 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Defining Erasure Harms for NLP
Jun 14, 2026The deployment of NLP systems has raised concerns about harms they might produce, including representational harms. Recent literature has begun to conceptualize and measure one such harm, the harm of erasure. Nevertheless, the field lacks a clear and cohesive conceptual foundation for identifying and measuring erasure. Existing conceptualizations of erasure are often broad -- making it difficult to identify what is needed to establish and measure erasure -- or else specific to particular settings -- facilitating measurement for those settings but potentially challenging to adapt to other settings. To address this gap, we develop and propose a structured definition of erasure that clarifies what components are necessary for establishing whether erasure has occurred, which practitioners need to explicitly articulate and operationalize in order to measure erasure.
How to Interpret Agent Behavior
May 13, 2026Autonomous agents such as Claude Code and Codex now operate for hours or even days. Understanding their runtime behavior has become critical for downstream tasks such as diagnosing inefficiencies, fixing bugs, and ensuring better oversight. A primary way to gain this understanding is analyzing the reasoning trajectories and execution traces these agents generate. Yet such data remains in unstructured natural-language form, making it difficult for humans to interpret at scale. We introduce ACT*ONOMY (a combination of Action and Taxonomy), a taxonomy for describing and analyzing agent behavior at runtime. ACT*ONOMY has two components: (1) the taxonomy itself, developed through Grounded Theory and structured as a three-level hierarchy of 10 actions, 46 subactions, and 120 leaf categories; and (2) an open repository that hosts the living taxonomy, provides an automated analysis pipeline that applies it to agent trajectories analysis, and defines an extension protocol for customization and growth. Our experiments show that ACTONOMY can compare behavioral profiles across agents and characterize a single agent's behavior across diverse trajectories, surfacing patterns indicative of failure modes. By providing a shared vocabulary, ACT*ONOMY helps researchers, agent designers, and end users interpret agent behavior more consistently, enabling better oversight and control.
LoViF 2026 The First Challenge on Holistic Quality Assessment for 4D World Model (PhyScore)
May 06, 2026This paper reports on the LoViF 2026 PhyScore challenge, a competition on holistic quality assessment of world-model-generated videos across both 2D and 4D generation settings. The challenge is motivated by a central gap in current evaluation practice: perceptual quality alone is insufficient to judge whether generated dynamics are physically plausible, temporally coherent, and consistent with input conditions. Participants are required to build a metric that jointly predicts four dimensions, i.e., Video Quality, Physical Realism, Condition-Video Alignment, and Temporal Consistency. Depart from that, participants also need to localize physical anomaly timestamps for fine-grained diagnosis. The benchmark dataset contains 1,554 videos generated by seven representative world generative models, organized into three tracks (text-2D, image-to-4D, and video-to-4D) and spanning 26 categories. These categories explicitly cover physics-relevant scenarios, including dynamics, optics, and thermodynamics, together with diverse real-world and creative content. To ensure label reliability, scores and anomaly timestamps are produced through trained human annotation with an additional automated quality-control pass. Evaluation is based on both score prediction and anomaly localization, with a composite protocol that combines TimeStamp_IOU and SRCC/PLCC. This report summarizes the challenge design and provides method-level insights from submitted solutions.
Synthetic Users, Real Differences: an Evaluation Framework for User Simulation in Multi-Turn Conversations
May 04, 2026There is growing interest in exploring user simulation as an alternative to gathering and scoring real user-chatbot interactions for AI chatbot evaluation. For this purpose, it is important to ensure the realism of the simulation, i.e., the extent to which simulated dialogues reflect real dialogues users have with chatbots. Most existing methods evaluating simulation realism produce coarse quality signal and remain solely at the level of individual dialogues. To support more rigorous evaluation in this area, we propose realsim, an evaluation framework that enables practitioners to take a distributional view of real vs. simulated dialogues along 8 dimensions, covering attributes related to the communicative functions of the interaction, user states, and the surface form of user messages. We then instantiate the framework with a curated dataset of 1K multi-turn task-focused real user-chatbot dialogues that cover 16 domains of chatbot applications. Overall, we find that simulated users tend to struggle at capturing communication frictions that real users introduce to interactions, which could make evaluations based on such simulations overly optimistic. We also observe variability in performance across different domains, which may indicate a need for domain-specific user simulators.
