 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Stylist: Video Stylization via Collaboration and Reflection of MLLM Agents
Mar 15, 2025



Despite the recent advancement in video stylization, most existing methods struggle to render any video with complex transitions, based on an open style description of user query. To fill this gap, we introduce a generic multi-agent system for video stylization, V-Stylist, by a novel collaboration and reflection paradigm of multi-modal large language models. Specifically, our V-Stylist is a systematical workflow with three key roles: (1) Video Parser decomposes the input video into a number of shots and generates their text prompts of key shot content. Via a concise video-to-shot prompting paradigm, it allows our V-Stylist to effectively handle videos with complex transitions. (2) Style Parser identifies the style in the user query and progressively search the matched style model from a style tree. Via a robust tree-of-thought searching paradigm, it allows our V-Stylist to precisely specify vague style preference in the open user query. (3) Style Artist leverages the matched model to render all the video shots into the required style. Via a novel multi-round self-reflection paradigm, it allows our V-Stylist to adaptively adjust detail control, according to the style requirement. With such a distinct design of mimicking human professionals, our V-Stylist achieves a major breakthrough over the primary challenges for effective and automatic video stylization. Moreover,we further construct a new benchmark Text-driven Video Stylization Benchmark (TVSBench), which fills the gap to assess stylization of complex videos on open user queries. Extensive experiments show that, V-Stylist achieves the state-of-the-art, e.g.,V-Stylist surpasses FRESCO and ControlVideo by 6.05% and 4.51% respectively in overall average metrics, marking a significant advance in video stylization.
LVAgent: Long Video Understanding by Multi-Round Dynamical Collaboration of MLLM Agents
Mar 13, 2025



Existing Multimodal Large Language Models (MLLMs) encounter significant challenges in modeling the temporal context within long videos. Currently, mainstream Agent-based methods use external tools (e.g., search engine, memory banks, OCR, retrieval models) to assist a single MLLM in answering long video questions. Despite such tool-based support, a solitary MLLM still offers only a partial understanding of long videos, resulting in limited performance. In order to better address long video tasks, we introduce LVAgent, the first framework enabling multi-round dynamic collaboration of MLLM agents in long video understanding. Our methodology consists of four key steps: 1. Selection: We pre-select appropriate agents from the model library to form optimal agent teams based on different tasks. 2. Perception: We design an effective retrieval scheme for long videos, improving the coverage of critical temporal segments while maintaining computational efficiency. 3. Action: Agents answer long video-related questions and exchange reasons. 4. Reflection: We evaluate the performance of each agent in each round of discussion and optimize the agent team for dynamic collaboration. The agents iteratively refine their answers by multi-round dynamical collaboration of MLLM agents. LVAgent is the first agent system method that outperforms all closed-source models (including GPT-4o) and open-source models (including InternVL-2.5 and Qwen2-VL) in the long video understanding tasks. Our LVAgent achieves an accuracy of 80% on four mainstream long video understanding tasks. Notably, on the LongVideoBench dataset, LVAgent improves accuracy by up to 14.3% compared with SOTA.
TimeStep Master: Asymmetrical Mixture of Timestep LoRA Experts for Versatile and Efficient Diffusion Models in Vision
Mar 10, 2025
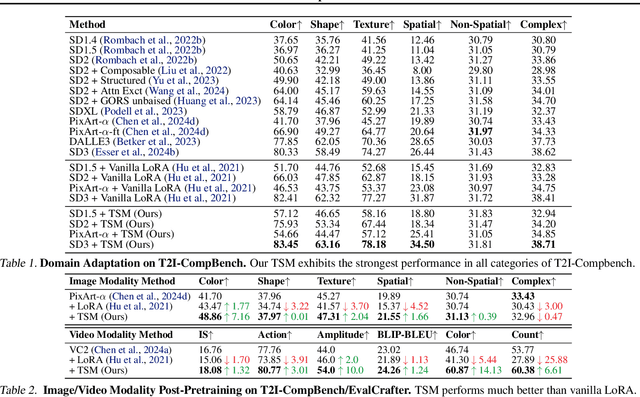
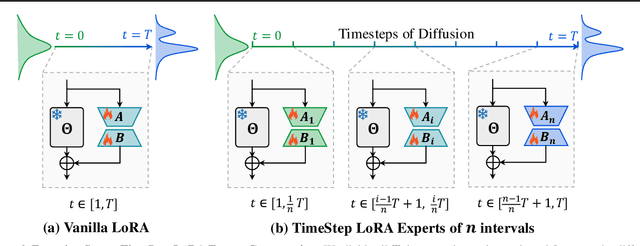
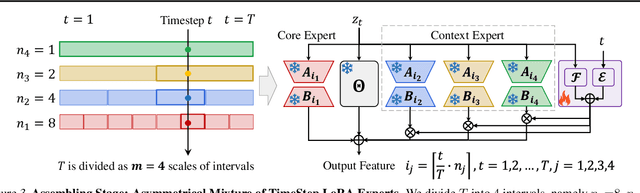
Diffusion models have driven the advancement of vision generation over the past years. However, it is often difficult to apply these large models in downstream tasks, due to massive fine-tuning cost. Recently, Low-Rank Adaptation (LoRA) has been applied for efficient tuning of diffusion models. Unfortunately, the capabilities of LoRA-tuned diffusion models are limited, since the same LoRA is used for different timesteps of the diffusion process. To tackle this problem, we introduce a general and concise TimeStep Master (TSM) paradigm with two key fine-tuning stages. In the fostering stage (1-stage), we apply different LoRAs to fine-tune the diffusion model at different timestep intervals. This results in different TimeStep LoRA experts that can effectively capture different noise levels. In the assembling stage (2-stage), we design a novel asymmetrical mixture of TimeStep LoRA experts, via core-context collaboration of experts at multi-scale intervals. For each timestep, we leverage TimeStep LoRA expert within the smallest interval as the core expert without gating, and use experts within the bigger intervals as the context experts with time-dependent gating. Consequently, our TSM can effectively model the noise level via the expert in the finest interval, and adaptively integrate contexts from the experts of other scales, boosting the versatility of diffusion models. To show the effectiveness of our TSM paradigm, we conduct extensive experiments on three typical and popular LoRA-related tasks of diffusion models, including domain adaptation, post-pretraining, and model distillation. Our TSM achieves the state-of-the-art results on all these tasks, throughout various model structures (UNet, DiT and MM-DiT) and visual data modalities (Image, Video), showing its remarkable generalization capacity.
Get In Video: Add Anything You Want to the Video
Mar 08, 2025



