 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Bayesian Optimization Framework for Instruction Tuning in Partial Differential Equation Discovery
Dec 31, 2025Large Language Models (LLMs) show promise for equation discovery, yet their outputs are highly sensitive to prompt phrasing, a phenomenon we term instruction brittleness. Static prompts cannot adapt to the evolving state of a multi-step generation process, causing models to plateau at suboptimal solutions. To address this, we propose NeuroSymBO, which reframes prompt engineering as a sequential decision problem. Our method maintains a discrete library of reasoning strategies and uses Bayesian Optimization to select the optimal instruction at each step based on numerical feedback. Experiments on PDE discovery benchmarks show that adaptive instruction selection significantly outperforms fixed prompts, achieving higher recovery rates with more parsimonious solutions.
ReFRM3D: A Radiomics-enhanced Fused Residual Multiparametric 3D Network with Multi-Scale Feature Fusion for Glioma Characterization
Dec 27, 2025Gliomas are among the most aggressive cancers, characterized by high mortality rates and complex diagnostic processes. Existing studies on glioma diagnosis and classification often describe issues such as high variability in imaging data, inadequate optimization of computational resources, and inefficient segmentation and classification of gliomas. To address these challenges, we propose novel techniques utilizing multi-parametric MRI data to enhance tumor segmentation and classification efficiency. Our work introduces the first-ever radiomics-enhanced fused residual multiparametric 3D network (ReFRM3D) for brain tumor characterization, which is based on a 3D U-Net architecture and features multi-scale feature fusion, hybrid upsampling, and an extended residual skip mechanism. Additionally, we propose a multi-feature tumor marker-based classifier that leverages radiomic features extracted from the segmented regions. Experimental results demonstrate significant improvements in segmentation performance across the BraTS2019, BraTS2020, and BraTS2021 datasets, achieving high Dice Similarity Coefficients (DSC) of 94.04%, 92.68%, and 93.64% for whole tumor (WT), enhancing tumor (ET), and tumor core (TC) respectively in BraTS2019; 94.09%, 92.91%, and 93.84% in BraTS2020; and 93.70%, 90.36%, and 92.13% in BraTS2021.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Collaborative Group-Aware Hashing for Fast Recommender Systems
Dec 23, 2025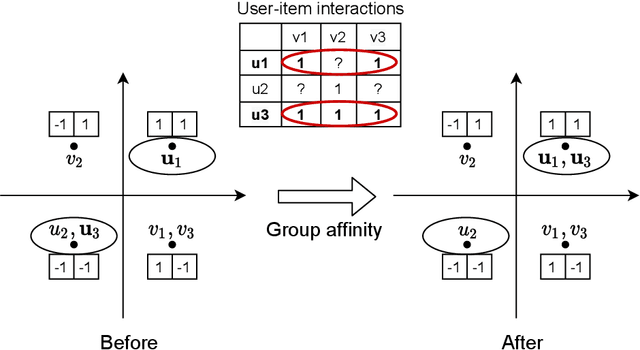

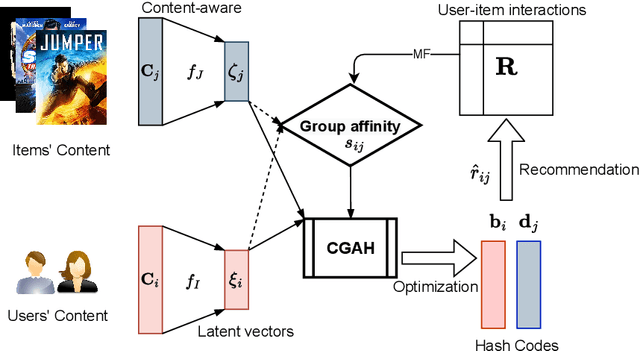
The fast online recommendation is critical for applications with large-scale databases; meanwhile, it is challenging to provide accurate recommendations in sparse scenarios. Hash technique has shown its superiority for speeding up the online recommendation by bit operations on Hamming distance computations. However, existing hashing-based recommendations suffer from low accuracy, especially with sparse settings, due to the limited representation capability of each bit and neglected inherent relations among users and items. To this end, this paper lodges a Collaborative Group-Aware Hashing (CGAH) method for both collaborative filtering (namely CGAH-CF) and content-aware recommendations (namely CGAH) by integrating the inherent group information to alleviate the sparse issue. Firstly, we extract inherent group affinities of users and items by classifying their latent vectors into different groups. Then, the preference is formulated as the inner product of the group affinity and the similarity of hash codes. By learning hash codes with the inherent group information, CGAH obtains more effective hash codes than other discrete methods with sparse interactive data. Extensive experiments on three public datasets show the superior performance of our proposed CGAH and CGAH-CF over the state-of-the-art discrete collaborative filtering methods and discrete content-aware recommendations under different sparse settings.
