 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathology Image Restoration via Mixture of Prompts
Mar 16, 2025In digital pathology, acquiring all-in-focus images is essential to high-quality imaging and high-efficient clinical workflow. Traditional scanners achieve this by scanning at multiple focal planes of varying depths and then merging them, which is relatively slow and often struggles with complex tissue defocus. Recent prevailing image restoration technique provides a means to restore high-quality pathology images from scans of single focal planes. However, existing image restoration methods are inadequate, due to intricate defocus patterns in pathology images and their domain-specific semantic complexities. In this work, we devise a two-stage restoration solution cascading a transformer and a diffusion model, to benefit from their powers in preserving image fidelity and perceptual quality, respectively. We particularly propose a novel mixture of prompts for the two-stage solution. Given initial prompt that models defocus in microscopic imaging, we design two prompts that describe the high-level image semantics from pathology foundation model and the fine-grained tissue structures via edge extraction. We demonstrate that, by feeding the prompt mixture to our method, we can restore high-quality pathology images from single-focal-plane scans, implying high potentials of the mixture of prompts to clinical usage. Code will be publicly available at https://github.com/caijd2000/MoP.
SoK: Knowledge is All You Need: Last Mile Delivery for Automated Provenance-based Intrusion Detection with LLMs
Mar 05, 2025



Recently, provenance-based intrusion detection systems (PIDSes) have been widely proposed for endpoint threat analysis. However, due to the lack of systematic integration and utilization of knowledge, existing PIDSes still require significant manual intervention for practical deployment, making full automation challenging. This paper presents a disruptive innovation by categorizing PIDSes according to the types of knowledge they utilize. In response to the prevalent issue of ``knowledge silos problem'' in existing research, we introduce a novel knowledge-driven provenance-based intrusion detection framework, powered by large language models (LLMs). We also present OmniSec, a best practice system built upon this framework. By integrating attack representation knowledge, threat intelligence knowledge, and benign behavior knowledge, OmniSec outperforms the state-of-the-art approaches on public benchmark datasets. OmniSec is available online at https://anonymous.4open.science/r/PIDS-with-LLM-613B.
Assistance or Disruption? Exploring and Evaluating the Design and Trade-offs of Proactive AI Programming Support
Feb 25, 2025AI programming tools enable powerful code generation, and recent prototypes attempt to reduce user effort with proactive AI agents, but their impact on programming workflows remains unexplored. We introduce and evaluate Codellaborator, a design probe LLM agent that initiates programming assistance based on editor activities and task context. We explored three interface variants to assess trade-offs between increasingly salient AI support: prompt-only, proactive agent, and proactive agent with presence and context (Codellaborator). In a within-subject study (N=18), we find that proactive agents increase efficiency compared to prompt-only paradigm, but also incur workflow disruptions. However, presence indicators and \revise{interaction context support} alleviated disruptions and improved users' awareness of AI processes. We underscore trade-offs of Codellaborator on user control, ownership, and code understanding, emphasizing the need to adapt proactivity to programming processes. Our research contributes to the design exploration and evaluation of proactive AI systems, presenting design implications on AI-integrated programming workflow.
Q-PETR: Quant-aware Position Embedding Transformation for Multi-View 3D Object Detection
Feb 21, 2025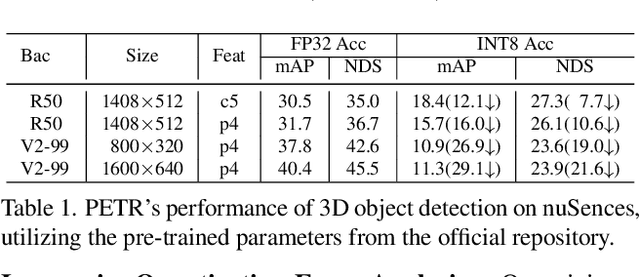

