 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Brain Tumor Segmentation from the Frequency Domain Perspective
Jun 11, 2025Precise segmentation of brain tumors, particularly contrast-enhancing regions visible in post-contrast MRI (areas highlighted by contrast agent injection), is crucial for accurate clinical diagnosis and treatment planning but remains challenging. However, current methods exhibit notable performance degradation in segmenting these enhancing brain tumor areas, largely due to insufficient consideration of MRI-specific tumor features such as complex textures and directional variations. To address this, we propose the Harmonized Frequency Fusion Network (HFF-Net), which rethinks brain tumor segmentation from a frequency-domain perspective. To comprehensively characterize tumor regions, we develop a Frequency Domain Decomposition (FDD) module that separates MRI images into low-frequency components, capturing smooth tumor contours and high-frequency components, highlighting detailed textures and directional edges. To further enhance sensitivity to tumor boundaries, we introduce an Adaptive Laplacian Convolution (ALC) module that adaptively emphasizes critical high-frequency details using dynamically updated convolution kernels. To effectively fuse tumor features across multiple scales, we design a Frequency Domain Cross-Attention (FDCA) integrating semantic, positional, and slice-specific information. We further validate and interpret frequency-domain improvements through visualization, theoretical reasoning, and experimental analyses. Extensive experiments on four public datasets demonstrate that HFF-Net achieves an average relative improvement of 4.48\% (ranging from 2.39\% to 7.72\%) in the mean Dice scores across the three major subregions, and an average relative improvement of 7.33% (ranging from 5.96% to 8.64%) in the segmentation of contrast-enhancing tumor regions, while maintaining favorable computational efficiency and clinical applicability. Code: https://github.com/VinyehShaw/HFF.
ConvBoost: Boosting ConvNets for Sensor-based Activity Recognition
May 22, 2023



Human activity recognition (HAR) is one of the core research themes in ubiquitous and wearable computing. With the shift to deep learning (DL) based analysis approaches, it has become possible to extract high-level features and perform classification in an end-to-end manner. Despite their promising overall capabilities, DL-based HAR may suffer from overfitting due to the notoriously small, often inadequate, amounts of labeled sample data that are available for typical HAR applications. In response to such challenges, we propose ConvBoost -- a novel, three-layer, structured model architecture and boosting framework for convolutional network based HAR. Our framework generates additional training data from three different perspectives for improved HAR, aiming to alleviate the shortness of labeled training data in the field. Specifically, with the introduction of three conceptual layers--Sampling Layer, Data Augmentation Layer, and Resilient Layer -- we develop three "boosters" -- R-Frame, Mix-up, and C-Drop -- to enrich the per-epoch training data by dense-sampling, synthesizing, and simulating, respectively. These new conceptual layers and boosters, that are universally applicable for any kind of convolutional network, have been designed based on the characteristics of the sensor data and the concept of frame-wise HAR. In our experimental evaluation on three standard benchmarks (Opportunity, PAMAP2, GOTOV) we demonstrate the effectiveness of our ConvBoost framework for HAR applications based on variants of convolutional networks: vanilla CNN, ConvLSTM, and Attention Models. We achieved substantial performance gains for all of them, which suggests that the proposed approach is generic and can serve as a practical solution for boosting the performance of existing ConvNet-based HAR models. This is an open-source project, and the code can be found at https://github.com/sshao2013/ConvBoost
* 21 pages
Ubi-SleepNet: Advanced Multimodal Fusion Techniques for Three-stage Sleep Classification Using Ubiquitous Sensing
Nov 19, 2021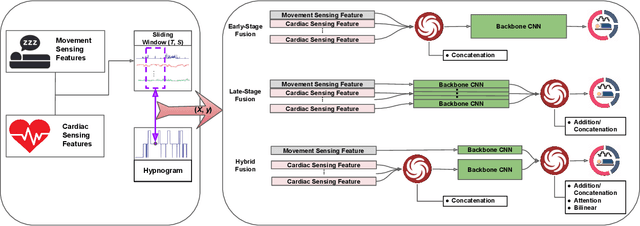
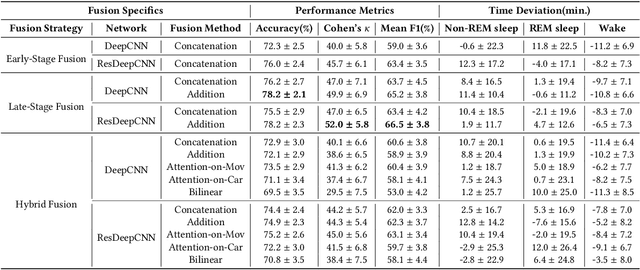
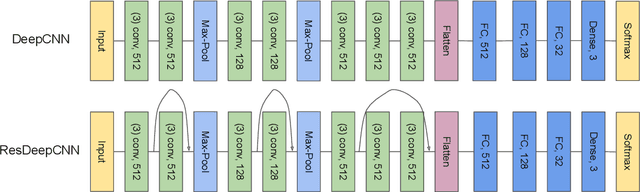
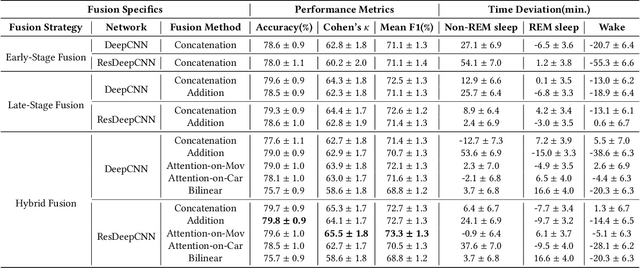
Sleep is a fundamental physiological process that is essential for sustaining a healthy body and mind. The gold standard for clinical sleep monitoring is polysomnography(PSG), based on which sleep can be categorized into five stages, including wake/rapid eye movement sleep (REM sleep)/Non-REM sleep 1 (N1)/Non-REM sleep 2 (N2)/Non-REM sleep 3 (N3). However, PSG is expensive, burdensome, and not suitable for daily use. For long-term sleep monitoring, ubiquitous sensing may be a solution. Most recently, cardiac and movement sensing has become popular in classifying three-stage sleep, since both modalities can be easily acquired from research-grade or consumer-grade devices (e.g., Apple Watch). However, how best to fuse the data for the greatest accuracy remains an open question. In this work, we comprehensively studied deep learning (DL)-based advanced fusion techniques consisting of three fusion strategies alongside three fusion methods for three-stage sleep classification based on two publicly available datasets. Experimental results demonstrate important evidence that three-stage sleep can be reliably classified by fusing cardiac/movement sensing modalities, which may potentially become a practical tool to conduct large-scale sleep stage assessment studies or long-term self-tracking on sleep. To accelerate the progression of sleep research in the ubiquitous/wearable computing community, we made this project open source, and the code can be found at: https://github.com/bzhai/Ubi-SleepNet.