 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaSelection: Accelerating Deep Learning Training through Data Subsampling
Jun 19, 2023



In this paper, we introduce AdaSelection, an adaptive sub-sampling method to identify the most informative sub-samples within each minibatch to speed up the training of large-scale deep learning models without sacrificing model performance. Our method is able to flexibly combines an arbitrary number of baseline sub-sampling methods incorporating the method-level importance and intra-method sample-level importance at each iteration. The standard practice of ad-hoc sampling often leads to continuous training with vast amounts of data from production environments. To improve the selection of data instances during forward and backward passes, we propose recording a constant amount of information per instance from these passes. We demonstrate the effectiveness of our method by testing it across various types of inputs and tasks, including the classification tasks on both image and language datasets, as well as regression tasks. Compared with industry-standard baselines, AdaSelection consistently displays superior performance.
Learning Prototype-oriented Set Representations for Meta-Learning
Oct 18, 2021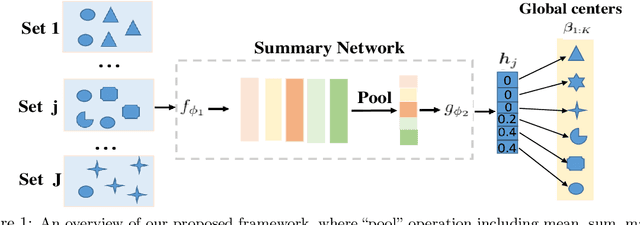

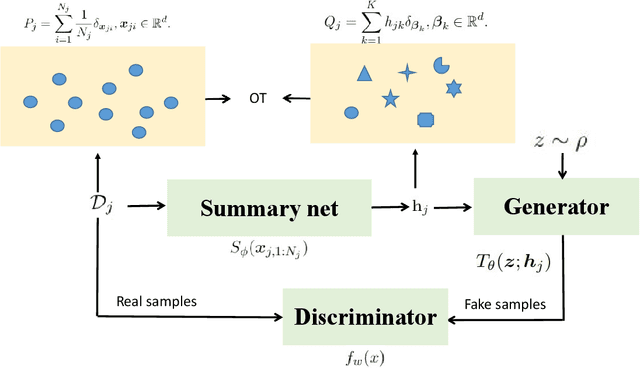
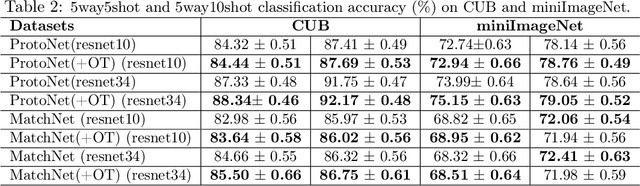
Learning from set-structured data is a fundamental problem that has recently attracted increasing attention, where a series of summary networks are introduced to deal with the set input. In fact, many meta-learning problems can be treated as set-input tasks. Most existing summary networks aim to design different architectures for the input set in order to enforce permutation invariance. However, scant attention has been paid to the common cases where different sets in a meta-distribution are closely related and share certain statistical properties. Viewing each set as a distribution over a set of global prototypes, this paper provides a novel optimal transport (OT) based way to improve existing summary networks. To learn the distribution over the global prototypes, we minimize its OT distance to the set empirical distribution over data points, providing a natural unsupervised way to improve the summary network. Since our plug-and-play framework can be applied to many meta-learning problems, we further instantiate it to the cases of few-shot classification and implicit meta generative modeling. Extensive experiments demonstrate that our framework significantly improves the existing summary networks on learning more powerful summary statistics from sets and can be successfully integrated into metric-based few-shot classification and generative modeling applications, providing a promising tool for addressing set-input and meta-learning problems.
