 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Weighted Parameter Fusion with CLIP for Class-Incremental Learning
Mar 25, 2025Class-incremental Learning (CIL) enables the model to incrementally absorb knowledge from new classes and build a generic classifier across all previously encountered classes. When the model optimizes with new classes, the knowledge of previous classes is inevitably erased, leading to catastrophic forgetting. Addressing this challenge requires making a trade-off between retaining old knowledge and accommodating new information. However, this balancing process often requires sacrificing some information, which can lead to a partial loss in the model's ability to discriminate between classes. To tackle this issue, we design the adaptive weighted parameter fusion with Contrastive Language-Image Pre-training (CLIP), which not only takes into account the variability of the data distribution of different tasks, but also retains all the effective information of the parameter matrix to the greatest extent. In addition, we introduce a balance factor that can balance the data distribution alignment and distinguishability of adjacent tasks. Experimental results on several traditional benchmarks validate the superiority of the proposed method.
Feature Calibration enhanced Parameter Synthesis for CLIP-based Class-incremental Learning
Mar 25, 2025Class-incremental Learning (CIL) enables models to continuously learn new class knowledge while memorizing previous classes, facilitating their adaptation and evolution in dynamic environments. Traditional CIL methods are mainly based on visual features, which limits their ability to handle complex scenarios. In contrast, Vision-Language Models (VLMs) show promising potential to promote CIL by integrating pretrained knowledge with textual features. However, previous methods make it difficult to overcome catastrophic forgetting while preserving the generalization capabilities of VLMs. To tackle these challenges, we propose Feature Calibration enhanced Parameter Synthesis (FCPS) in this paper. Specifically, our FCPS employs a specific parameter adjustment mechanism to iteratively refine the proportion of original visual features participating in the final class determination, ensuring the model's foundational generalization capabilities. Meanwhile, parameter integration across different tasks achieves a balance between learning new class knowledge and retaining old knowledge. Experimental results on popular benchmarks (e.g., CIFAR100 and ImageNet100) validate the superiority of the proposed method.
UniMoMo: Unified Generative Modeling of 3D Molecules for De Novo Binder Design
Mar 25, 2025The design of target-specific molecules such as small molecules, peptides, and antibodies is vital for biological research and drug discovery. Existing generative methods are restricted to single-domain molecules, failing to address versatile therapeutic needs or utilize cross-domain transferability to enhance model performance. In this paper, we introduce Unified generative Modeling of 3D Molecules (UniMoMo), the first framework capable of designing binders of multiple molecular domains using a single model. In particular, UniMoMo unifies the representations of different molecules as graphs of blocks, where each block corresponds to either a standard amino acid or a molecular fragment. Based on these unified representations, UniMoMo utilizes a geometric latent diffusion model for 3D molecular generation, featuring an iterative full-atom autoencoder to compress blocks into latent space points, followed by an E(3)-equivariant diffusion process. Extensive benchmarks across peptides, antibodies, and small molecules demonstrate the superiority of our unified framework over existing domain-specific models, highlighting the benefits of multi-domain training.
CRCL: Causal Representation Consistency Learning for Anomaly Detection in Surveillance Videos
Mar 24, 2025Video Anomaly Detection (VAD) remains a fundamental yet formidable task in the video understanding community, with promising applications in areas such as information forensics and public safety protection. Due to the rarity and diversity of anomalies, existing methods only use easily collected regular events to model the inherent normality of normal spatial-temporal patterns in an unsupervised manner. Previous studies have shown that existing unsupervised VAD models are incapable of label-independent data offsets (e.g., scene changes) in real-world scenarios and may fail to respond to light anomalies due to the overgeneralization of deep neural networks. Inspired by causality learning, we argue that there exist causal factors that can adequately generalize the prototypical patterns of regular events and present significant deviations when anomalous instances occur. In this regard, we propose Causal Representation Consistency Learning (CRCL) to implicitly mine potential scene-robust causal variable in unsupervised video normality learning. Specifically, building on the structural causal models, we propose scene-debiasing learning and causality-inspired normality learning to strip away entangled scene bias in deep representations and learn causal video normality, respectively. Extensive experiments on benchmarks validate the superiority of our method over conventional deep representation learning. Moreover, ablation studies and extension validation show that the CRCL can cope with label-independent biases in multi-scene settings and maintain stable performance with only limited training data available.
