 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on Dead Reckoning Algorithm for Self-Propelled Pipeline Robots in Three-Dimensional Complex Pipelines
Dec 19, 2025



In the field of gas pipeline location, existing pipeline location methods mostly rely on pipeline location instruments. However, when faced with complex and curved pipeline scenarios, these methods often fail due to problems such as cable entanglement and insufficient equipment flexibility. To address this pain point, we designed a self-propelled pipeline robot. This robot can autonomously complete the location work of complex and curved pipelines in complex pipe networks without external dragging. In terms of pipeline mapping technology, traditional visual mapping and laser mapping methods are easily affected by lighting conditions and insufficient features in the confined space of pipelines, resulting in mapping drift and divergence problems. In contrast, the pipeline location method that integrates inertial navigation and wheel odometers is less affected by pipeline environmental factors. Based on this, this paper proposes a pipeline robot location method based on extended Kalman filtering (EKF). Firstly, the body attitude angle is initially obtained through an inertial measurement unit (IMU). Then, the extended Kalman filtering algorithm is used to improve the accuracy of attitude angle estimation. Finally, high-precision pipeline location is achieved by combining wheel odometers. During the testing phase, the roll wheels of the pipeline robot needed to fit tightly against the pipe wall to reduce slippage. However, excessive tightness would reduce the flexibility of motion control due to excessive friction. Therefore, a balance needed to be struck between the robot's motion capability and positioning accuracy. Experiments were conducted using the self-propelled pipeline robot in a rectangular loop pipeline, and the results verified the effectiveness of the proposed dead reckoning algorithm.
Design and Research of a Self-Propelled Pipeline Robot Based on Force Analysis and Dynamic Simulation
Dec 19, 2025In pipeline inspection, traditional tethered inspection robots are severely constrained by cable length and weight, which greatly limit their travel range and accessibility. To address these issues, this paper proposes a self-propelled pipeline robot design based on force analysis and dynamic simulation, with a specific focus on solving core challenges including vertical climbing failure and poor passability in T-branch pipes. Adopting a wheeled configuration and modular design, the robot prioritizes the core demand of body motion control. Specifically, 3D modeling of the robot was first completed using SolidWorks. Subsequently, the model was imported into ADAMS for dynamic simulation, which provided a basis for optimizing the drive module and motion control strategy.To verify the robot's dynamic performance, an experimental platform with acrylic pipes was constructed. Through adjusting its body posture to surmount obstacles and select directions, the robot has demonstrated its ability to stably traverse various complex pipeline scenarios. Notably, this work offers a technical feasibility reference for the application of pipeline robots in the inspection of medium and low-pressure urban gas pipelines.
Finch: Benchmarking Finance & Accounting across Spreadsheet-Centric Enterprise Workflows
Dec 19, 2025We introduce a finance & accounting benchmark (Finch) for evaluating AI agents on real-world, enterprise-grade professional workflows -- interleaving data entry, structuring, formatting, web search, cross-file retrieval, calculation, modeling, validation, translation, visualization, and reporting. Finch is sourced from authentic enterprise workspaces at Enron (15,000 spreadsheets and 500,000 emails from 150 employees) and other financial institutions, preserving in-the-wild messiness across multimodal artifacts (text, tables, formulas, charts, code, and images) and spanning diverse domains such as budgeting, trading, and asset management. We propose a workflow construction process that combines LLM-assisted discovery with expert annotation: (1) LLM-assisted, expert-verified derivation of workflows from real-world email threads and version histories of spreadsheet files, and (2) meticulous expert annotation for workflows, requiring over 700 hours of domain-expert effort. This yields 172 composite workflows with 384 tasks, involving 1,710 spreadsheets with 27 million cells, along with PDFs and other artifacts, capturing the intrinsically messy, long-horizon, knowledge-intensive, and collaborative nature of real-world enterprise work. We conduct both human and automated evaluations of frontier AI systems including GPT 5.1, Claude Sonnet 4.5, Gemini 3 Pro, Grok 4, and Qwen 3 Max, and GPT 5.1 Pro spends 48 hours in total yet passes only 38.4% of workflows, while Claude Sonnet 4.5 passes just 25.0%. Comprehensive case studies further surface the challenges that real-world enterprise workflows pose for AI agents.