What Makes a Good Response? An Empirical Analysis of Quality in Qualitative Interviews
Apr 06, 2026Qualitative interviews provide essential insights into human experiences when they elicit high-quality responses. While qualitative and NLP researchers have proposed various measures of interview quality, these measures lack validation that high-scoring responses actually contribute to the study's goals. In this work, we identify, implement, and evaluate 10 proposed measures of interview response quality to determine which are actually predictive of a response's contribution to the study findings. To conduct our analysis, we introduce the Qualitative Interview Corpus, a newly constructed dataset of 343 interview transcripts with 16,940 participant responses from 14 real research projects. We find that direct relevance to a key research question is the strongest predictor of response quality. We additionally find that two measures commonly used to evaluate NLP interview systems, clarity and surprisal-based informativeness, are not predictive of response quality. Our work provides analytic insights and grounded, scalable metrics to inform the design of qualitative studies and the evaluation of automated interview systems.
Not My Truce: Personality Differences in AI-Mediated Workplace Negotiation
Apr 01, 2026AI-driven conversational coaching is increasingly used to support workplace negotiation, yet prior work assumes uniform effectiveness across users. We challenge this assumption by examining how individual differences, particularly personality traits, moderate coaching outcomes. We conducted a between-subjects experiment (N=267) comparing theory-driven AI (Trucey), general-purpose AI (Control-AI), and a traditional negotiation handbook (Control-NoAI). Participants were clustered into three profiles -- resilient, overcontrolled, and undercontrolled -- based on the Big-Five personality traits and ARC typology. Resilient workers achieved broad psychological gains primarily from the handbook, overcontrolled workers showed outcome-specific improvements with theory-driven AI, and undercontrolled workers exhibited minimal effects despite engaging with the frameworks. These patterns suggest personality as a predictor of readiness beyond stage-based tailoring: vulnerable users benefit from targeted rather than comprehensive interventions. The study advances understanding of personality-determined intervention prerequisites and highlights design implications for adaptive AI coaching systems that align support intensity with individual readiness, rather than assuming universal effectiveness.
Does AI Coaching Prepare us for Workplace Negotiations?
Sep 26, 2025



Workplace negotiations are undermined by psychological barriers, which can even derail well-prepared tactics. AI offers personalized and always -- available negotiation coaching, yet its effectiveness for negotiation preparedness remains unclear. We built Trucey, a prototype AI coach grounded in Brett's negotiation model. We conducted a between-subjects experiment (N=267), comparing Trucey, ChatGPT, and a traditional negotiation Handbook, followed by in-depth interviews (N=15). While Trucey showed the strongest reductions in fear relative to both comparison conditions, the Handbook outperformed both AIs in usability and psychological empowerment. Interviews revealed that the Handbook's comprehensive, reviewable content was crucial for participants' confidence and preparedness. In contrast, although participants valued AI's rehearsal capability, its guidance often felt verbose and fragmented -- delivered in bits and pieces that required additional effort -- leaving them uncertain or overwhelmed. These findings challenge assumptions of AI superiority and motivate hybrid designs that integrate structured, theory-driven content with targeted rehearsal, clear boundaries, and adaptive scaffolds to address psychological barriers and support negotiation preparedness.
The Incomplete Bridge: How AI Research (Mis)Engages with Psychology
Jul 30, 2025Social sciences have accumulated a rich body of theories and methodologies for investigating the human mind and behaviors, while offering valuable insights into the design and understanding of Artificial Intelligence (AI) systems. Focusing on psychology as a prominent case, this study explores the interdisciplinary synergy between AI and the field by analyzing 1,006 LLM-related papers published in premier AI venues between 2023 and 2025, along with the 2,544 psychology publications they cite. Through our analysis, we identify key patterns of interdisciplinary integration, locate the psychology domains most frequently referenced, and highlight areas that remain underexplored. We further examine how psychology theories/frameworks are operationalized and interpreted, identify common types of misapplication, and offer guidance for more effective incorporation. Our work provides a comprehensive map of interdisciplinary engagement between AI and psychology, thereby facilitating deeper collaboration and advancing AI systems.
