprehensive Approach
Nov 06, 2023



Underwater docking is critical to enable the persistent operation of Autonomous Underwater Vehicles (AUVs). For this, the AUV must be capable of detecting and localizing the docking station, which is complex due to the highly dynamic undersea environment. Image-based solutions offer a high acquisition rate and versatile alternative to adapt to this environment; however, the underwater environment presents challenges such as low visibility, high turbidity, and distortion. In addition to this, field experiments to validate underwater docking capabilities can be costly and dangerous due to the specialized equipment and safety considerations required to conduct the experiments. This work compares different deep-learning architectures to perform underwater docking detection and classification. The architecture with the best performance is then compressed using knowledge distillation under the teacher-student paradigm to reduce the network's memory footprint, allowing real-time implementation. To reduce the simulation-to-reality gap, a Generative Adversarial Network (GAN) is used to do image-to-image translation, converting the Gazebo simulation image into a realistic underwater-looking image. The obtained image is then processed using an underwater image formation model to simulate image attenuation over distance under different water types. The proposed method is finally evaluated according to the AUV docking success rate and compared with classical vision methods. The simulation results show an improvement of 20% in the high turbidity scenarios regardless of the underwater currents. Furthermore, we show the performance of the proposed approach by showing experimental results on the off-the-shelf AUV Iver3.
ASV Station Keeping under Wind Disturbances using Neural Network Simulation Error Minimization Model Predictive Control
Oct 11, 2023Station keeping is an essential maneuver for Autonomous Surface Vehicles (ASVs), mainly when used in confined spaces, to carry out surveys that require the ASV to keep its position or in collaboration with other vehicles where the relative position has an impact over the mission. However, this maneuver can become challenging for classic feedback controllers due to the need for an accurate model of the ASV dynamics and the environmental disturbances. This work proposes a Model Predictive Controller using Neural Network Simulation Error Minimization (NNSEM-MPC) to accurately predict the dynamics of the ASV under wind disturbances. The performance of the proposed scheme under wind disturbances is tested and compared against other controllers in simulation, using the Robotics Operating System (ROS) and the multipurpose simulation environment Gazebo. A set of six tests were conducted by combining two wind speeds (3 m/s and 6 m/s) and three wind directions (0$^\circ$, 90$^\circ$, and 180$^\circ$). The simulation results clearly show the advantage of the NNSEM-MPC over the following methods: backstepping controller, sliding mode controller, simplified dynamics MPC (SD-MPC), neural ordinary differential equation MPC (NODE-MPC), and knowledge-based NODE MPC (KNODE-MPC). The proposed NNSEM-MPC approach performs better than the rest in 4 out of the 6 test conditions, and it is the second best in the 2 remaining test cases, reducing the mean position and heading error by at least 31\% and 46\% respectively across all the test cases. In terms of execution speed, the proposed NNSEM-MPC is at least 36\% faster than the rest of the MPC controllers. The field experiments on two different ASV platforms showed that ASVs can effectively keep the station utilizing the proposed method, with a position error as low as $1.68$ m and a heading error as low as $6.14^{\circ}$ within time windows of at least $150$s.
