 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Multimodal Aleatoric Uncertainty in Segmentation with Mixture of Stochastic Expert
Dec 14, 2022



Equipping predicted segmentation with calibrated uncertainty is essential for safety-critical applications. In this work, we focus on capturing the data-inherent uncertainty (aka aleatoric uncertainty) in segmentation, typically when ambiguities exist in input images. Due to the high-dimensional output space and potential multiple modes in segmenting ambiguous images, it remains challenging to predict well-calibrated uncertainty for segmentation. To tackle this problem, we propose a novel mixture of stochastic experts (MoSE) model, where each expert network estimates a distinct mode of the aleatoric uncertainty and a gating network predicts the probabilities of an input image being segmented in those modes. This yields an efficient two-level uncertainty representation. To learn the model, we develop a Wasserstein-like loss that directly minimizes the distribution distance between the MoSE and ground truth annotations. The loss can easily integrate traditional segmentation quality measures and be efficiently optimized via constraint relaxation. We validate our method on the LIDC-IDRI dataset and a modified multimodal Cityscapes dataset. Results demonstrate that our method achieves the state-of-the-art or competitive performance on all metrics.
Generative Negative Text Replay for Continual Vision-Language Pretraining
Oct 31, 2022



Vision-language pre-training (VLP) has attracted increasing attention recently. With a large amount of image-text pairs, VLP models trained with contrastive loss have achieved impressive performance in various tasks, especially the zero-shot generalization on downstream datasets. In practical applications, however, massive data are usually collected in a streaming fashion, requiring VLP models to continuously integrate novel knowledge from incoming data and retain learned knowledge. In this work, we focus on learning a VLP model with sequential chunks of image-text pair data. To tackle the catastrophic forgetting issue in this multi-modal continual learning setting, we first introduce pseudo text replay that generates hard negative texts conditioned on the training images in memory, which not only better preserves learned knowledge but also improves the diversity of negative samples in the contrastive loss. Moreover, we propose multi-modal knowledge distillation between images and texts to align the instance-wise prediction between old and new models. We incrementally pre-train our model on both the instance and class incremental splits of the Conceptual Caption dataset, and evaluate the model on zero-shot image classification and image-text retrieval tasks. Our method consistently outperforms the existing baselines with a large margin, which demonstrates its superiority. Notably, we realize an average performance boost of $4.60\%$ on image-classification downstream datasets for the class incremental split.
CALIP: Zero-Shot Enhancement of CLIP with Parameter-free Attention
Sep 28, 2022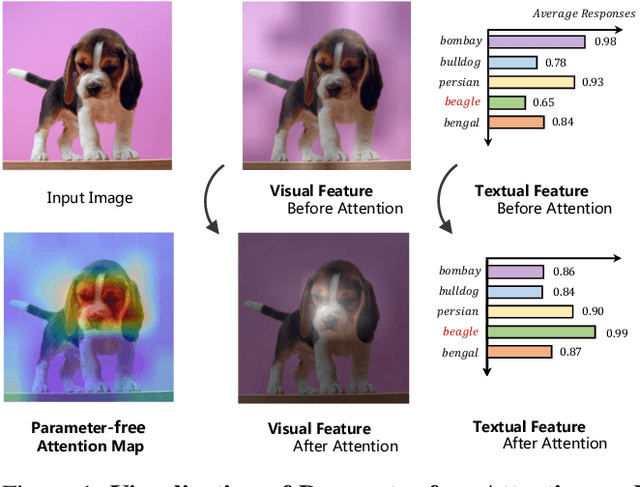
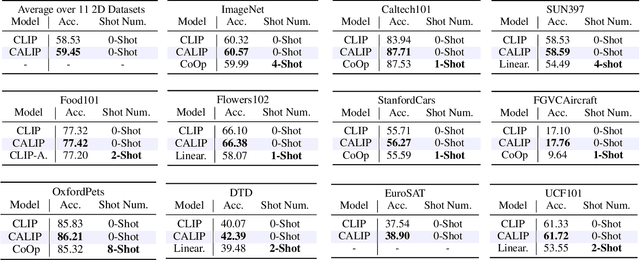
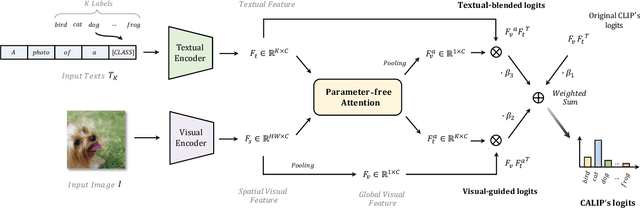

