 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Fine-Grained Prototype Learning for Incomplete Image-Tabular Classification
Jun 03, 2026The missing-modality problem poses a significant challenge in image-tabular multimodal learning across a wide range of multimedia applications, including product understanding, recommendation systems, and medical diagnosis. This challenge is particularly pronounced when the two modalities are highly heterogeneous, as images and tabular attributes differ substantially in their semantic granularity and data distributions. Existing methods learn modality-invariant representations through disentanglement and alignment over global token-averaged features, capturing only coarse cross-modal consistency and overlooking fine-grained semantic and distributional misalignment, which hampers the exploitation of complementary cues under missing modalities. To address this, we propose DFPL, a novel framework for fine-grained prototype learning. Specifically, Shared-Specific Prototype Modeling (SSPM) extracts compact and diverse shared and modality-specific prototypes, and further performs prototype-level disentanglement to suppress redundant intra-modality correlations. Additionally, we propose a Prototype-guided Fine-grained Alignment (PFA) module that jointly enforces prototype-level distribution matching and prototype-to-class semantic alignment within a unified prototype space, thereby preserving both fine-grained distributional and semantic consistency across modalities. We further introduce a Class-aware Multi-scale Aggregation (CMA) module to adaptively aggregate shared semantics and modality-specific characteristics from global and prototype levels for robust predictions. Extensive experiments on three diverse image-tabular benchmarks demonstrate the superiority of our method compared to the previous approaches under various missing-modality settings. Code will be made publicly available.
A WDLoRA-Based Multimodal Generative Framework for Clinically Guided Corneal Confocal Microscopy Image Synthesis in Diabetic Neuropathy
Feb 14, 2026Corneal Confocal Microscopy (CCM) is a sensitive tool for assessing small-fiber damage in Diabetic Peripheral Neuropathy (DPN), yet the development of robust, automated deep learning-based diagnostic models is limited by scarce labelled data and fine-grained variability in corneal nerve morphology. Although Artificial Intelligence (AI)-driven foundation generative models excel at natural image synthesis, they often struggle in medical imaging due to limited domain-specific training, compromising the anatomical fidelity required for clinical analysis. To overcome these limitations, we propose a Weight-Decomposed Low-Rank Adaptation (WDLoRA)-based multimodal generative framework for clinically guided CCM image synthesis. WDLoRA is a parameter-efficient fine-tuning (PEFT) mechanism that decouples magnitude and directional weight updates, enabling foundation generative models to independently learn the orientation (nerve topology) and intensity (stromal contrast) required for medical realism. By jointly conditioning on nerve segmentation masks and disease-specific clinical prompts, the model synthesises anatomically coherent images across the DPN spectrum (Control, T1NoDPN, T1DPN). A comprehensive three-pillar evaluation demonstrates that the proposed framework achieves state-of-the-art visual fidelity (Fréchet Inception Distance (FID): 5.18) and structural integrity (Structural Similarity Index Measure (SSIM): 0.630), significantly outperforming GAN and standard diffusion baselines. Crucially, the synthetic images preserve gold-standard clinical biomarkers and are statistically equivalent to real patient data. When used to train automated diagnostic models, the synthetic dataset improves downstream diagnostic accuracy by 2.1% and segmentation performance by 2.2%, validating the framework's potential to alleviate data bottlenecks in medical AI.
Leveraging Persistence Image to Enhance Robustness and Performance in Curvilinear Structure Segmentation
Jan 25, 2026Segmenting curvilinear structures in medical images is essential for analyzing morphological patterns in clinical applications. Integrating topological properties, such as connectivity, improves segmentation accuracy and consistency. However, extracting and embedding such properties - especially from Persistence Diagrams (PD) - is challenging due to their non-differentiability and computational cost. Existing approaches mostly encode topology through handcrafted loss functions, which generalize poorly across tasks. In this paper, we propose PIs-Regressor, a simple yet effective module that learns persistence image (PI) - finite, differentiable representations of topological features - directly from data. Together with Topology SegNet, which fuses these features in both downsampling and upsampling stages, our framework integrates topology into the network architecture itself rather than auxiliary losses. Unlike existing methods that depend heavily on handcrafted loss functions, our approach directly incorporates topological information into the network structure, leading to more robust segmentation. Our design is flexible and can be seamlessly combined with other topology-based methods to further enhance segmentation performance. Experimental results show that integrating topological features enhances model robustness, effectively handling challenges like overexposure and blurring in medical imaging. Our approach on three curvilinear benchmarks demonstrate state-of-the-art performance in both pixel-level accuracy and topological fidelity.