Solar Radiation Anomaly Events Modeling Using Spatial-Temporal Mutually Interactive Processes
Jan 27, 2021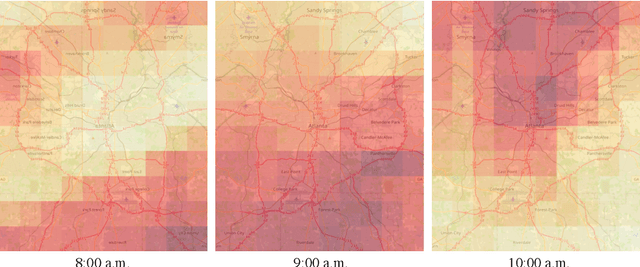

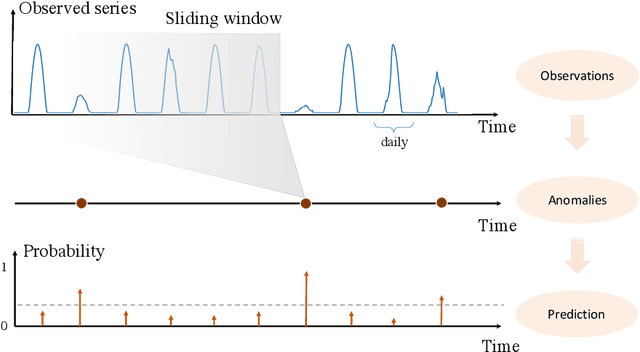

Modeling and predicting solar events, in particular, the solar ramping event is critical for improving situational awareness for solar power generation systems. Solar ramping events are significantly impacted by weather conditions such as temperature, humidity, and cloud density. Discovering the correlation between different locations and times is a highly challenging task since the system is complex and noisy. We propose a novel method to model and predict ramping events from spatial-temporal sequential solar radiation data based on a spatio-temporal interactive Bernoulli process. We demonstrate the good performance of our approach on real solar radiation datasets.
Goodness-of-Fit Test for Self-Exciting Processes
Jun 16, 2020
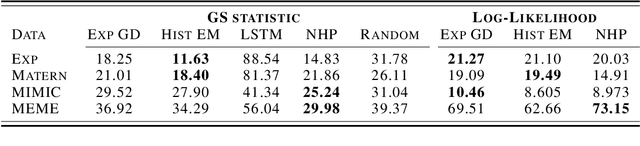

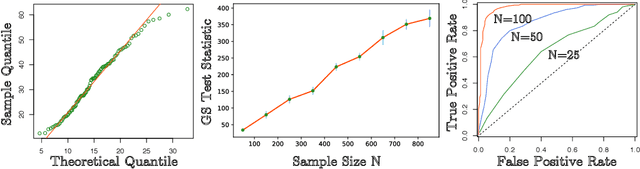
Recently there have been many research efforts in developing generative models for self-exciting point processes, partly due to their broad applicability for real-world applications, notably self- and mutual- exciting point processes. However, rarely can we quantify how well the generative model captures the nature or ground-truth since it is usually unknown. The challenge typically lies in the fact that the generative models typically provide, at most, good approximations to the ground-truth (e.g., through the rich representative power of neural networks), but they cannot be precisely the ground-truth. We thus cannot use the classic goodness-of-fit test framework to evaluate their performance. In this paper, we provide goodness-of-fit tests for generative models by leveraging a new connection of this problem with the classical statistical theory of mismatched maximum-likelihood estimator (MLE). We present a non-parametric self-normalizing test statistic for the goodness-of-fit test based on Generalized Score (GS) statistics. We further establish asymptotic properties for MLE of the Quasi-model (Quasi-MLE), asymptotic $\chi^2$ null distribution and power function of GS statistic. Numerical experiments validate the asymptotic null distribution as well as the consistency of our proposed GS test.
Distributionally Robust $k$-Nearest Neighbors for Few-Shot Learning
Jun 07, 2020
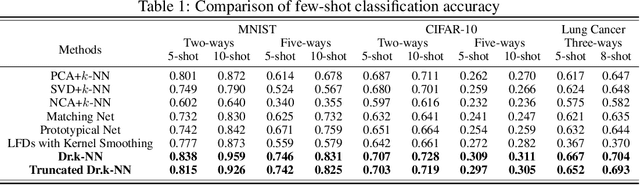
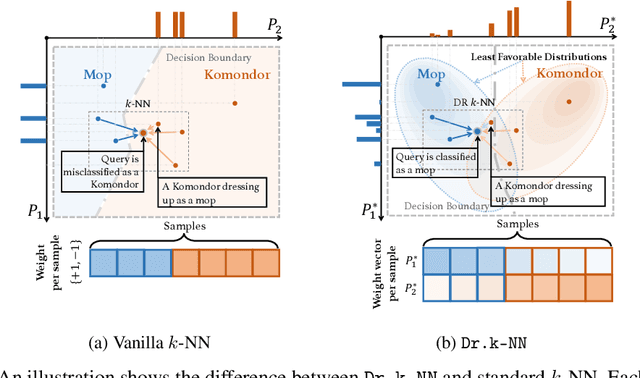
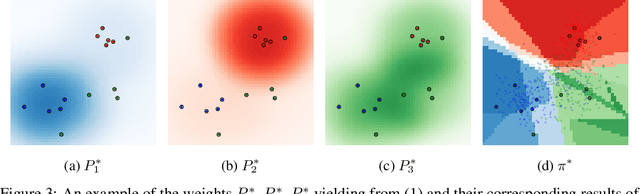
Learning a robust classifier from a few samples remains a key challenge in machine learning. A major thrust of research in few-shot classification has been based on metric learning to capture similarities between samples and then perform the $k$-nearest neighbor algorithm. To make such an algorithm more robust, in this paper, we propose a distributionally robust $k$-nearest neighbor algorithm Dr.k-NN, which features assigning minimax optimal weights to training samples when performing classification. We also couple it with neural-network-based feature embedding. We demonstrate the competitive performance of our algorithm comparing to the state-of-the-art in the few-shot learning setting with various real-data experiments.