Learning on Abstract Domains: A New Approach for Verifiable Guarantee in Reinforcement Learning
Jun 13, 2021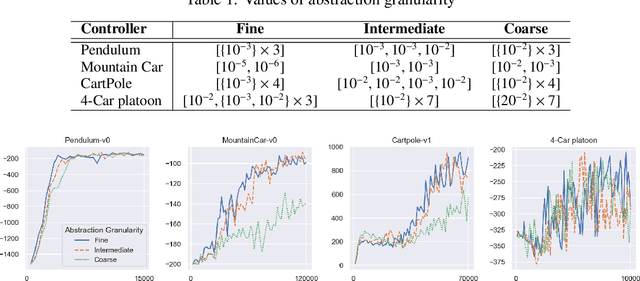
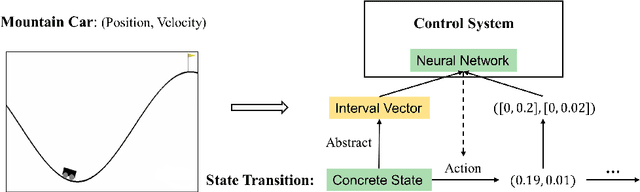
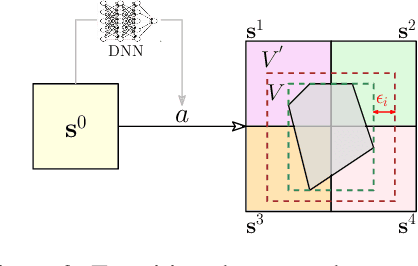
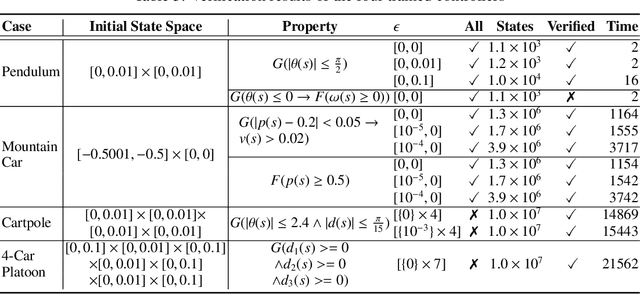
Formally verifying Deep Reinforcement Learning (DRL) systems is a challenging task due to the dynamic continuity of system behaviors and the black-box feature of embedded neural networks. In this paper, we propose a novel abstraction-based approach to train DRL systems on finite abstract domains instead of concrete system states. It yields neural networks whose input states are finite, making hosting DRL systems directly verifiable using model checking techniques. Our approach is orthogonal to existing DRL algorithms and off-the-shelf model checkers. We implement a resulting prototype training and verification framework and conduct extensive experiments on the state-of-the-art benchmark. The results show that the systems trained in our approach can be verified more efficiently while they retain comparable performance against those that are trained without abstraction.
FakePolisher: Making DeepFakes More Detection-Evasive by Shallow Reconstruction
Jun 13, 2020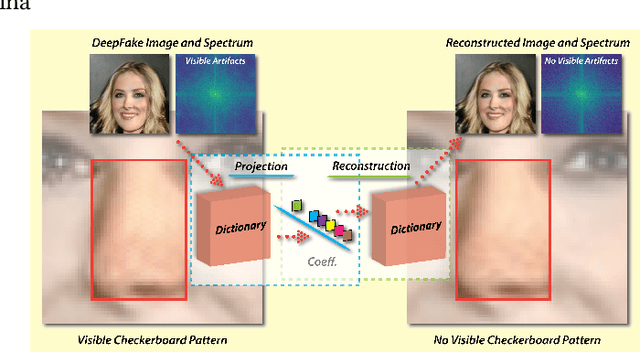
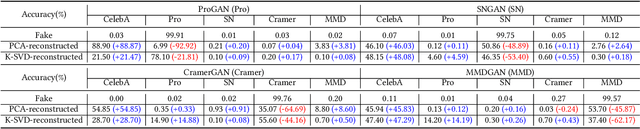
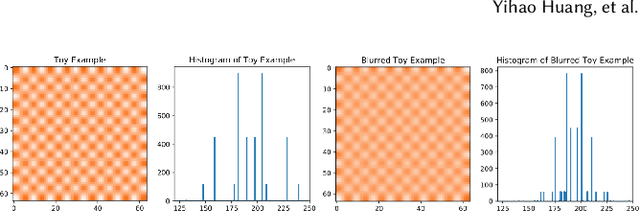
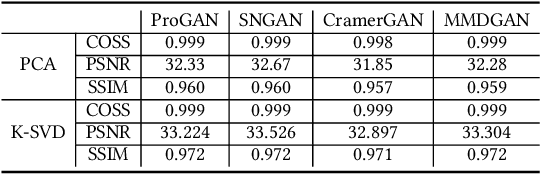
The recently rapid advances of generative adversarial networks (GANs) in synthesizing realistic and natural DeepFake information (e.g., images, video) cause severe concerns and threats to our society. At this moment, GAN-based image generation methods are still imperfect, whose upsampling design has limitations in leaving some certain artifact patterns in the synthesized image. Such artifact patterns can be easily exploited (by recent methods) for difference detection of real and GAN-synthesized images. To reduce the artifacts in the synthesized images, deep reconstruction techniques are usually futile because the process itself can leave traces of artifacts. In this paper, we devise a simple yet powerful approach termed FakePolisher that performs shallow reconstruction of fake images through learned linear dictionary, intending to effectively and efficiently reduce the artifacts introduced during image synthesis. The comprehensive evaluation on 3 state-of-the-art DeepFake detection methods and fake images generated by 16 popular GAN-based fake image generation techniques, demonstrates the effectiveness of our technique.