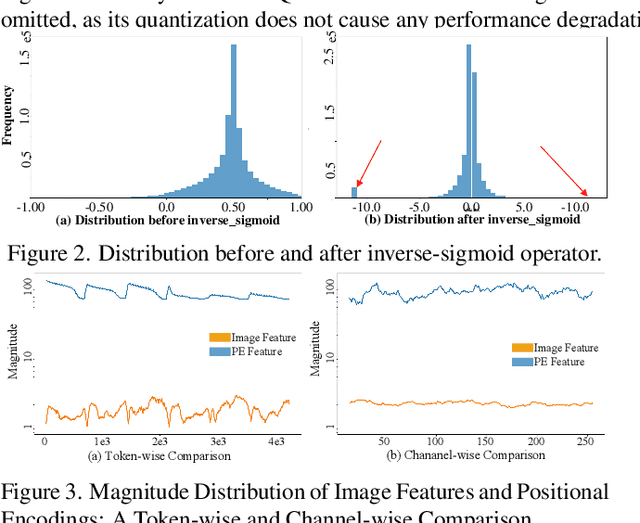
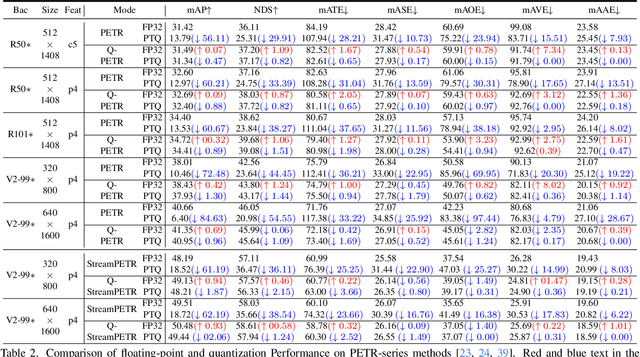
PETR-based methods have dominated benchmarks in 3D perception and are increasingly becoming a key component in modern autonomous driving systems. However, their quantization performance significantly degrades when INT8 inference is required, with a degradation of 58.2% in mAP and 36.9% in NDS on the NuScenes dataset. To address this issue, we propose a quantization-aware position embedding transformation for multi-view 3D object detection, termed Q-PETR. Q-PETR offers a quantizationfriendly and deployment-friendly architecture while preserving the original performance of PETR. It substantially narrows the accuracy gap between INT8 and FP32 inference for PETR-series methods. Without bells and whistles, our approach reduces the mAP and NDS drop to within 1% under standard 8-bit per-tensor post-training quantization. Furthermore, our method exceeds the performance of the original PETR in terms of floating-point precision. Extensive experiments across a variety of PETR-series models demonstrate its broad generalization.
Fast multi-contrast MRI using joint multiscale energy model
Jan 11, 2025The acquisition of 3D multicontrast MRI data with good isotropic spatial resolution is challenged by lengthy scan times. In this work, we introduce a CNN-based multiscale energy model to learn the joint probability distribution of the multi-contrast images. The joint recovery of the contrasts from undersampled data is posed as a maximum a posteriori estimation scheme, where the learned energy serves as the prior. We use a majorize-minimize algorithm to solve the optimization scheme. The proposed model leverages the redundancies across different contrasts to improve image fidelity. The proposed scheme is observed to preserve fine details and contrast, offering sharper reconstructions compared to reconstruction methods that independently recover the contrasts. While we focus on 3D MPNRAGE acquisitions in this work, the proposed approach is generalizable to arbitrary multi-contrast settings.
Achieving Full-Bandwidth Sensing Performance with Partial Bandwidth Allocation for ISAC
Dec 28, 2024



This letter studies an uplink integrated sensing and communication (ISAC) system using discrete Fourier transform spread orthogonal frequency division multiplexing (DFT-s-OFDM) transmission. We try to answer the following fundamental question: With only a fractional bandwidth allocated to the user with sensing task, can the same delay resolution and unambiguous range be achieved as if all bandwidth were allocated to it? We affirmatively answer the question by proposing a novel two-stage delay estimation (TSDE) method that exploits the following facts: without increasing the allocated bandwidth, higher delay resolution can be achieved via distributed subcarrier allocation compared to its collocated counterpart, while there is a trade-off between delay resolution and unambiguous range by varying the decimation factor of subcarriers. Therefore, the key idea of the proposed TSDE method is to first perform coarse delay estimation with collocated subcarriers to achieve a large unambiguous range, and then use distributed subcarriers with optimized decimation factor to enhance delay resolution while avoiding delay ambiguity. Our analysis shows that the proposed TSDE method can achieve the full-bandwidth delay resolution and unambiguous range, by using only at most half of the full bandwidth, provided that the channel delay spread is less than half of the unambiguous range. Numerical results show the superiority of the proposed method over the conventional method with collocated subcarriers.
Image Classification with Deep Reinforcement Active Learning
Dec 27, 2024