Video editing increasingly demands the ability to incorporate specific real-world instances into existing footage, yet current approaches fundamentally fail to capture the unique visual characteristics of particular subjects and ensure natural instance/scene interactions. We formalize this overlooked yet critical editing paradigm as "Get-In-Video Editing", where users provide reference images to precisely specify visual elements they wish to incorporate into videos. Addressing this task's dual challenges, severe training data scarcity and technical challenges in maintaining spatiotemporal coherence, we introduce three key contributions. First, we develop GetIn-1M dataset created through our automated Recognize-Track-Erase pipeline, which sequentially performs video captioning, salient instance identification, object detection, temporal tracking, and instance removal to generate high-quality video editing pairs with comprehensive annotations (reference image, tracking mask, instance prompt). Second, we present GetInVideo, a novel end-to-end framework that leverages a diffusion transformer architecture with 3D full attention to process reference images, condition videos, and masks simultaneously, maintaining temporal coherence, preserving visual identity, and ensuring natural scene interactions when integrating reference objects into videos. Finally, we establish GetInBench, the first comprehensive benchmark for Get-In-Video Editing scenario, demonstrating our approach's superior performance through extensive evaluations. Our work enables accessible, high-quality incorporation of specific real-world subjects into videos, significantly advancing personalized video editing capabilities.
An Egocentric Vision-Language Model based Portable Real-time Smart Assistant
Mar 06, 2025We present Vinci, a vision-language system designed to provide real-time, comprehensive AI assistance on portable devices. At its core, Vinci leverages EgoVideo-VL, a novel model that integrates an egocentric vision foundation model with a large language model (LLM), enabling advanced functionalities such as scene understanding, temporal grounding, video summarization, and future planning. To enhance its utility, Vinci incorporates a memory module for processing long video streams in real time while retaining contextual history, a generation module for producing visual action demonstrations, and a retrieval module that bridges egocentric and third-person perspectives to provide relevant how-to videos for skill acquisition. Unlike existing systems that often depend on specialized hardware, Vinci is hardware-agnostic, supporting deployment across a wide range of devices, including smartphones and wearable cameras. In our experiments, we first demonstrate the superior performance of EgoVideo-VL on multiple public benchmarks, showcasing its vision-language reasoning and contextual understanding capabilities. We then conduct a series of user studies to evaluate the real-world effectiveness of Vinci, highlighting its adaptability and usability in diverse scenarios. We hope Vinci can establish a new framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. Including the frontend, backend, and models, all codes of Vinci are available at https://github.com/OpenGVLab/vinci.
WeGen: A Unified Model for Interactive Multimodal Generation as We Chat
Mar 03, 2025Existing multimodal generative models fall short as qualified design copilots, as they often struggle to generate imaginative outputs once instructions are less detailed or lack the ability to maintain consistency with the provided references. In this work, we introduce WeGen, a model that unifies multimodal generation and understanding, and promotes their interplay in iterative generation. It can generate diverse results with high creativity for less detailed instructions. And it can progressively refine prior generation results or integrating specific contents from references following the instructions in its chat with users. During this process, it is capable of preserving consistency in the parts that the user is already satisfied with. To this end, we curate a large-scale dataset, extracted from Internet videos, containing rich object dynamics and auto-labeled dynamics descriptions by advanced foundation models to date. These two information are interleaved into a single sequence to enable WeGen to learn consistency-aware generation where the specified dynamics are generated while the consistency of unspecified content is preserved aligned with instructions. Besides, we introduce a prompt self-rewriting mechanism to enhance generation diversity. Extensive experiments demonstrate the effectiveness of unifying multimodal understanding and generation in WeGen and show it achieves state-of-the-art performance across various visual generation benchmarks. These also demonstrate the potential of WeGen as a user-friendly design copilot as desired. The code and models will be available at https://github.com/hzphzp/WeGen.
Modeling Fine-Grained Hand-Object Dynamics for Egocentric Video Representation Learning
Mar 02, 2025In egocentric video understanding, the motion of hands and objects as well as their interactions play a significant role by nature. However, existing egocentric video representation learning methods mainly focus on aligning video representation with high-level narrations, overlooking the intricate dynamics between hands and objects. In this work, we aim to integrate the modeling of fine-grained hand-object dynamics into the video representation learning process. Since no suitable data is available, we introduce HOD, a novel pipeline employing a hand-object detector and a large language model to generate high-quality narrations with detailed descriptions of hand-object dynamics. To learn these fine-grained dynamics, we propose EgoVideo, a model with a new lightweight motion adapter to capture fine-grained hand-object motion information. Through our co-training strategy, EgoVideo effectively and efficiently leverages the fine-grained hand-object dynamics in the HOD data. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple egocentric downstream tasks, including improvements of 6.3% in EK-100 multi-instance retrieval, 5.7% in EK-100 classification, and 16.3% in EGTEA classification in zero-shot settings. Furthermore, our model exhibits robust generalization capabilities in hand-object interaction and robot manipulation tasks. Code and data are available at https://github.com/OpenRobotLab/EgoHOD/.
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Jan 21, 2025