Temporal-Consistent Video Restoration with Pre-trained Diffusion Models
Mar 19, 2025
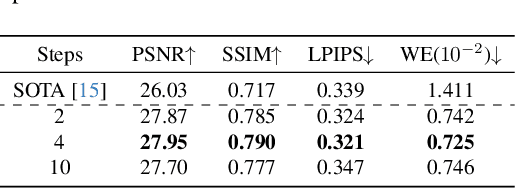
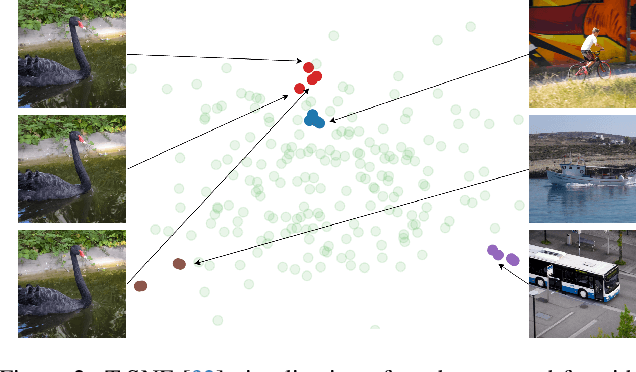
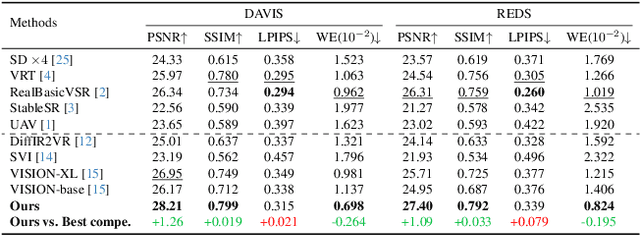
Video restoration (VR) aims to recover high-quality videos from degraded ones. Although recent zero-shot VR methods using pre-trained diffusion models (DMs) show good promise, they suffer from approximation errors during reverse diffusion and insufficient temporal consistency. Moreover, dealing with 3D video data, VR is inherently computationally intensive. In this paper, we advocate viewing the reverse process in DMs as a function and present a novel Maximum a Posterior (MAP) framework that directly parameterizes video frames in the seed space of DMs, eliminating approximation errors. We also introduce strategies to promote bilevel temporal consistency: semantic consistency by leveraging clustering structures in the seed space, and pixel-level consistency by progressive warping with optical flow refinements. Extensive experiments on multiple virtual reality tasks demonstrate superior visual quality and temporal consistency achieved by our method compared to the state-of-the-art.
When the Future Becomes the Past: Taming Temporal Correspondence for Self-supervised Video Representation Learning
Mar 19, 2025The past decade has witnessed notable achievements in self-supervised learning for video tasks. Recent efforts typically adopt the Masked Video Modeling (MVM) paradigm, leading to significant progress on multiple video tasks. However, two critical challenges remain: 1) Without human annotations, the random temporal sampling introduces uncertainty, increasing the difficulty of model training. 2) Previous MVM methods primarily recover the masked patches in the pixel space, leading to insufficient information compression for downstream tasks. To address these challenges jointly, we propose a self-supervised framework that leverages Temporal Correspondence for video Representation learning (T-CoRe). For challenge 1), we propose a sandwich sampling strategy that selects two auxiliary frames to reduce reconstruction uncertainty in a two-side-squeezing manner. Addressing challenge 2), we introduce an auxiliary branch into a self-distillation architecture to restore representations in the latent space, generating high-level semantic representations enriched with temporal information. Experiments of T-CoRe consistently present superior performance across several downstream tasks, demonstrating its effectiveness for video representation learning. The code is available at https://github.com/yafeng19/T-CORE.
Aligning Information Capacity Between Vision and Language via Dense-to-Sparse Feature Distillation for Image-Text Matching
Mar 19, 2025Enabling Visual Semantic Models to effectively handle multi-view description matching has been a longstanding challenge. Existing methods typically learn a set of embeddings to find the optimal match for each view's text and compute similarity. However, the visual and text embeddings learned through these approaches have limited information capacity and are prone to interference from locally similar negative samples. To address this issue, we argue that the information capacity of embeddings is crucial and propose Dense-to-Sparse Feature Distilled Visual Semantic Embedding (D2S-VSE), which enhances the information capacity of sparse text by leveraging dense text distillation. Specifically, D2S-VSE is a two-stage framework. In the pre-training stage, we align images with dense text to enhance the information capacity of visual semantic embeddings. In the fine-tuning stage, we optimize two tasks simultaneously, distilling dense text embeddings to sparse text embeddings while aligning images and sparse texts, enhancing the information capacity of sparse text embeddings. Our proposed D2S-VSE model is extensively evaluated on the large-scale MS-COCO and Flickr30K datasets, demonstrating its superiority over recent state-of-the-art methods.
