 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Dataset and Methods for Fine-Grained Compositional Referring Expression Comprehension via Specialist-MLLM Collaboration
Feb 28, 2025



Referring Expression Comprehension (REC) is a foundational cross-modal task that evaluates the interplay of language understanding, image comprehension, and language-to-image grounding. To advance this field, we introduce a new REC dataset with two key features. First, it is designed with controllable difficulty levels, requiring fine-grained reasoning across object categories, attributes, and relationships. Second, it incorporates negative text and images generated through fine-grained editing, explicitly testing a model's ability to reject non-existent targets, an often-overlooked yet critical challenge in existing datasets. To address fine-grained compositional REC, we propose novel methods based on a Specialist-MLLM collaboration framework, leveraging the complementary strengths of them: Specialist Models handle simpler tasks efficiently, while MLLMs are better suited for complex reasoning. Based on this synergy, we introduce two collaborative strategies. The first, Slow-Fast Adaptation (SFA), employs a routing mechanism to adaptively delegate simple tasks to Specialist Models and complex tasks to MLLMs. Additionally, common error patterns in both models are mitigated through a target-refocus strategy. The second, Candidate Region Selection (CRS), generates multiple bounding box candidates based on Specialist Model and uses the advanced reasoning capabilities of MLLMs to identify the correct target. Extensive experiments on our dataset and other challenging compositional benchmarks validate the effectiveness of our approaches. The SFA strategy achieves a trade-off between localization accuracy and efficiency, and the CRS strategy greatly boosts the performance of both Specialist Models and MLLMs. We aim for this work to offer valuable insights into solving complex real-world tasks by strategically combining existing tools for maximum effectiveness, rather than reinventing them.
Rethinking Multimodal Learning from the Perspective of Mitigating Classification Ability Disproportion
Feb 27, 2025



Although multimodal learning~(MML) has garnered remarkable progress, the existence of modality imbalance hinders multimodal learning from achieving its expected superiority over unimodal models in practice. To overcome this issue, mainstream multimodal learning methods have placed greater emphasis on balancing the learning process. However, these approaches do not explicitly enhance the classification ability of weaker modalities, leading to limited performance promotion. By designing a sustained boosting algorithm, we propose a novel multimodal learning approach to dynamically balance the classification ability of weak and strong modalities. Concretely, we first propose a sustained boosting algorithm in multimodal learning by simultaneously optimizing the classification and residual errors using a designed configurable classifier module. Then, we propose an adaptive classifier assignment strategy to dynamically facilitate the classification performance of weak modality. To this end, the classification ability of strong and weak modalities is expected to be balanced, thereby mitigating the imbalance issue. Empirical experiments on widely used datasets reveal the superiority of our method through comparison with various state-of-the-art~(SoTA) multimodal learning baselines.
Deep Learning-Powered Electrical Brain Signals Analysis: Advancing Neurological Diagnostics
Feb 24, 2025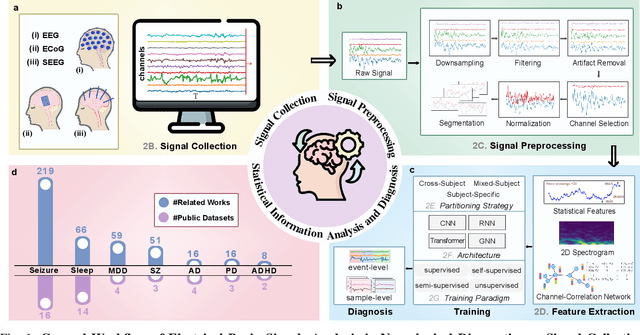
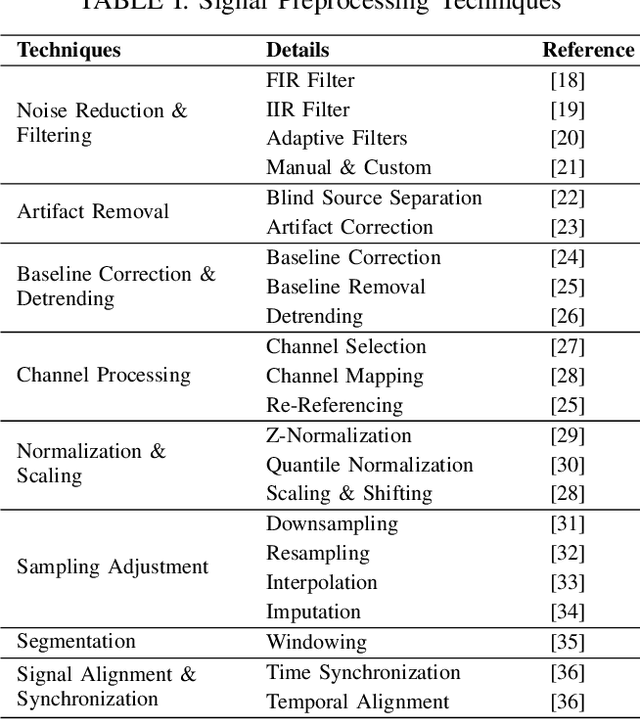

