 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioral Feature Boosting via Substitute Relationships for E-commerce Search
Feb 16, 2026On E-commerce platforms, new products often suffer from the cold-start problem: limited interaction data reduces their search visibility and hurts relevance ranking. To address this, we propose a simple yet effective behavior feature boosting method that leverages substitute relationships among products (BFS). BFS identifies substitutes-products that satisfy similar user needs-and aggregates their behavioral signals (e.g., clicks, add-to-carts, purchases, and ratings) to provide a warm start for new items. Incorporating these enriched signals into ranking models mitigates cold-start effects and improves relevance and competitiveness. Experiments on a large E-commerce platform, both offline and online, show that BFS significantly improves search relevance and product discovery for cold-start products. BFS is scalable and practical, improving user experience while increasing exposure for newly launched items in E-commerce search. The BFS-enhanced ranking model has been launched in production and has served customers since 2025.
Finite-Time Convergence and Sample Complexity of Actor-Critic Multi-Objective Reinforcement Learning
May 05, 2024



Reinforcement learning with multiple, potentially conflicting objectives is pervasive in real-world applications, while this problem remains theoretically under-explored. This paper tackles the multi-objective reinforcement learning (MORL) problem and introduces an innovative actor-critic algorithm named MOAC which finds a policy by iteratively making trade-offs among conflicting reward signals. Notably, we provide the first analysis of finite-time Pareto-stationary convergence and corresponding sample complexity in both discounted and average reward settings. Our approach has two salient features: (a) MOAC mitigates the cumulative estimation bias resulting from finding an optimal common gradient descent direction out of stochastic samples. This enables provable convergence rate and sample complexity guarantees independent of the number of objectives; (b) With proper momentum coefficient, MOAC initializes the weights of individual policy gradients using samples from the environment, instead of manual initialization. This enhances the practicality and robustness of our algorithm. Finally, experiments conducted on a real-world dataset validate the effectiveness of our proposed method.
Federated Multi-Objective Learning
Oct 15, 2023



In recent years, multi-objective optimization (MOO) emerges as a foundational problem underpinning many multi-agent multi-task learning applications. However, existing algorithms in MOO literature remain limited to centralized learning settings, which do not satisfy the distributed nature and data privacy needs of such multi-agent multi-task learning applications. This motivates us to propose a new federated multi-objective learning (FMOL) framework with multiple clients distributively and collaboratively solving an MOO problem while keeping their training data private. Notably, our FMOL framework allows a different set of objective functions across different clients to support a wide range of applications, which advances and generalizes the MOO formulation to the federated learning paradigm for the first time. For this FMOL framework, we propose two new federated multi-objective optimization (FMOO) algorithms called federated multi-gradient descent averaging (FMGDA) and federated stochastic multi-gradient descent averaging (FSMGDA). Both algorithms allow local updates to significantly reduce communication costs, while achieving the {\em same} convergence rates as those of the their algorithmic counterparts in the single-objective federated learning. Our extensive experiments also corroborate the efficacy of our proposed FMOO algorithms.
AdaSelection: Accelerating Deep Learning Training through Data Subsampling
Jun 19, 2023