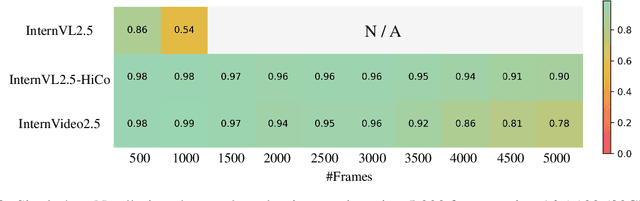
This paper aims to improve the performance of video multimodal large language models (MLLM) via long and rich context (LRC) modeling. As a result, we develop a new version of InternVideo2.5 with a focus on enhancing the original MLLMs' ability to perceive fine-grained details and capture long-form temporal structure in videos. Specifically, our approach incorporates dense vision task annotations into MLLMs using direct preference optimization and develops compact spatiotemporal representations through adaptive hierarchical token compression. Experimental results demonstrate this unique design of LRC greatly improves the results of video MLLM in mainstream video understanding benchmarks (short & long), enabling the MLLM to memorize significantly longer video inputs (at least 6x longer than the original), and master specialized vision capabilities like object tracking and segmentation. Our work highlights the importance of multimodal context richness (length and fineness) in empowering MLLM's innate abilites (focus and memory), providing new insights for future research on video MLLM. Code and models are available at https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5
H-MBA: Hierarchical MamBa Adaptation for Multi-Modal Video Understanding in Autonomous Driving
Jan 08, 2025



With the prevalence of Multimodal Large Language Models(MLLMs), autonomous driving has encountered new opportunities and challenges. In particular, multi-modal video understanding is critical to interactively analyze what will happen in the procedure of autonomous driving. However, videos in such a dynamical scene that often contains complex spatial-temporal movements, which restricts the generalization capacity of the existing MLLMs in this field. To bridge the gap, we propose a novel Hierarchical Mamba Adaptation (H-MBA) framework to fit the complicated motion changes in autonomous driving videos. Specifically, our H-MBA consists of two distinct modules, including Context Mamba (C-Mamba) and Query Mamba (Q-Mamba). First, C-Mamba contains various types of structure state space models, which can effectively capture multi-granularity video context for different temporal resolutions. Second, Q-Mamba flexibly transforms the current frame as the learnable query, and attentively selects multi-granularity video context into query. Consequently, it can adaptively integrate all the video contexts of multi-scale temporal resolutions to enhance video understanding. Via a plug-and-play paradigm in MLLMs, our H-MBA shows the remarkable performance on multi-modal video tasks in autonomous driving, e.g., for risk object detection, it outperforms the previous SOTA method with 5.5% mIoU improvement.
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Dec 31, 2024



Long-context modeling is a critical capability for multimodal large language models (MLLMs), enabling them to process long-form contents with implicit memorization. Despite its advances, handling extremely long videos remains challenging due to the difficulty in maintaining crucial features over extended sequences. This paper introduces a Hierarchical visual token Compression (HiCo) method designed for high-fidelity representation and a practical context modeling system VideoChat-Flash tailored for multimodal long-sequence processing. HiCo capitalizes on the redundancy of visual information in long videos to compress long video context from the clip-level to the video-level, reducing the compute significantly while preserving essential details. VideoChat-Flash features a multi-stage short-to-long learning scheme, a rich dataset of real-world long videos named LongVid, and an upgraded "Needle-In-A-video-Haystack" (NIAH) for evaluating context capacities. In extensive experiments, VideoChat-Flash shows the leading performance on both mainstream long and short video benchmarks at the 7B model scale. It firstly gets 99.1% accuracy over 10,000 frames in NIAH among open-source models.