Learning by Analogy: A Causal Framework for Composition Generalization
Dec 11, 2025Compositional generalization -- the ability to understand and generate novel combinations of learned concepts -- enables models to extend their capabilities beyond limited experiences. While effective, the data structures and principles that enable this crucial capability remain poorly understood. We propose that compositional generalization fundamentally requires decomposing high-level concepts into basic, low-level concepts that can be recombined across similar contexts, similar to how humans draw analogies between concepts. For example, someone who has never seen a peacock eating rice can envision this scene by relating it to their previous observations of a chicken eating rice. In this work, we formalize these intuitive processes using principles of causal modularity and minimal changes. We introduce a hierarchical data-generating process that naturally encodes different levels of concepts and their interaction mechanisms. Theoretically, we demonstrate that this approach enables compositional generalization supporting complex relations between composed concepts, advancing beyond prior work that assumes simpler interactions like additive effects. Critically, we also prove that this latent hierarchical structure is provably recoverable (identifiable) from observable data like text-image pairs, a necessary step for learning such a generative process. To validate our theory, we apply insights from our theoretical framework and achieve significant improvements on benchmark datasets.
Towards Fine-Grained Code-Switch Speech Translation with Semantic Space Alignment
Nov 09, 2025Code-switching (CS) speech translation (ST) refers to translating speech that alternates between two or more languages into a target language text, which poses significant challenges due to the complexity of semantic modeling and the scarcity of CS data. Previous studies tend to rely on the model itself to implicitly learn semantic modeling during training, and resort to inefficient and costly manual annotations for these two challenges. To mitigate these limitations, we propose enhancing Large Language Models (LLMs) with a Mixture of Experts (MoE) speech projector, where each expert specializes in the semantic subspace of a specific language, enabling fine-grained modeling of speech features. Additionally, we introduce a multi-stage training paradigm that utilizes readily available monolingual automatic speech recognition (ASR) and monolingual ST data, facilitating speech-text alignment and improving translation capabilities. During training, we leverage a combination of language-specific loss and intra-group load balancing loss to guide the MoE speech projector in efficiently allocating tokens to the appropriate experts, across expert groups and within each group, respectively. To bridge the data gap across different training stages and improve adaptation to the CS scenario, we further employ a transition loss, enabling smooth transitions of data between stages, to effectively address the scarcity of high-quality CS speech translation data. Extensive experiments on widely used datasets demonstrate the effectiveness and generality of our approach.
TeaRAG: A Token-Efficient Agentic Retrieval-Augmented Generation Framework
Nov 07, 2025Retrieval-Augmented Generation (RAG) utilizes external knowledge to augment Large Language Models' (LLMs) reliability. For flexibility, agentic RAG employs autonomous, multi-round retrieval and reasoning to resolve queries. Although recent agentic RAG has improved via reinforcement learning, they often incur substantial token overhead from search and reasoning processes. This trade-off prioritizes accuracy over efficiency. To address this issue, this work proposes TeaRAG, a token-efficient agentic RAG framework capable of compressing both retrieval content and reasoning steps. 1) First, the retrieved content is compressed by augmenting chunk-based semantic retrieval with a graph retrieval using concise triplets. A knowledge association graph is then built from semantic similarity and co-occurrence. Finally, Personalized PageRank is leveraged to highlight key knowledge within this graph, reducing the number of tokens per retrieval. 2) Besides, to reduce reasoning steps, Iterative Process-aware Direct Preference Optimization (IP-DPO) is proposed. Specifically, our reward function evaluates the knowledge sufficiency by a knowledge matching mechanism, while penalizing excessive reasoning steps. This design can produce high-quality preference-pair datasets, supporting iterative DPO to improve reasoning conciseness. Across six datasets, TeaRAG improves the average Exact Match by 4% and 2% while reducing output tokens by 61% and 59% on Llama3-8B-Instruct and Qwen2.5-14B-Instruct, respectively. Code is available at https://github.com/Applied-Machine-Learning-Lab/TeaRAG.