Spatio-Temporal Point Processes with Attention for Traffic Congestion Event Modeling
May 15, 2020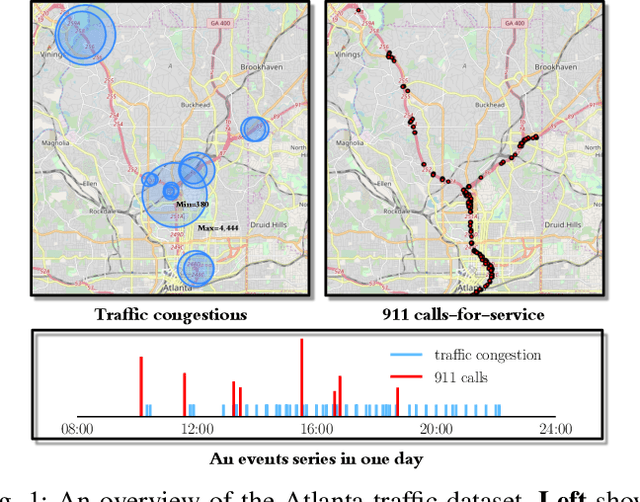
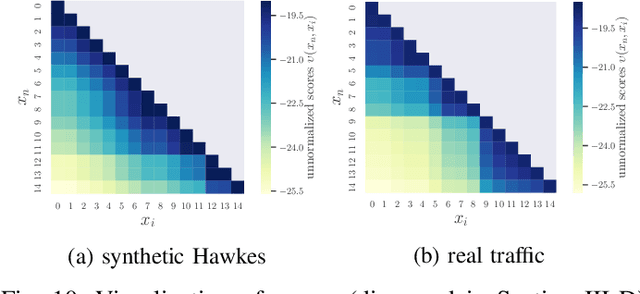

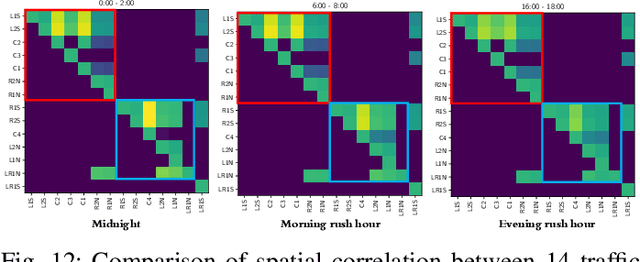
We present a novel framework for modeling traffic congestion events over road networks based on new mutually exciting spatio-temporal point process models with attention mechanisms and neural network embeddings. Using multi-modal data by combining count data from traffic sensors with police reports that report traffic incidents, we aim to capture two types of triggering effect for congestion events. Current traffic congestion at one location may cause future congestion over the road network, and traffic incidents may cause spread traffic congestion. To capture the non-homogeneous temporal dependence of the event on the past, we introduce a novel attention-based mechanism based on neural networks embedding for the point process model. To incorporate the directional spatial dependence induced by the road network, we adapt the "tail-up" model from the context of spatial statistics to the traffic network setting. We demonstrate the superior performance of our approach compared to the state-of-the-art methods for both synthetic and real data.
