 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Large Multimodal Models for Ophthalmic Visual Question Answering with OphthalWeChat
May 26, 2025Purpose: To develop a bilingual multimodal visual question answering (VQA) benchmark for evaluating VLMs in ophthalmology. Methods: Ophthalmic image posts and associated captions published between January 1, 2016, and December 31, 2024, were collected from WeChat Official Accounts. Based on these captions, bilingual question-answer (QA) pairs in Chinese and English were generated using GPT-4o-mini. QA pairs were categorized into six subsets by question type and language: binary (Binary_CN, Binary_EN), single-choice (Single-choice_CN, Single-choice_EN), and open-ended (Open-ended_CN, Open-ended_EN). The benchmark was used to evaluate the performance of three VLMs: GPT-4o, Gemini 2.0 Flash, and Qwen2.5-VL-72B-Instruct. Results: The final OphthalWeChat dataset included 3,469 images and 30,120 QA pairs across 9 ophthalmic subspecialties, 548 conditions, 29 imaging modalities, and 68 modality combinations. Gemini 2.0 Flash achieved the highest overall accuracy (0.548), outperforming GPT-4o (0.522, P < 0.001) and Qwen2.5-VL-72B-Instruct (0.514, P < 0.001). It also led in both Chinese (0.546) and English subsets (0.550). Subset-specific performance showed Gemini 2.0 Flash excelled in Binary_CN (0.687), Single-choice_CN (0.666), and Single-choice_EN (0.646), while GPT-4o ranked highest in Binary_EN (0.717), Open-ended_CN (BLEU-1: 0.301; BERTScore: 0.382), and Open-ended_EN (BLEU-1: 0.183; BERTScore: 0.240). Conclusions: This study presents the first bilingual VQA benchmark for ophthalmology, distinguished by its real-world context and inclusion of multiple examinations per patient. The dataset reflects authentic clinical decision-making scenarios and enables quantitative evaluation of VLMs, supporting the development of accurate, specialized, and trustworthy AI systems for eye care.
Continuous Human Action Detection Based on Wearable Inertial Data
Dec 11, 2021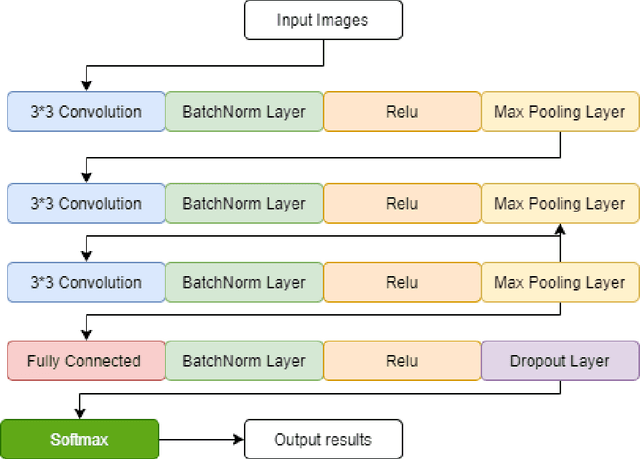

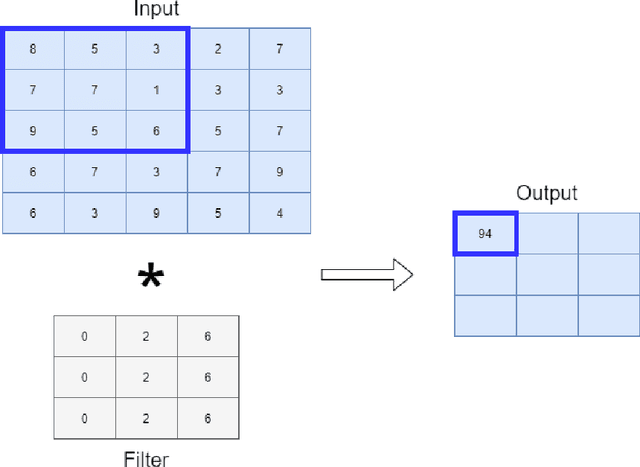
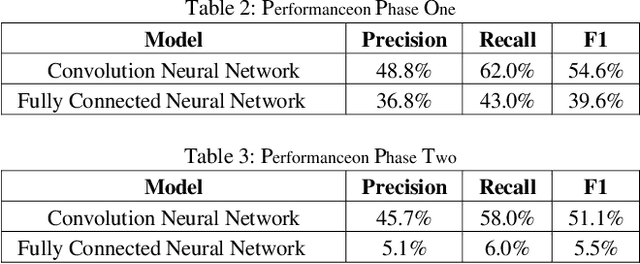
Human action detection is a hot topic, which is widely used in video surveillance, human machine interface, healthcare monitoring, gaming, dancing training and musical instrument teaching. As inertial sensors are low cost, portable, and having no operating space, it is suitable to detect human action. In real-world applications, actions that are of interest appear among actions of non interest without pauses in between. Recognizing and detecting actions of interests from continuous action streams is more challenging and useful for real applications. Based on inertial sensor and C-MHAD smart TV gesture recognition dataset, this paper utilized different inertial sensor feature formats, then compared the performance with different deep neural network structures according to these feature formats. Experiment results show the best performance was achieved by image based inertial feature with convolution neural network, which got 51.1% F1 score.