SelfAug: Mitigating Catastrophic Forgetting in Retrieval-Augmented Generation via Distribution Self-Alignment
Sep 04, 2025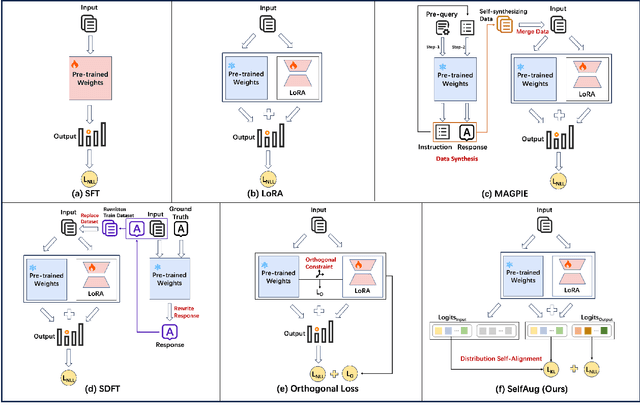
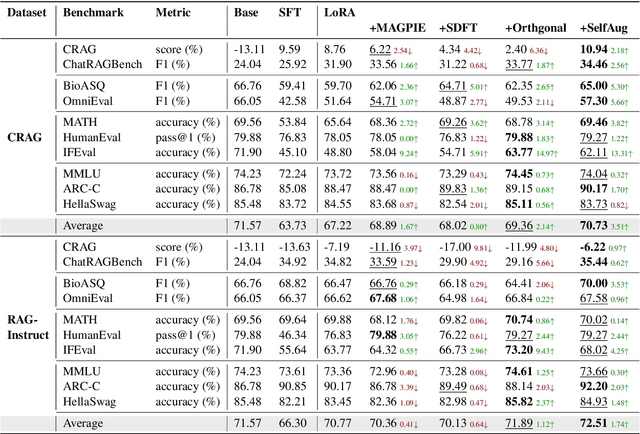
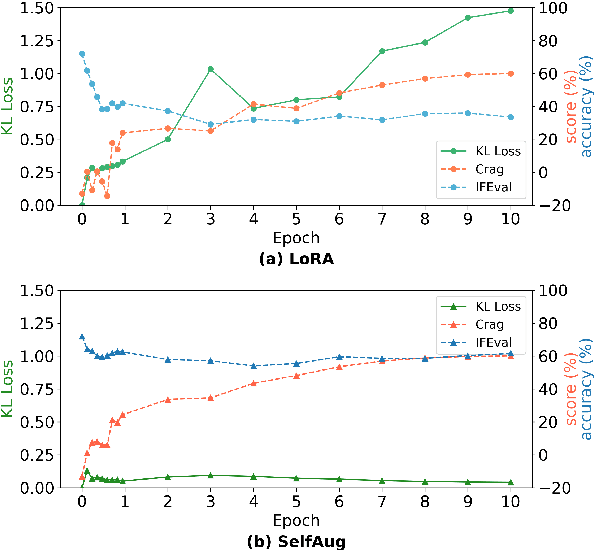
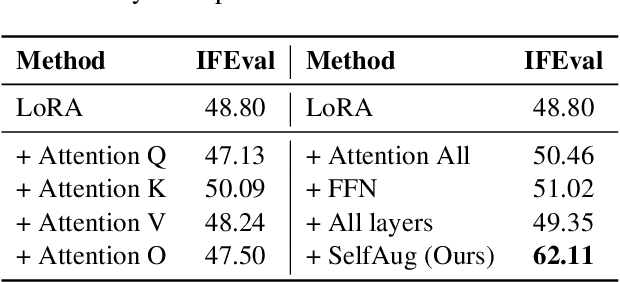
Recent advancements in large language models (LLMs) have revolutionized natural language processing through their remarkable capabilities in understanding and executing diverse tasks. While supervised fine-tuning, particularly in Retrieval-Augmented Generation (RAG) scenarios, effectively enhances task-specific performance, it often leads to catastrophic forgetting, where models lose their previously acquired knowledge and general capabilities. Existing solutions either require access to general instruction data or face limitations in preserving the model's original distribution. To overcome these limitations, we propose SelfAug, a self-distribution alignment method that aligns input sequence logits to preserve the model's semantic distribution, thereby mitigating catastrophic forgetting and improving downstream performance. Extensive experiments demonstrate that SelfAug achieves a superior balance between downstream learning and general capability retention. Our comprehensive empirical analysis reveals a direct correlation between distribution shifts and the severity of catastrophic forgetting in RAG scenarios, highlighting how the absence of RAG capabilities in general instruction tuning leads to significant distribution shifts during fine-tuning. Our findings not only advance the understanding of catastrophic forgetting in RAG contexts but also provide a practical solution applicable across diverse fine-tuning scenarios. Our code is publicly available at https://github.com/USTC-StarTeam/SelfAug.