Deep Attention Spatio-Temporal Point Processes
Feb 20, 2020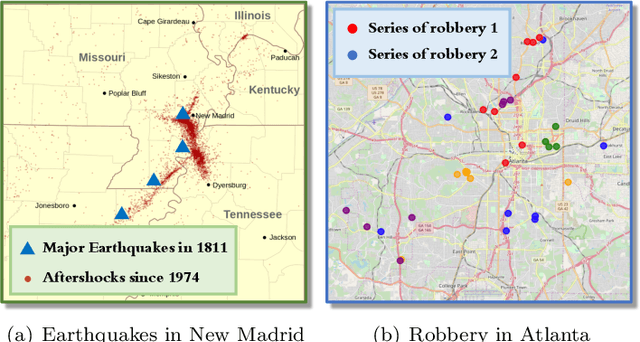
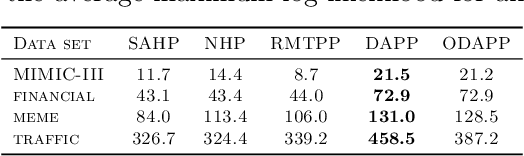
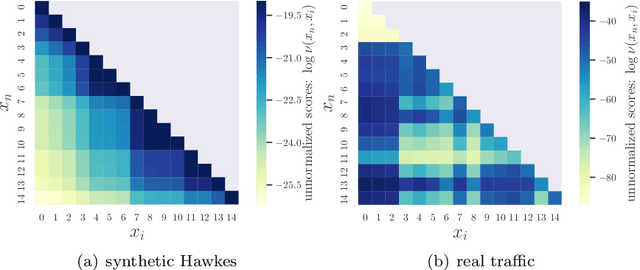
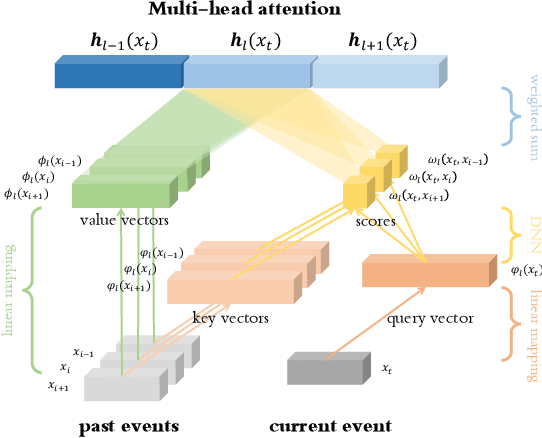
We present a novel attention-based sequential model for mutually dependent spatio-temporal discrete event data, which is a versatile framework for capturing the non-homogeneous influence of events. We go beyond the assumption that the influence of the historical event (causing an upper-ward or downward jump in the intensity function) will fade monotonically over time, which is a key assumption made by many widely-used point process models, including those based on Recurrent Neural Networks (RNNs). We borrow the idea from the attention model based on a probabilistic score function, which leads to a flexible representation of the intensity function and is highly interpretable. We demonstrate the superior performance of our approach compared to the state-of-the-art for both synthetic and real data.
Online Community Detection by Spectral CUSUM
Oct 20, 2019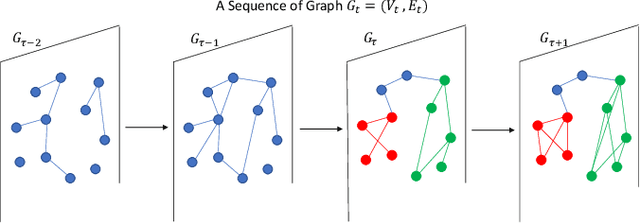
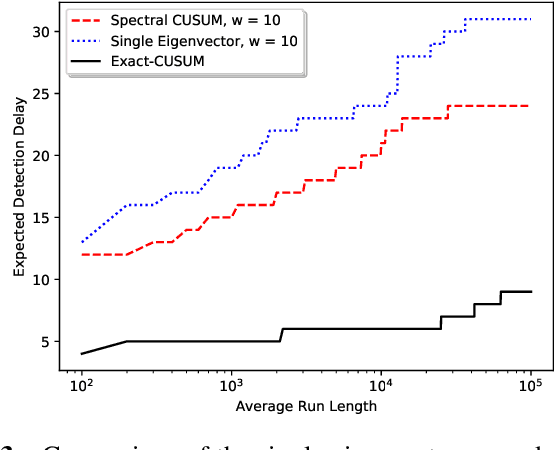
We present an online community change detection algorithm called spectral CUSUM to detect the emergence of a community using a subspace projection procedure based on a Gaussian model setting. Theoretical analysis is provided to characterize the average run length (ARL) and expected detection delay (EDD), as well as the asymptotic optimality. Simulation and real data examples demonstrate the good performance of the proposed method.