 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
CathAction: A Benchmark for Endovascular Intervention Understanding
Aug 23, 2024Real-time visual feedback from catheterization analysis is crucial for enhancing surgical safety and efficiency during endovascular interventions. However, existing datasets are often limited to specific tasks, small scale, and lack the comprehensive annotations necessary for broader endovascular intervention understanding. To tackle these limitations, we introduce CathAction, a large-scale dataset for catheterization understanding. Our CathAction dataset encompasses approximately 500,000 annotated frames for catheterization action understanding and collision detection, and 25,000 ground truth masks for catheter and guidewire segmentation. For each task, we benchmark recent related works in the field. We further discuss the challenges of endovascular intentions compared to traditional computer vision tasks and point out open research questions. We hope that CathAction will facilitate the development of endovascular intervention understanding methods that can be applied to real-world applications. The dataset is available at https://airvlab.github.io/cathdata/.
End-to-End Real-time Catheter Segmentation with Optical Flow-Guided Warping during Endovascular Intervention
Jun 16, 2020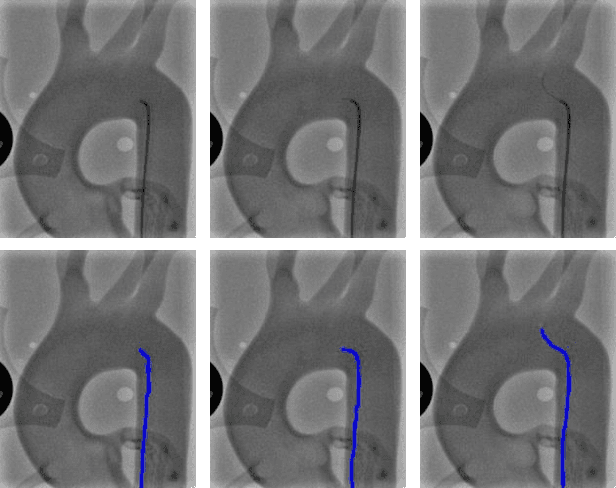

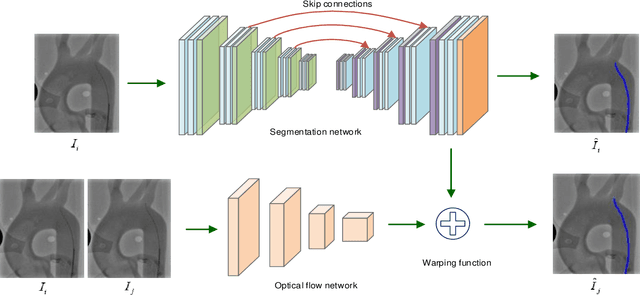
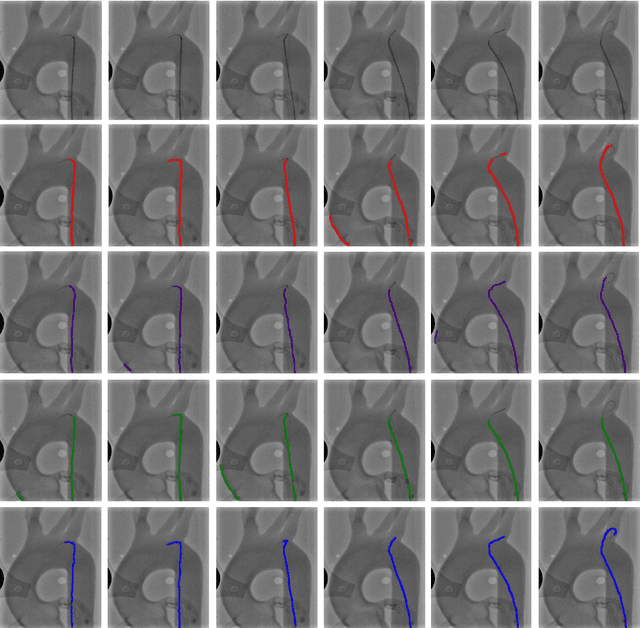
Accurate real-time catheter segmentation is an important pre-requisite for robot-assisted endovascular intervention. Most of the existing learning-based methods for catheter segmentation and tracking are only trained on small-scale datasets or synthetic data due to the difficulties of ground-truth annotation. Furthermore, the temporal continuity in intraoperative imaging sequences is not fully utilised. In this paper, we present FW-Net, an end-to-end and real-time deep learning framework for endovascular intervention. The proposed FW-Net has three modules: a segmentation network with encoder-decoder architecture, a flow network to extract optical flow information, and a novel flow-guided warping function to learn the frame-to-frame temporal continuity. We show that by effectively learning temporal continuity, the network can successfully segment and track the catheters in real-time sequences using only raw ground-truth for training. Detailed validation results confirm that our FW-Net outperforms state-of-the-art techniques while achieving real-time performance.