StealthMark: Harmless and Stealthy Ownership Verification for Medical Segmentation via Uncertainty-Guided Backdoors
Jan 23, 2026Annotating medical data for training AI models is often costly and limited due to the shortage of specialists with relevant clinical expertise. This challenge is further compounded by privacy and ethical concerns associated with sensitive patient information. As a result, well-trained medical segmentation models on private datasets constitute valuable intellectual property requiring robust protection mechanisms. Existing model protection techniques primarily focus on classification and generative tasks, while segmentation models-crucial to medical image analysis-remain largely underexplored. In this paper, we propose a novel, stealthy, and harmless method, StealthMark, for verifying the ownership of medical segmentation models under black-box conditions. Our approach subtly modulates model uncertainty without altering the final segmentation outputs, thereby preserving the model's performance. To enable ownership verification, we incorporate model-agnostic explanation methods, e.g. LIME, to extract feature attributions from the model outputs. Under specific triggering conditions, these explanations reveal a distinct and verifiable watermark. We further design the watermark as a QR code to facilitate robust and recognizable ownership claims. We conducted extensive experiments across four medical imaging datasets and five mainstream segmentation models. The results demonstrate the effectiveness, stealthiness, and harmlessness of our method on the original model's segmentation performance. For example, when applied to the SAM model, StealthMark consistently achieved ASR above 95% across various datasets while maintaining less than a 1% drop in Dice and AUC scores, significantly outperforming backdoor-based watermarking methods and highlighting its strong potential for practical deployment. Our implementation code is made available at: https://github.com/Qinkaiyu/StealthMark.
SCR2-ST: Combine Single Cell with Spatial Transcriptomics for Efficient Active Sampling via Reinforcement Learning
Dec 15, 2025



Spatial transcriptomics (ST) is an emerging technology that enables researchers to investigate the molecular relationships underlying tissue morphology. However, acquiring ST data remains prohibitively expensive, and traditional fixed-grid sampling strategies lead to redundant measurements of morphologically similar or biologically uninformative regions, thus resulting in scarce data that constrain current methods. The well-established single-cell sequencing field, however, could provide rich biological data as an effective auxiliary source to mitigate this limitation. To bridge these gaps, we introduce SCR2-ST, a unified framework that leverages single-cell prior knowledge to guide efficient data acquisition and accurate expression prediction. SCR2-ST integrates a single-cell guided reinforcement learning-based (SCRL) active sampling and a hybrid regression-retrieval prediction network SCR2Net. SCRL combines single-cell foundation model embeddings with spatial density information to construct biologically grounded reward signals, enabling selective acquisition of informative tissue regions under constrained sequencing budgets. SCR2Net then leverages the actively sampled data through a hybrid architecture combining regression-based modeling with retrieval-augmented inference, where a majority cell-type filtering mechanism suppresses noisy matches and retrieved expression profiles serve as soft labels for auxiliary supervision. We evaluated SCR2-ST on three public ST datasets, demonstrating SOTA performance in both sampling efficiency and prediction accuracy, particularly under low-budget scenarios. Code is publicly available at: https://github.com/hrlblab/SCR2ST
PSScreen V2: Partially Supervised Multiple Retinal Disease Screening
Oct 26, 2025



In this work, we propose PSScreen V2, a partially supervised self-training framework for multiple retinal disease screening. Unlike previous methods that rely on fully labelled or single-domain datasets, PSScreen V2 is designed to learn from multiple partially labelled datasets with different distributions, addressing both label absence and domain shift challenges. To this end, PSScreen V2 adopts a three-branch architecture with one teacher and two student networks. The teacher branch generates pseudo labels from weakly augmented images to address missing labels, while the two student branches introduce novel feature augmentation strategies: Low-Frequency Dropout (LF-Dropout), which enhances domain robustness by randomly discarding domain-related low-frequency components, and Low-Frequency Uncertainty (LF-Uncert), which estimates uncertain domain variability via adversarially learned Gaussian perturbations of low-frequency statistics. Extensive experiments on multiple in-domain and out-of-domain fundus datasets demonstrate that PSScreen V2 achieves state-of-the-art performance and superior domain generalization ability. Furthermore, compatibility tests with diverse backbones, including the vision foundation model DINOv2, as well as evaluations on chest X-ray datasets, highlight the universality and adaptability of the proposed framework. The codes are available at https://github.com/boyiZheng99/PSScreen_V2.