CoSpace: Benchmarking Continuous Space Perception Ability for Vision-Language Models
Mar 18, 2025Vision-Language Models (VLMs) have recently witnessed significant progress in visual comprehension. As the permitting length of image context grows, VLMs can now comprehend a broader range of views and spaces. Current benchmarks provide insightful analysis of VLMs in tasks involving complex visual instructions following, multi-image understanding and spatial reasoning. However, they usually focus on spatially irrelevant images or discrete images captured from varied viewpoints. The compositional characteristic of images captured from a static viewpoint remains underestimated. We term this characteristic as Continuous Space Perception. When observing a scene from a static viewpoint while shifting orientations, it produces a series of spatially continuous images, enabling the reconstruction of the entire space. In this paper, we present CoSpace, a multi-image visual understanding benchmark designed to assess the Continuous Space perception ability for VLMs. CoSpace contains 2,918 images and 1,626 question-answer pairs, covering seven types of tasks. We conduct evaluation across 19 proprietary and open-source VLMs. Results reveal that there exist pitfalls on the continuous space perception ability for most of the evaluated models, including proprietary ones. Interestingly, we find that the main discrepancy between open-source and proprietary models lies not in accuracy but in the consistency of responses. We believe that enhancing the ability of continuous space perception is essential for VLMs to perform effectively in real-world tasks and encourage further research to advance this capability.
Evolution-based Region Adversarial Prompt Learning for Robustness Enhancement in Vision-Language Models
Mar 17, 2025



Large pre-trained vision-language models (VLMs), such as CLIP, demonstrate impressive generalization but remain highly vulnerable to adversarial examples (AEs). Previous work has explored robust text prompts through adversarial training, achieving some improvement in both robustness and generalization. However, they primarily rely on singlegradient direction perturbations (e.g., PGD) to generate AEs, which lack diversity, resulting in limited improvement in adversarial robustness. To address these limitations, we propose an evolution-based region adversarial prompt tuning method called ER-APT, which combines gradient methods with genetic evolution to generate more diverse and challenging AEs. In each training iteration, we first generate AEs using traditional gradient-based methods. Subsequently, a genetic evolution mechanism incorporating selection, mutation, and crossover is applied to optimize the AEs, ensuring a broader and more aggressive perturbation distribution.The final evolved AEs are used for prompt tuning, achieving region-based adversarial optimization instead of conventional single-point adversarial prompt tuning. We also propose a dynamic loss weighting method to adjust prompt learning efficiency for accuracy and robustness. Experimental evaluations on various benchmark datasets demonstrate the superiority of our proposed method, outperforming stateof-the-art APT methods. The code is released at https://github.com/jiaxiaojunQAQ/ER-APT.
ROS-SAM: High-Quality Interactive Segmentation for Remote Sensing Moving Object
Mar 15, 2025



The availability of large-scale remote sensing video data underscores the importance of high-quality interactive segmentation. However, challenges such as small object sizes, ambiguous features, and limited generalization make it difficult for current methods to achieve this goal. In this work, we propose ROS-SAM, a method designed to achieve high-quality interactive segmentation while preserving generalization across diverse remote sensing data. The ROS-SAM is built upon three key innovations: 1) LoRA-based fine-tuning, which enables efficient domain adaptation while maintaining SAM's generalization ability, 2) Enhancement of deep network layers to improve the discriminability of extracted features, thereby reducing misclassifications, and 3) Integration of global context with local boundary details in the mask decoder to generate high-quality segmentation masks. Additionally, we design the data pipeline to ensure the model learns to better handle objects at varying scales during training while focusing on high-quality predictions during inference. Experiments on remote sensing video datasets show that the redesigned data pipeline boosts the IoU by 6%, while ROS-SAM increases the IoU by 13%. Finally, when evaluated on existing remote sensing object tracking datasets, ROS-SAM demonstrates impressive zero-shot capabilities, generating masks that closely resemble manual annotations. These results confirm ROS-SAM as a powerful tool for fine-grained segmentation in remote sensing applications. Code is available at https://github.com/ShanZard/ROS-SAM.