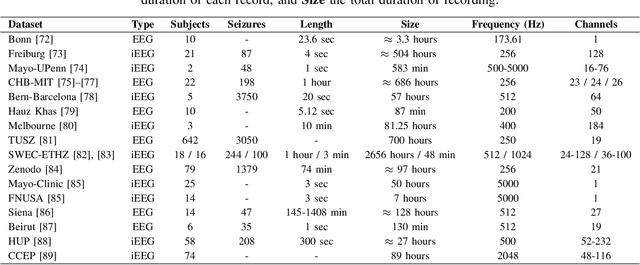
Neurological disorders represent significant global health challenges, driving the advancement of brain signal analysis methods. Scalp electroencephalography (EEG) and intracranial electroencephalography (iEEG) are widely used to diagnose and monitor neurological conditions. However, dataset heterogeneity and task variations pose challenges in developing robust deep learning solutions. This review systematically examines recent advances in deep learning approaches for EEG/iEEG-based neurological diagnostics, focusing on applications across 7 neurological conditions using 46 datasets. We explore trends in data utilization, model design, and task-specific adaptations, highlighting the importance of pre-trained multi-task models for scalable, generalizable solutions. To advance research, we propose a standardized benchmark for evaluating models across diverse datasets to enhance reproducibility. This survey emphasizes how recent innovations can transform neurological diagnostics and enable the development of intelligent, adaptable healthcare solutions.
Towards Accurate Binary Spiking Neural Networks: Learning with Adaptive Gradient Modulation Mechanism
Feb 20, 2025



Binary Spiking Neural Networks (BSNNs) inherit the eventdriven paradigm of SNNs, while also adopting the reduced storage burden of binarization techniques. These distinct advantages grant BSNNs lightweight and energy-efficient characteristics, rendering them ideal for deployment on resource-constrained edge devices. However, due to the binary synaptic weights and non-differentiable spike function, effectively training BSNNs remains an open question. In this paper, we conduct an in-depth analysis of the challenge for BSNN learning, namely the frequent weight sign flipping problem. To mitigate this issue, we propose an Adaptive Gradient Modulation Mechanism (AGMM), which is designed to reduce the frequency of weight sign flipping by adaptively adjusting the gradients during the learning process. The proposed AGMM can enable BSNNs to achieve faster convergence speed and higher accuracy, effectively narrowing the gap between BSNNs and their full-precision equivalents. We validate AGMM on both static and neuromorphic datasets, and results indicate that it achieves state-of-the-art results among BSNNs. This work substantially reduces storage demands and enhances SNNs' inherent energy efficiency, making them highly feasible for resource-constrained environments.
PSCon: Toward Conversational Product Search
Feb 19, 2025