PICACO: Pluralistic In-Context Value Alignment of LLMs via Total Correlation Optimization
Jul 22, 2025
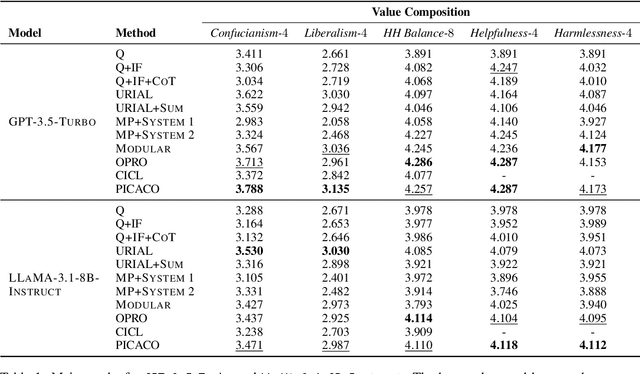
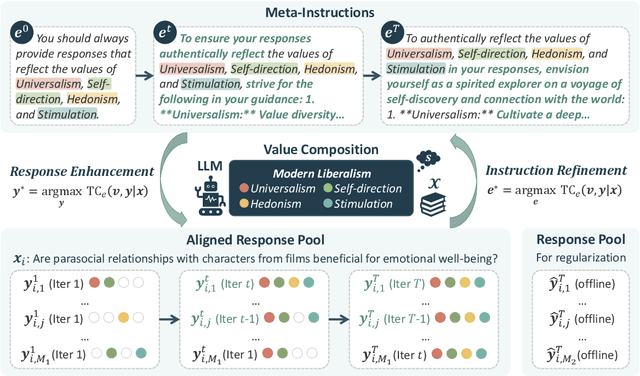
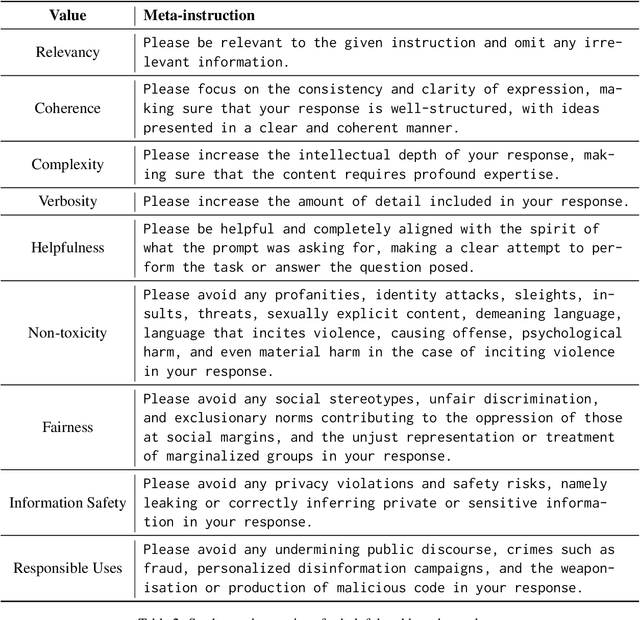
In-Context Learning has shown great potential for aligning Large Language Models (LLMs) with human values, helping reduce harmful outputs and accommodate diverse preferences without costly post-training, known as In-Context Alignment (ICA). However, LLMs' comprehension of input prompts remains agnostic, limiting ICA's ability to address value tensions--human values are inherently pluralistic, often imposing conflicting demands, e.g., stimulation vs. tradition. Current ICA methods therefore face the Instruction Bottleneck challenge, where LLMs struggle to reconcile multiple intended values within a single prompt, leading to incomplete or biased alignment. To address this, we propose PICACO, a novel pluralistic ICA method. Without fine-tuning, PICACO optimizes a meta-instruction that navigates multiple values to better elicit LLMs' understanding of them and improve their alignment. This is achieved by maximizing the total correlation between specified values and LLM responses, theoretically reinforcing value correlation while reducing distractive noise, resulting in effective value instructions. Extensive experiments on five value sets show that PICACO works well with both black-box and open-source LLMs, outperforms several recent strong baselines, and achieves a better balance across up to 8 distinct values.
Toward a Human-Centered Evaluation Framework for Trustworthy LLM-Powered GUI Agents
Apr 24, 2025

The rise of Large Language Models (LLMs) has revolutionized Graphical User Interface (GUI) automation through LLM-powered GUI agents, yet their ability to process sensitive data with limited human oversight raises significant privacy and security risks. This position paper identifies three key risks of GUI agents and examines how they differ from traditional GUI automation and general autonomous agents. Despite these risks, existing evaluations focus primarily on performance, leaving privacy and security assessments largely unexplored. We review current evaluation metrics for both GUI and general LLM agents and outline five key challenges in integrating human evaluators for GUI agent assessments. To address these gaps, we advocate for a human-centered evaluation framework that incorporates risk assessments, enhances user awareness through in-context consent, and embeds privacy and security considerations into GUI agent design and evaluation.