GROK: From Quantitative Biomarkers to Qualitative Diagnosis via a Grounded MLLM with Knowledge-Guided Instruction
Oct 05, 2025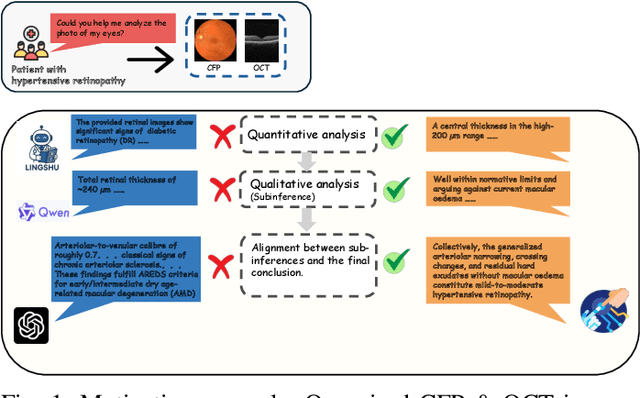
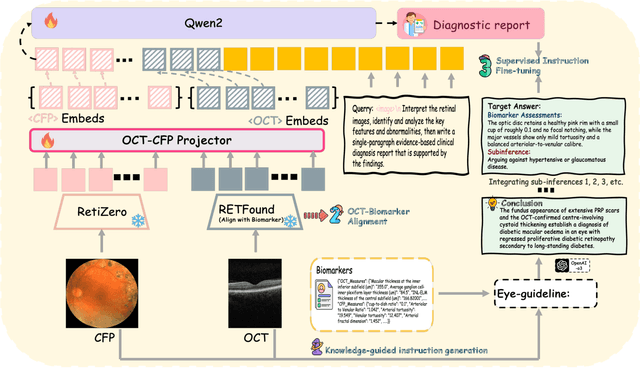
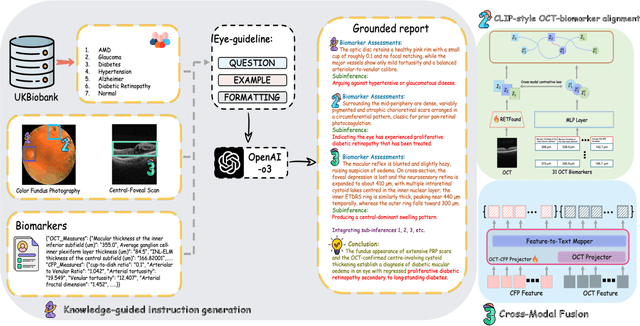

Multimodal large language models (MLLMs) hold promise for integrating diverse data modalities, but current medical adaptations such as LLaVA-Med often fail to fully exploit the synergy between color fundus photography (CFP) and optical coherence tomography (OCT), and offer limited interpretability of quantitative biomarkers. We introduce GROK, a grounded multimodal large language model that jointly processes CFP, OCT, and text to deliver clinician-grade diagnoses of ocular and systemic disease. GROK comprises three core modules: Knowledge-Guided Instruction Generation, CLIP-Style OCT-Biomarker Alignment, and Supervised Instruction Fine-Tuning, which together establish a quantitative-to-qualitative diagnostic chain of thought, mirroring real clinical reasoning when producing detailed lesion annotations. To evaluate our approach, we introduce the Grounded Ophthalmic Understanding benchmark, which covers six disease categories and three tasks: macro-level diagnostic classification, report generation quality, and fine-grained clinical assessment of the generated chain of thought. Experiments show that, with only LoRA (Low-Rank Adaptation) fine-tuning of a 7B-parameter Qwen2 backbone, GROK outperforms comparable 7B and 32B baselines on both report quality and fine-grained clinical metrics, and even exceeds OpenAI o3. Code and data are publicly available in the GROK repository.