In this paper, we introduce AdaSelection, an adaptive sub-sampling method to identify the most informative sub-samples within each minibatch to speed up the training of large-scale deep learning models without sacrificing model performance. Our method is able to flexibly combines an arbitrary number of baseline sub-sampling methods incorporating the method-level importance and intra-method sample-level importance at each iteration. The standard practice of ad-hoc sampling often leads to continuous training with vast amounts of data from production environments. To improve the selection of data instances during forward and backward passes, we propose recording a constant amount of information per instance from these passes. We demonstrate the effectiveness of our method by testing it across various types of inputs and tasks, including the classification tasks on both image and language datasets, as well as regression tasks. Compared with industry-standard baselines, AdaSelection consistently displays superior performance.
FairRoad: Achieving Fairness for Recommender Systems with Optimized Antidote Data
Dec 13, 2022Today, recommender systems have played an increasingly important role in shaping our experiences of digital environments and social interactions. However, as recommender systems become ubiquitous in our society, recent years have also witnessed significant fairness concerns for recommender systems. Specifically, studies have shown that recommender systems may inherit or even amplify biases from historical data, and as a result, provide unfair recommendations. To address fairness risks in recommender systems, most of the previous approaches to date are focused on modifying either the existing training data samples or the deployed recommender algorithms, but unfortunately with limited degrees of success. In this paper, we propose a new approach called fair recommendation with optimized antidote data (FairRoad), which aims to improve the fairness performances of recommender systems through the construction of a small and carefully crafted antidote dataset. Toward this end, we formulate our antidote data generation task as a mathematical optimization problem, which minimizes the unfairness of the targeted recommender systems while not disrupting the deployed recommendation algorithms. Extensive experiments show that our proposed antidote data generation algorithm significantly improve the fairness of recommender systems with a small amounts of antidote data.
Multi-Label Learning to Rank through Multi-Objective Optimization
Jul 08, 2022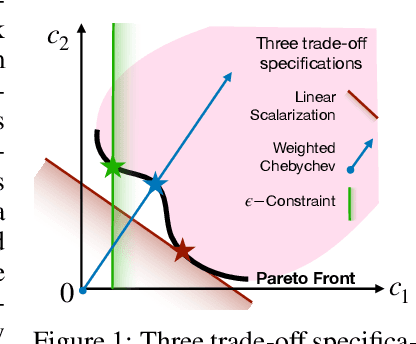
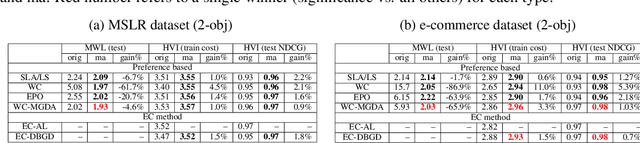
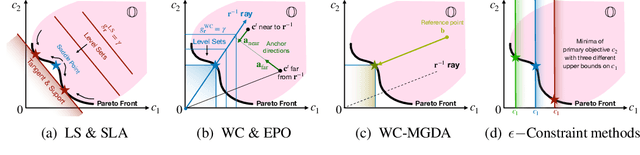
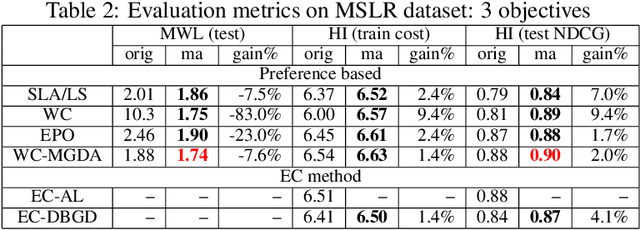
Learning to Rank (LTR) technique is ubiquitous in the Information Retrieval system nowadays, especially in the Search Ranking application. The query-item relevance labels typically used to train the ranking model are often noisy measurements of human behavior, e.g., product rating for product search. The coarse measurements make the ground truth ranking non-unique with respect to a single relevance criterion. To resolve ambiguity, it is desirable to train a model using many relevance criteria, giving rise to Multi-Label LTR (MLLTR). Moreover, it formulates multiple goals that may be conflicting yet important to optimize for simultaneously, e.g., in product search, a ranking model can be trained based on product quality and purchase likelihood to increase revenue. In this research, we leverage the Multi-Objective Optimization (MOO) aspect of the MLLTR problem and employ recently developed MOO algorithms to solve it. Specifically, we propose a general framework where the information from labels can be combined in a variety of ways to meaningfully characterize the trade-off among the goals. Our framework allows for any gradient based MOO algorithm to be used for solving the MLLTR problem. We test the proposed framework on two publicly available LTR datasets and one e-commerce dataset to show its efficacy.
Multi-objective Ranking via Constrained Optimization
Feb 13, 2020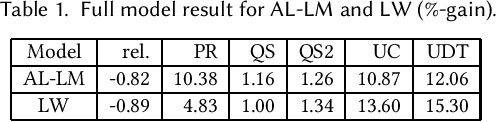
In this paper, we introduce an Augmented Lagrangian based method to incorporate the multiple objectives (MO) in a search ranking algorithm. Optimizing MOs is an essential and realistic requirement for building ranking models in production. The proposed method formulates MO in constrained optimization and solves the problem in the popular Boosting framework -- a novel contribution of our work. Furthermore, we propose a procedure to set up all optimization parameters in the problem. The experimental results show that the method successfully achieves MO criteria much more efficiently than existing methods.