ChMusic: A Traditional Chinese Music Dataset for Evaluation of Instrument Recognition
Aug 19, 2021
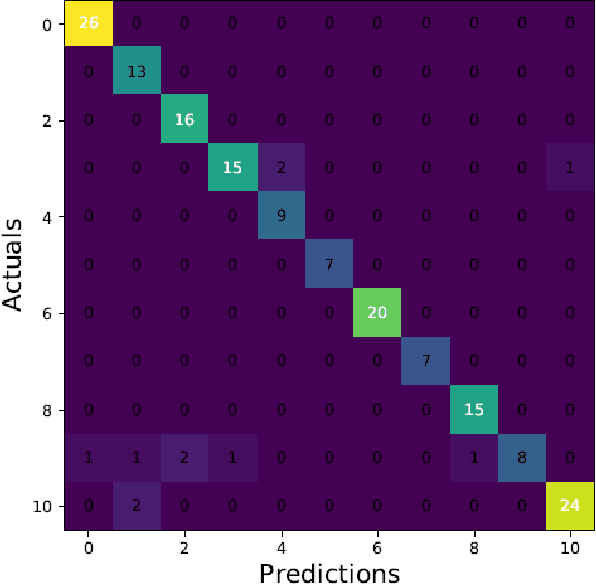
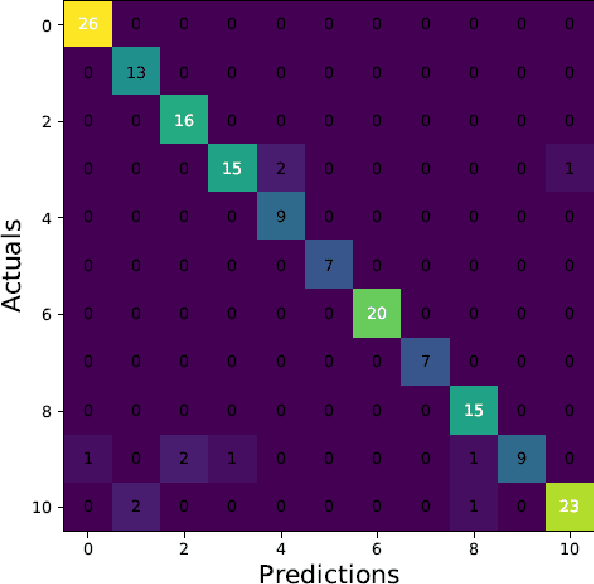
Musical instruments recognition is a widely used application for music information retrieval. As most of previous musical instruments recognition dataset focus on western musical instruments, it is difficult for researcher to study and evaluate the area of traditional Chinese musical instrument recognition. This paper propose a traditional Chinese music dataset for training model and performance evaluation, named ChMusic. This dataset is free and publicly available, 11 traditional Chinese musical instruments and 55 traditional Chinese music excerpts are recorded in this dataset. Then an evaluation standard is proposed based on ChMusic dataset. With this standard, researchers can compare their results following the same rule, and results from different researchers will become comparable.