 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHadBalance: A Plug-and-Play Unified Global Geometric Prior Framework for Generalizable Biomedical Segmentation
Jun 14, 2026Precise biomedical image segmentation is crucial for clinical diagnosis. Geometric cues (e.g., boundary, shape, and topology) can improve structural consistency, yet most are task-specific and lack a unified geometric foundation that generalizes across organs and modalities. We are motivated by the observation that several medical segmentation targets can be approximated as globally near-convex shapes. A convex region is one in which any two interior points can be connected by a line segment entirely contained within the region. In practice, medical targets may exhibit small local concavities or boundary irregularities; we refer to such globally convex-like shapes as near-convex. Motivated by this, we derive Hadwiger Shape Priors from Hadwiger's theorem as an interpretable global regularizer using three 2D measures: area A, perimeter P, and Euler characteristic chi, enabling transfer across organs and modalities. However, because medical datasets are shape-heterogeneous, enforcing near-convex priors uniformly can over-regularize non-convex anatomy with significant concavities, washing out concavities and fine details and degrading segmentation accuracy. To address this challenge, we propose Conflict-Aware Objective Balancing (CAOB), which integrates shape priors with segmentation in a gradient-aware manner. For each prior, CAOB removes only the gradient component that conflicts with segmentation while preserving the remaining aligned component, and adaptively regulates objective influences to prevent prior dominance. This enables stable use of shape priors on shape-heterogeneous data without erasing genuine concavities or fine structural details. We call this plug-and-play framework HadBalance.
Leveraging Persistence Image to Enhance Robustness and Performance in Curvilinear Structure Segmentation
Jan 25, 2026Segmenting curvilinear structures in medical images is essential for analyzing morphological patterns in clinical applications. Integrating topological properties, such as connectivity, improves segmentation accuracy and consistency. However, extracting and embedding such properties - especially from Persistence Diagrams (PD) - is challenging due to their non-differentiability and computational cost. Existing approaches mostly encode topology through handcrafted loss functions, which generalize poorly across tasks. In this paper, we propose PIs-Regressor, a simple yet effective module that learns persistence image (PI) - finite, differentiable representations of topological features - directly from data. Together with Topology SegNet, which fuses these features in both downsampling and upsampling stages, our framework integrates topology into the network architecture itself rather than auxiliary losses. Unlike existing methods that depend heavily on handcrafted loss functions, our approach directly incorporates topological information into the network structure, leading to more robust segmentation. Our design is flexible and can be seamlessly combined with other topology-based methods to further enhance segmentation performance. Experimental results show that integrating topological features enhances model robustness, effectively handling challenges like overexposure and blurring in medical imaging. Our approach on three curvilinear benchmarks demonstrate state-of-the-art performance in both pixel-level accuracy and topological fidelity.
GROK: From Quantitative Biomarkers to Qualitative Diagnosis via a Grounded MLLM with Knowledge-Guided Instruction
Oct 05, 2025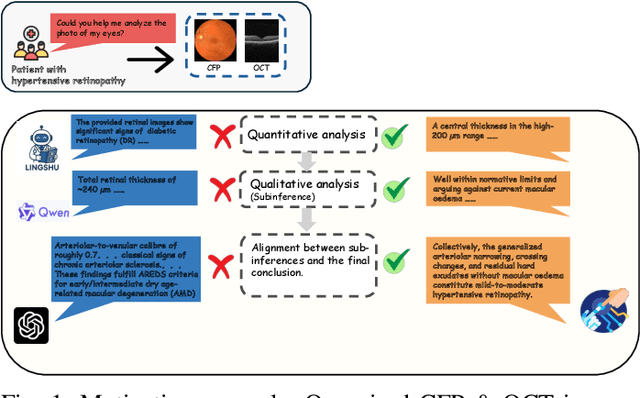
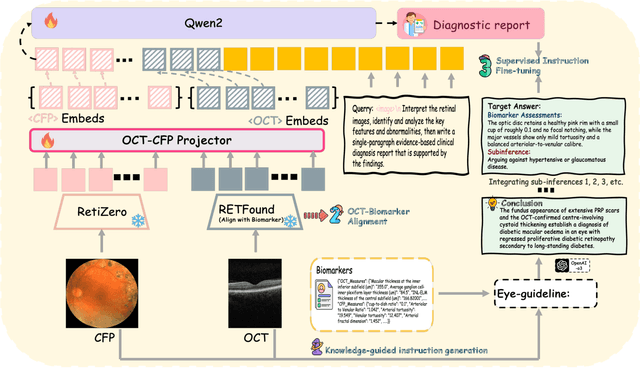
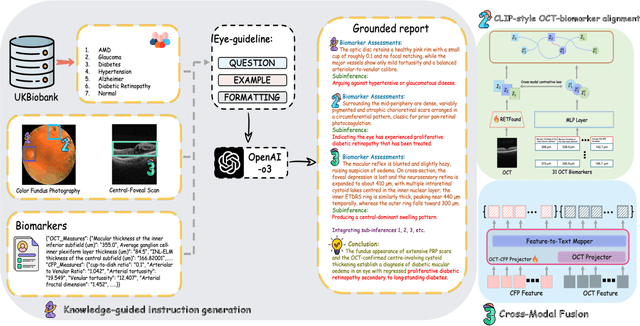

Multimodal large language models (MLLMs) hold promise for integrating diverse data modalities, but current medical adaptations such as LLaVA-Med often fail to fully exploit the synergy between color fundus photography (CFP) and optical coherence tomography (OCT), and offer limited interpretability of quantitative biomarkers. We introduce GROK, a grounded multimodal large language model that jointly processes CFP, OCT, and text to deliver clinician-grade diagnoses of ocular and systemic disease. GROK comprises three core modules: Knowledge-Guided Instruction Generation, CLIP-Style OCT-Biomarker Alignment, and Supervised Instruction Fine-Tuning, which together establish a quantitative-to-qualitative diagnostic chain of thought, mirroring real clinical reasoning when producing detailed lesion annotations. To evaluate our approach, we introduce the Grounded Ophthalmic Understanding benchmark, which covers six disease categories and three tasks: macro-level diagnostic classification, report generation quality, and fine-grained clinical assessment of the generated chain of thought. Experiments show that, with only LoRA (Low-Rank Adaptation) fine-tuning of a 7B-parameter Qwen2 backbone, GROK outperforms comparable 7B and 32B baselines on both report quality and fine-grained clinical metrics, and even exceeds OpenAI o3. Code and data are publicly available in the GROK repository.