SketchAssist: A Practical Assistant for Semantic Edits and Precise Local Redrawing
Dec 16, 2025



Sketch editing is central to digital illustration, yet existing image editing systems struggle to preserve the sparse, style-sensitive structure of line art while supporting both high-level semantic changes and precise local redrawing. We present SketchAssist, an interactive sketch drawing assistant that accelerates creation by unifying instruction-guided global edits with line-guided region redrawing, while keeping unrelated regions and overall composition intact. To enable this assistant at scale, we introduce a controllable data generation pipeline that (i) constructs attribute-addition sequences from attribute-free base sketches, (ii) forms multi-step edit chains via cross-sequence sampling, and (iii) expands stylistic coverage with a style-preserving attribute-removal model applied to diverse sketches. Building on this data, SketchAssist employs a unified sketch editing framework with minimal changes to DiT-based editors. We repurpose the RGB channels to encode the inputs, enabling seamless switching between instruction-guided edits and line-guided redrawing within a single input interface. To further specialize behavior across modes, we integrate a task-guided mixture-of-experts into LoRA layers, routing by text and visual cues to improve semantic controllability, structural fidelity, and style preservation. Extensive experiments show state-of-the-art results on both tasks, with superior instruction adherence and style/structure preservation compared to recent baselines. Together, our dataset and SketchAssist provide a practical, controllable assistant for sketch creation and revision.
FID-Net: A Feature-Enhanced Deep Learning Network for Forest Infestation Detection
Dec 15, 2025Forest pests threaten ecosystem stability, requiring efficient monitoring. To overcome the limitations of traditional methods in large-scale, fine-grained detection, this study focuses on accurately identifying infected trees and analyzing infestation patterns. We propose FID-Net, a deep learning model that detects pest-affected trees from UAV visible-light imagery and enables infestation analysis via three spatial metrics. Based on YOLOv8n, FID-Net introduces a lightweight Feature Enhancement Module (FEM) to extract disease-sensitive cues, an Adaptive Multi-scale Feature Fusion Module (AMFM) to align and fuse dual-branch features (RGB and FEM-enhanced), and an Efficient Channel Attention (ECA) mechanism to enhance discriminative information efficiently. From detection results, we construct a pest situation analysis framework using: (1) Kernel Density Estimation to locate infection hotspots; (2) neighborhood evaluation to assess healthy trees' infection risk; (3) DBSCAN clustering to identify high-density healthy clusters as priority protection zones. Experiments on UAV imagery from 32 forest plots in eastern Tianshan, China, show that FID-Net achieves 86.10% precision, 75.44% recall, 82.29% mAP@0.5, and 64.30% mAP@0.5:0.95, outperforming mainstream YOLO models. Analysis confirms infected trees exhibit clear clustering, supporting targeted forest protection. FID-Net enables accurate tree health discrimination and, combined with spatial metrics, provides reliable data for intelligent pest monitoring, early warning, and precise management.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
Synergizing Code Coverage and Gameplay Intent: Coverage-Aware Game Playtesting with LLM-Guided Reinforcement Learning
Dec 14, 2025The widespread adoption of the "Games as a Service" model necessitates frequent content updates, placing immense pressure on quality assurance. In response, automated game testing has been viewed as a promising solution to cope with this demanding release cadence. However, existing automated testing approaches typically create a dichotomy: code-centric methods focus on structural coverage without understanding gameplay context, while player-centric agents validate high-level intent but often fail to cover specific underlying code changes. To bridge this gap, we propose SMART (Structural Mapping for Augmented Reinforcement Testing), a novel framework that synergizes structural verification and functional validation for game update testing. SMART leverages large language models (LLMs) to interpret abstract syntax tree (AST) differences and extract functional intent, constructing a context-aware hybrid reward mechanism. This mechanism guides reinforcement learning agents to sequentially fulfill gameplay goals while adaptively exploring modified code branches. We evaluate SMART on two environments, Overcooked and Minecraft. The results demonstrate that SMART significantly outperforms state-of-the-art baselines; it achieves over 94% branch coverage of modified code, nearly double that of traditional reinforcement learning methods, while maintaining a 98% task completion rate, effectively balancing structural comprehensiveness with functional correctness.
Geometry-Aware Scene-Consistent Image Generation
Dec 14, 2025We study geometry-aware scene-consistent image generation: given a reference scene image and a text condition specifying an entity to be generated in the scene and its spatial relation to the scene, the goal is to synthesize an output image that preserves the same physical environment as the reference scene while correctly generating the entity according to the spatial relation described in the text. Existing methods struggle to balance scene preservation with prompt adherence: they either replicate the scene with high fidelity but poor responsiveness to the prompt, or prioritize prompt compliance at the expense of scene consistency. To resolve this trade-off, we introduce two key contributions: (i) a scene-consistent data construction pipeline that generates diverse, geometrically-grounded training pairs, and (ii) a novel geometry-guided attention loss that leverages cross-view cues to regularize the model's spatial reasoning. Experiments on our scene-consistent benchmark show that our approach achieves better scene alignment and text-image consistency than state-of-the-art baselines, according to both automatic metrics and human preference studies. Our method produces geometrically coherent images with diverse compositions that remain faithful to the textual instructions and the underlying scene structure.