Conversational Product Search (CPS) is confined to simulated conversations due to the lack of real-world CPS datasets that reflect human-like language. Additionally, current conversational datasets are limited to support cross-market and multi-lingual usage. In this paper, we introduce a new CPS data collection protocol and present PSCon, a novel CPS dataset designed to assist product search via human-like conversations. The dataset is constructed using a coached human-to-human data collection protocol and supports two languages and dual markets. Also, the dataset enables thorough exploration of six subtasks of CPS: user intent detection, keyword extraction, system action prediction, question selection, item ranking, and response generation. Furthermore, we also offer an analysis of the dataset and propose a benchmark model on the proposed CPS dataset.
MSE-Adapter: A Lightweight Plugin Endowing LLMs with the Capability to Perform Multimodal Sentiment Analysis and Emotion Recognition
Feb 18, 2025Current Multimodal Sentiment Analysis (MSA) and Emotion Recognition in Conversations (ERC) methods based on pre-trained language models exhibit two primary limitations: 1) Once trained for MSA and ERC tasks, these pre-trained language models lose their original generalized capabilities. 2) They demand considerable computational resources. As the size of pre-trained language models continues to grow, training larger multimodal sentiment analysis models using previous approaches could result in unnecessary computational cost. In response to this challenge, we propose \textbf{M}ultimodal \textbf{S}entiment Analysis and \textbf{E}motion Recognition \textbf{Adapter} (MSE-Adapter), a lightweight and adaptable plugin. This plugin enables a large language model (LLM) to carry out MSA or ERC tasks with minimal computational overhead (only introduces approximately 2.6M to 2.8M trainable parameters upon the 6/7B models), while preserving the intrinsic capabilities of the LLM. In the MSE-Adapter, the Text-Guide-Mixer (TGM) module is introduced to establish explicit connections between non-textual and textual modalities through the Hadamard product. This allows non-textual modalities to better align with textual modalities at the feature level, promoting the generation of higher-quality pseudo tokens. Extensive experiments were conducted on four public English and Chinese datasets using consumer-grade GPUs and open-source LLMs (Qwen-1.8B, ChatGLM3-6B-base, and LLaMA2-7B) as the backbone. The results demonstrate the effectiveness of the proposed plugin. The code will be released on GitHub after a blind review.
Spiking Vision Transformer with Saccadic Attention
Feb 18, 2025The combination of Spiking Neural Networks (SNNs) and Vision Transformers (ViTs) holds potential for achieving both energy efficiency and high performance, particularly suitable for edge vision applications. However, a significant performance gap still exists between SNN-based ViTs and their ANN counterparts. Here, we first analyze why SNN-based ViTs suffer from limited performance and identify a mismatch between the vanilla self-attention mechanism and spatio-temporal spike trains. This mismatch results in degraded spatial relevance and limited temporal interactions. To address these issues, we draw inspiration from biological saccadic attention mechanisms and introduce an innovative Saccadic Spike Self-Attention (SSSA) method. Specifically, in the spatial domain, SSSA employs a novel spike distribution-based method to effectively assess the relevance between Query and Key pairs in SNN-based ViTs. Temporally, SSSA employs a saccadic interaction module that dynamically focuses on selected visual areas at each timestep and significantly enhances whole scene understanding through temporal interactions. Building on the SSSA mechanism, we develop a SNN-based Vision Transformer (SNN-ViT). Extensive experiments across various visual tasks demonstrate that SNN-ViT achieves state-of-the-art performance with linear computational complexity. The effectiveness and efficiency of the SNN-ViT highlight its potential for power-critical edge vision applications.
QP-SNN: Quantized and Pruned Spiking Neural Networks
Feb 09, 2025



Brain-inspired Spiking Neural Networks (SNNs) leverage sparse spikes to encode information and operate in an asynchronous event-driven manner, offering a highly energy-efficient paradigm for machine intelligence. However, the current SNN community focuses primarily on performance improvement by developing large-scale models, which limits the applicability of SNNs in resource-limited edge devices. In this paper, we propose a hardware-friendly and lightweight SNN, aimed at effectively deploying high-performance SNN in resource-limited scenarios. Specifically, we first develop a baseline model that integrates uniform quantization and structured pruning, called QP-SNN baseline. While this baseline significantly reduces storage demands and computational costs, it suffers from performance decline. To address this, we conduct an in-depth analysis of the challenges in quantization and pruning that lead to performance degradation and propose solutions to enhance the baseline's performance. For weight quantization, we propose a weight rescaling strategy that utilizes bit width more effectively to enhance the model's representation capability. For structured pruning, we propose a novel pruning criterion using the singular value of spatiotemporal spike activities to enable more accurate removal of redundant kernels. Extensive experiments demonstrate that integrating two proposed methods into the baseline allows QP-SNN to achieve state-of-the-art performance and efficiency, underscoring its potential for enhancing SNN deployment in edge intelligence computing.
Multi-Label Test-Time Adaptation with Bound Entropy Minimization
Feb 06, 2025



Mainstream test-time adaptation (TTA) techniques endeavor to mitigate distribution shifts via entropy minimization for multi-class classification, inherently increasing the probability of the most confident class. However, when encountering multi-label instances, the primary challenge stems from the varying number of labels per image, and prioritizing only the highest probability class inevitably undermines the adaptation of other positive labels. To address this issue, we investigate TTA within multi-label scenario (ML--TTA), developing Bound Entropy Minimization (BEM) objective to simultaneously increase the confidence of multiple top predicted labels. Specifically, to determine the number of labels for each augmented view, we retrieve a paired caption with yielded textual labels for that view. These labels are allocated to both the view and caption, called weak label set and strong label set with the same size k. Following this, the proposed BEM considers the highest top-k predicted labels from view and caption as a single entity, respectively, learning both view and caption prompts concurrently. By binding top-k predicted labels, BEM overcomes the limitation of vanilla entropy minimization, which exclusively optimizes the most confident class. Across the MSCOCO, VOC, and NUSWIDE multi-label datasets, our ML--TTA framework equipped with BEM exhibits superior performance compared to the latest SOTA methods, across various model architectures, prompt initialization, and varying label scenarios. The code is available at https://github.com/Jinx630/ML-TTA.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.