Deep learning is currently reaching outstanding performances on different tasks, including image classification, especially when using large neural networks. The success of these models is tributary to the availability of large collections of labeled training data. In many real-world scenarios, labeled data are scarce, and their hand-labeling is time, effort and cost demanding. Active learning is an alternative paradigm that mitigates the effort in hand-labeling data, where only a small fraction is iteratively selected from a large pool of unlabeled data, and annotated by an expert (a.k.a oracle), and eventually used to update the learning models. However, existing active learning solutions are dependent on handcrafted strategies that may fail in highly variable learning environments (datasets, scenarios, etc). In this work, we devise an adaptive active learning method based on Markov Decision Process (MDP). Our framework leverages deep reinforcement learning and active learning together with a Deep Deterministic Policy Gradient (DDPG) in order to dynamically adapt sample selection strategies to the oracle's feedback and the learning environment. Extensive experiments conducted on three different image classification benchmarks show superior performances against several existing active learning strategies.
Sharper Error Bounds in Late Fusion Multi-view Clustering Using Eigenvalue Proportion
Dec 24, 2024

Multi-view clustering (MVC) aims to integrate complementary information from multiple views to enhance clustering performance. Late Fusion Multi-View Clustering (LFMVC) has shown promise by synthesizing diverse clustering results into a unified consensus. However, current LFMVC methods struggle with noisy and redundant partitions and often fail to capture high-order correlations across views. To address these limitations, we present a novel theoretical framework for analyzing the generalization error bounds of multiple kernel $k$-means, leveraging local Rademacher complexity and principal eigenvalue proportions. Our analysis establishes a convergence rate of $\mathcal{O}(1/n)$, significantly improving upon the existing rate in the order of $\mathcal{O}(\sqrt{k/n})$. Building on this insight, we propose a low-pass graph filtering strategy within a multiple linear $k$-means framework to mitigate noise and redundancy, further refining the principal eigenvalue proportion and enhancing clustering accuracy. Experimental results on benchmark datasets confirm that our approach outperforms state-of-the-art methods in clustering performance and robustness. The related codes is available at https://github.com/csliangdu/GMLKM .
GSRender: Deduplicated Occupancy Prediction via Weakly Supervised 3D Gaussian Splatting
Dec 19, 2024



3D occupancy perception is gaining increasing attention due to its capability to offer detailed and precise environment representations. Previous weakly-supervised NeRF methods balance efficiency and accuracy, with mIoU varying by 5-10 points due to sampling count along camera rays. Recently, real-time Gaussian splatting has gained widespread popularity in 3D reconstruction, and the occupancy prediction task can also be viewed as a reconstruction task. Consequently, we propose GSRender, which naturally employs 3D Gaussian Splatting for occupancy prediction, simplifying the sampling process. In addition, the limitations of 2D supervision result in duplicate predictions along the same camera ray. We implemented the Ray Compensation (RC) module, which mitigates this issue by compensating for features from adjacent frames. Finally, we redesigned the loss to eliminate the impact of dynamic objects from adjacent frames. Extensive experiments demonstrate that our approach achieves SOTA (state-of-the-art) results in RayIoU (+6.0), while narrowing the gap with 3D supervision methods. Our code will be released soon.
Constraint Learning for Parametric Point Cloud
Nov 12, 2024



Parametric point clouds are sampled from CAD shapes, have become increasingly prevalent in industrial manufacturing. However, most existing point cloud learning methods focus on the geometric features, such as local and global features or developing efficient convolution operations, overlooking the important attribute of constraints inherent in CAD shapes, which limits these methods' ability to fully comprehend CAD shapes. To address this issue, we analyzed the effect of constraints, and proposed its deep learning-friendly representation, after that, the Constraint Feature Learning Network (CstNet) is developed to extract and leverage constraints. Our CstNet includes two stages. The Stage 1 extracts constraints from B-Rep data or point cloud. The Stage 2 leverages coordinates and constraints to enhance the comprehend of CAD shapes. Additionally, we built up the Parametric 20,000 Multi-modal Dataset for the scarcity of labeled B-Rep datasets. Experiments demonstrate that our CstNet achieved state-of-the-art performance on both public and proposed CAD shapes datasets. To the best of our knowledge, CstNet is the first constraint-based learning method tailored for CAD shapes analysis.