WideSearch: Benchmarking Agentic Broad Info-Seeking
Aug 11, 2025From professional research to everyday planning, many tasks are bottlenecked by wide-scale information seeking, which is more repetitive than cognitively complex. With the rapid development of Large Language Models (LLMs), automated search agents powered by LLMs offer a promising solution to liberate humans from this tedious work. However, the capability of these agents to perform such "wide-context" collection reliably and completely remains largely unevaluated due to a lack of suitable benchmarks. To bridge this gap, we introduce WideSearch, a new benchmark engineered to evaluate agent reliability on these large-scale collection tasks. The benchmark features 200 manually curated questions (100 in English, 100 in Chinese) from over 15 diverse domains, grounded in real user queries. Each task requires agents to collect large-scale atomic information, which could be verified one by one objectively, and arrange it into a well-organized output. A rigorous five-stage quality control pipeline ensures the difficulty, completeness, and verifiability of the dataset. We benchmark over 10 state-of-the-art agentic search systems, including single-agent, multi-agent frameworks, and end-to-end commercial systems. Most systems achieve overall success rates near 0\%, with the best performer reaching just 5\%. However, given sufficient time, cross-validation by multiple human testers can achieve a near 100\% success rate. These results demonstrate that present search agents have critical deficiencies in large-scale information seeking, underscoring urgent areas for future research and development in agentic search. Our dataset, evaluation pipeline, and benchmark results have been publicly released at https://widesearch-seed.github.io/
Multi-modal Relational Item Representation Learning for Inferring Substitutable and Complementary Items
Jul 29, 2025We introduce a novel self-supervised multi-modal relational item representation learning framework designed to infer substitutable and complementary items. Existing approaches primarily focus on modeling item-item associations deduced from user behaviors using graph neural networks (GNNs) or leveraging item content information. However, these methods often overlook critical challenges, such as noisy user behavior data and data sparsity due to the long-tailed distribution of these behaviors. In this paper, we propose MMSC, a self-supervised multi-modal relational item representation learning framework to address these challenges. Specifically, MMSC consists of three main components: (1) a multi-modal item representation learning module that leverages a multi-modal foundational model and learns from item metadata, (2) a self-supervised behavior-based representation learning module that denoises and learns from user behavior data, and (3) a hierarchical representation aggregation mechanism that integrates item representations at both the semantic and task levels. Additionally, we leverage LLMs to generate augmented training data, further enhancing the denoising process during training. We conduct extensive experiments on five real-world datasets, showing that MMSC outperforms existing baselines by 26.1% for substitutable recommendation and 39.2% for complementary recommendation. In addition, we empirically show that MMSC is effective in modeling cold-start items.
Plan Your Travel and Travel with Your Plan: Wide-Horizon Planning and Evaluation via LLM
Jun 14, 2025Travel planning is a complex task requiring the integration of diverse real-world information and user preferences. While LLMs show promise, existing methods with long-horizon thinking struggle with handling multifaceted constraints and preferences in the context, leading to suboptimal itineraries. We formulate this as an $L^3$ planning problem, emphasizing long context, long instruction, and long output. To tackle this, we introduce Multiple Aspects of Planning (MAoP), enabling LLMs to conduct wide-horizon thinking to solve complex planning problems. Instead of direct planning, MAoP leverages the strategist to conduct pre-planning from various aspects and provide the planning blueprint for planning models, enabling strong inference-time scalability for better performance. In addition, current benchmarks overlook travel's dynamic nature, where past events impact subsequent journeys, failing to reflect real-world feasibility. To address this, we propose Travel-Sim, an agent-based benchmark assessing plans via real-world travel simulation. This work advances LLM capabilities in complex planning and offers novel insights for evaluating sophisticated scenarios through agent-based simulation.