 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHadBalance: A Plug-and-Play Unified Global Geometric Prior Framework for Generalizable Biomedical Segmentation
Jun 14, 2026Precise biomedical image segmentation is crucial for clinical diagnosis. Geometric cues (e.g., boundary, shape, and topology) can improve structural consistency, yet most are task-specific and lack a unified geometric foundation that generalizes across organs and modalities. We are motivated by the observation that several medical segmentation targets can be approximated as globally near-convex shapes. A convex region is one in which any two interior points can be connected by a line segment entirely contained within the region. In practice, medical targets may exhibit small local concavities or boundary irregularities; we refer to such globally convex-like shapes as near-convex. Motivated by this, we derive Hadwiger Shape Priors from Hadwiger's theorem as an interpretable global regularizer using three 2D measures: area A, perimeter P, and Euler characteristic chi, enabling transfer across organs and modalities. However, because medical datasets are shape-heterogeneous, enforcing near-convex priors uniformly can over-regularize non-convex anatomy with significant concavities, washing out concavities and fine details and degrading segmentation accuracy. To address this challenge, we propose Conflict-Aware Objective Balancing (CAOB), which integrates shape priors with segmentation in a gradient-aware manner. For each prior, CAOB removes only the gradient component that conflicts with segmentation while preserving the remaining aligned component, and adaptively regulates objective influences to prevent prior dominance. This enables stable use of shape priors on shape-heterogeneous data without erasing genuine concavities or fine structural details. We call this plug-and-play framework HadBalance.
Interpreting V1 Population Activity via Image-Neural Latent Representation Alignment
May 05, 2026Understanding the neural mechanisms underlying visual computation has long been a central challenge in neuroscience. Recent alignment based approaches have improved the accuracy of decoding visual stimuli from brain activity, yet they provide limited insight into the neural computations that give rise to these improvements. To address this gap, we propose Dual-Tower Image-Neural Alignment (DINA), an interpretable contrastive framework for analyzing population level visual computations in primary visual cortex (V1). DINA jointly trains a biologically motivated dual-tower architecture that aligns visual stimuli and corresponding V1 population responses in a shared latent space at the level of intermediate feature maps, enabling both accurate decoding and direct access to interpretable feature maps. Evaluated on large-scale two-photon calcium imaging data from mouse V1, DINA achieves accurate neural-based decoding while revealing that decoding performance is primarily supported by coarse, low-level visual structure, rather than semantic category information or fine-grained details. Further analysis reveals that alignable feature maps emerge from multiple spatially distributed image regions, capturing both shape and texture cues, and are predominantly reconstructed by sparse subsets of strongly responsive neurons and their functional interactions. Together, these results confirm that, beyond enabling accurate decoding, DINA provides a principled framework for probing the computational mechanisms underlying visual processing in V1.
GROK: From Quantitative Biomarkers to Qualitative Diagnosis via a Grounded MLLM with Knowledge-Guided Instruction
Oct 05, 2025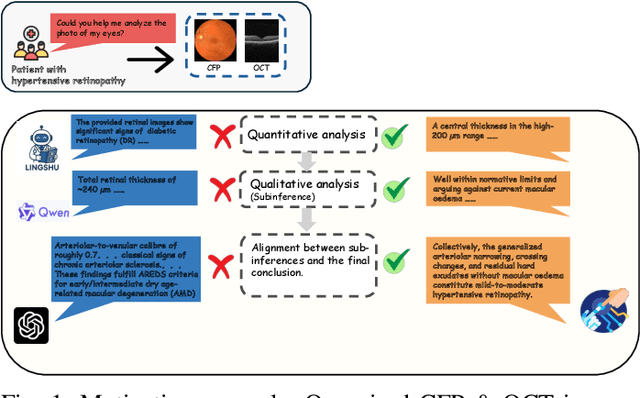
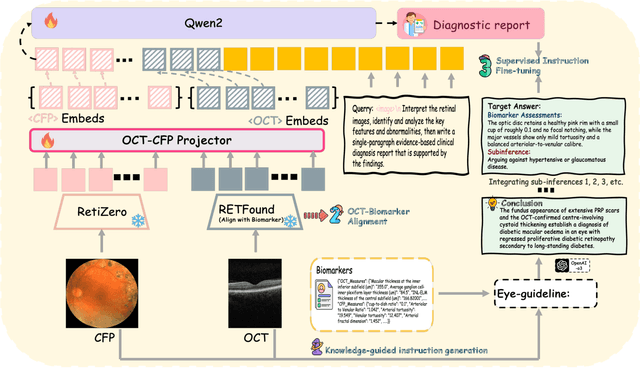
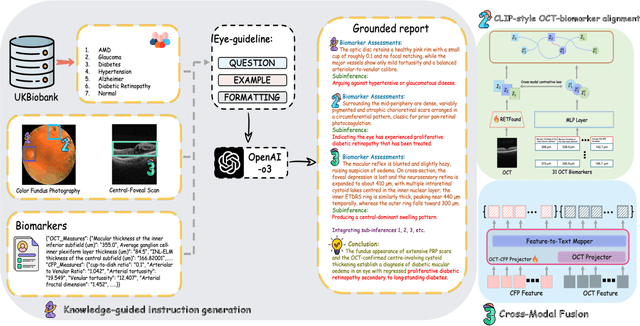

Multimodal large language models (MLLMs) hold promise for integrating diverse data modalities, but current medical adaptations such as LLaVA-Med often fail to fully exploit the synergy between color fundus photography (CFP) and optical coherence tomography (OCT), and offer limited interpretability of quantitative biomarkers. We introduce GROK, a grounded multimodal large language model that jointly processes CFP, OCT, and text to deliver clinician-grade diagnoses of ocular and systemic disease. GROK comprises three core modules: Knowledge-Guided Instruction Generation, CLIP-Style OCT-Biomarker Alignment, and Supervised Instruction Fine-Tuning, which together establish a quantitative-to-qualitative diagnostic chain of thought, mirroring real clinical reasoning when producing detailed lesion annotations. To evaluate our approach, we introduce the Grounded Ophthalmic Understanding benchmark, which covers six disease categories and three tasks: macro-level diagnostic classification, report generation quality, and fine-grained clinical assessment of the generated chain of thought. Experiments show that, with only LoRA (Low-Rank Adaptation) fine-tuning of a 7B-parameter Qwen2 backbone, GROK outperforms comparable 7B and 32B baselines on both report quality and fine-grained clinical metrics, and even exceeds OpenAI o3. Code and data are publicly available in the GROK repository.