A Frequency-Aware Self-Supervised Learning for Ultra-Wide-Field Image Enhancement
Aug 27, 2025Ultra-Wide-Field (UWF) retinal imaging has revolutionized retinal diagnostics by providing a comprehensive view of the retina. However, it often suffers from quality-degrading factors such as blurring and uneven illumination, which obscure fine details and mask pathological information. While numerous retinal image enhancement methods have been proposed for other fundus imageries, they often fail to address the unique requirements in UWF, particularly the need to preserve pathological details. In this paper, we propose a novel frequency-aware self-supervised learning method for UWF image enhancement. It incorporates frequency-decoupled image deblurring and Retinex-guided illumination compensation modules. An asymmetric channel integration operation is introduced in the former module, so as to combine global and local views by leveraging high- and low-frequency information, ensuring the preservation of fine and broader structural details. In addition, a color preservation unit is proposed in the latter Retinex-based module, to provide multi-scale spatial and frequency information, enabling accurate illumination estimation and correction. Experimental results demonstrate that the proposed work not only enhances visualization quality but also improves disease diagnosis performance by restoring and correcting fine local details and uneven intensity. To the best of our knowledge, this work is the first attempt for UWF image enhancement, offering a robust and clinically valuable tool for improving retinal disease management.
Benchmarking Large Multimodal Models for Ophthalmic Visual Question Answering with OphthalWeChat
May 26, 2025Purpose: To develop a bilingual multimodal visual question answering (VQA) benchmark for evaluating VLMs in ophthalmology. Methods: Ophthalmic image posts and associated captions published between January 1, 2016, and December 31, 2024, were collected from WeChat Official Accounts. Based on these captions, bilingual question-answer (QA) pairs in Chinese and English were generated using GPT-4o-mini. QA pairs were categorized into six subsets by question type and language: binary (Binary_CN, Binary_EN), single-choice (Single-choice_CN, Single-choice_EN), and open-ended (Open-ended_CN, Open-ended_EN). The benchmark was used to evaluate the performance of three VLMs: GPT-4o, Gemini 2.0 Flash, and Qwen2.5-VL-72B-Instruct. Results: The final OphthalWeChat dataset included 3,469 images and 30,120 QA pairs across 9 ophthalmic subspecialties, 548 conditions, 29 imaging modalities, and 68 modality combinations. Gemini 2.0 Flash achieved the highest overall accuracy (0.548), outperforming GPT-4o (0.522, P < 0.001) and Qwen2.5-VL-72B-Instruct (0.514, P < 0.001). It also led in both Chinese (0.546) and English subsets (0.550). Subset-specific performance showed Gemini 2.0 Flash excelled in Binary_CN (0.687), Single-choice_CN (0.666), and Single-choice_EN (0.646), while GPT-4o ranked highest in Binary_EN (0.717), Open-ended_CN (BLEU-1: 0.301; BERTScore: 0.382), and Open-ended_EN (BLEU-1: 0.183; BERTScore: 0.240). Conclusions: This study presents the first bilingual VQA benchmark for ophthalmology, distinguished by its real-world context and inclusion of multiple examinations per patient. The dataset reflects authentic clinical decision-making scenarios and enables quantitative evaluation of VLMs, supporting the development of accurate, specialized, and trustworthy AI systems for eye care.
Are Spatial-Temporal Graph Convolution Networks for Human Action Recognition Over-Parameterized?
May 15, 2025Spatial-temporal graph convolutional networks (ST-GCNs) showcase impressive performance in skeleton-based human action recognition (HAR). However, despite the development of numerous models, their recognition performance does not differ significantly after aligning the input settings. With this observation, we hypothesize that ST-GCNs are over-parameterized for HAR, a conjecture subsequently confirmed through experiments employing the lottery ticket hypothesis. Additionally, a novel sparse ST-GCNs generator is proposed, which trains a sparse architecture from a randomly initialized dense network while maintaining comparable performance levels to the dense components. Moreover, we generate multi-level sparsity ST-GCNs by integrating sparse structures at various sparsity levels and demonstrate that the assembled model yields a significant enhancement in HAR performance. Thorough experiments on four datasets, including NTU-RGB+D 60(120), Kinetics-400, and FineGYM, demonstrate that the proposed sparse ST-GCNs can achieve comparable performance to their dense components. Even with 95% fewer parameters, the sparse ST-GCNs exhibit a degradation of <1% in top-1 accuracy. Meanwhile, the multi-level sparsity ST-GCNs, which require only 66% of the parameters of the dense ST-GCNs, demonstrate an improvement of >1% in top-1 accuracy. The code is available at https://github.com/davelailai/Sparse-ST-GCN.