Contrastive Language-Image Pre-training (CLIP) has been shown to learn visual representations with great transferability, which achieves promising accuracy for zero-shot classification. To further improve its downstream performance, existing works propose additional learnable modules upon CLIP and fine-tune them by few-shot training sets. However, the resulting extra training cost and data requirement severely hinder the efficiency for model deployment and knowledge transfer. In this paper, we introduce a free-lunch enhancement method, CALIP, to boost CLIP's zero-shot performance via a parameter-free Attention module. Specifically, we guide visual and textual representations to interact with each other and explore cross-modal informative features via attention. As the pre-training has largely reduced the embedding distances between two modalities, we discard all learnable parameters in the attention and bidirectionally update the multi-modal features, enabling the whole process to be parameter-free and training-free. In this way, the images are blended with textual-aware signals and the text representations become visual-guided for better adaptive zero-shot alignment. We evaluate CALIP on various benchmarks of 14 datasets for both 2D image and 3D point cloud few-shot classification, showing consistent zero-shot performance improvement over CLIP. Based on that, we further insert a small number of linear layers in CALIP's attention module and verify our robustness under the few-shot settings, which also achieves leading performance compared to existing methods. Those extensive experiments demonstrate the superiority of our approach for efficient enhancement of CLIP.
Part-aware Prototypical Graph Network for One-shot Skeleton-based Action Recognition
Aug 19, 2022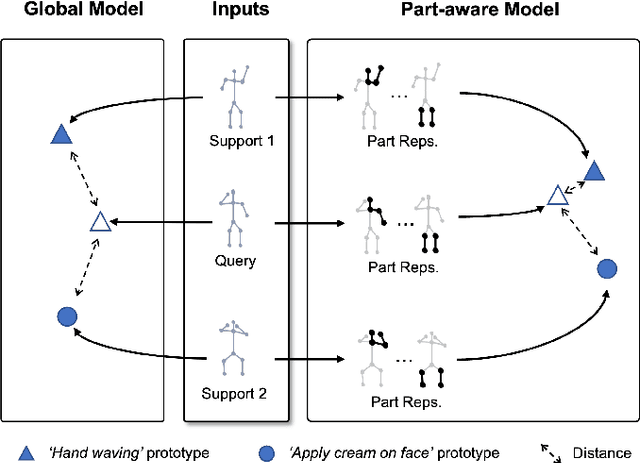
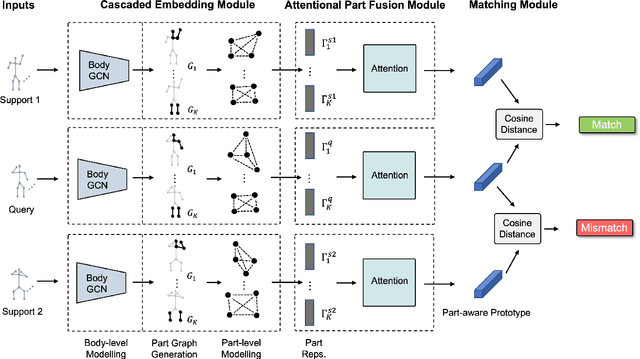
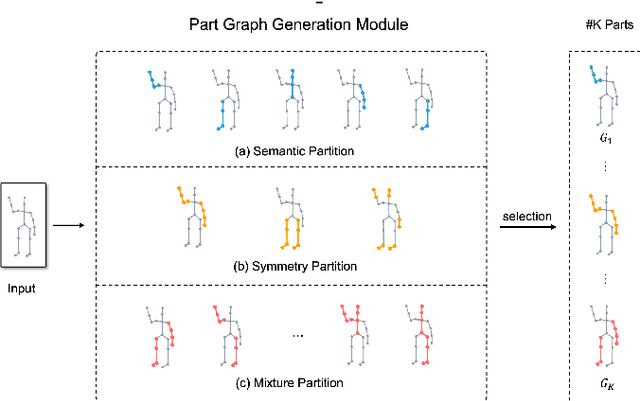
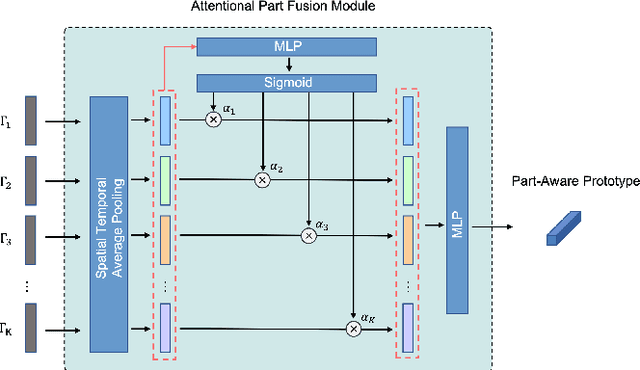
In this paper, we study the problem of one-shot skeleton-based action recognition, which poses unique challenges in learning transferable representation from base classes to novel classes, particularly for fine-grained actions. Existing meta-learning frameworks typically rely on the body-level representations in spatial dimension, which limits the generalisation to capture subtle visual differences in the fine-grained label space. To overcome the above limitation, we propose a part-aware prototypical representation for one-shot skeleton-based action recognition. Our method captures skeleton motion patterns at two distinctive spatial levels, one for global contexts among all body joints, referred to as body level, and the other attends to local spatial regions of body parts, referred to as the part level. We also devise a class-agnostic attention mechanism to highlight important parts for each action class. Specifically, we develop a part-aware prototypical graph network consisting of three modules: a cascaded embedding module for our dual-level modelling, an attention-based part fusion module to fuse parts and generate part-aware prototypes, and a matching module to perform classification with the part-aware representations. We demonstrate the effectiveness of our method on two public skeleton-based action recognition datasets: NTU RGB+D 120 and NW-UCLA.
Learning Semantic Correspondence with Sparse Annotations
Aug 17, 2022
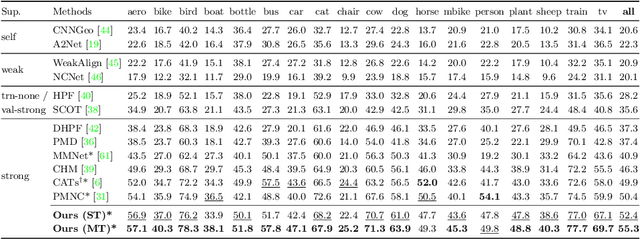
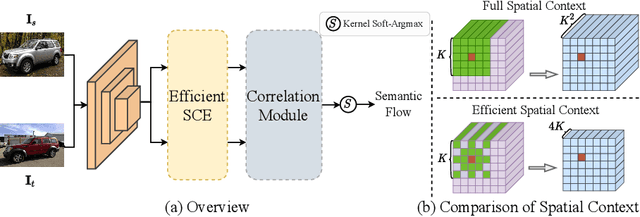
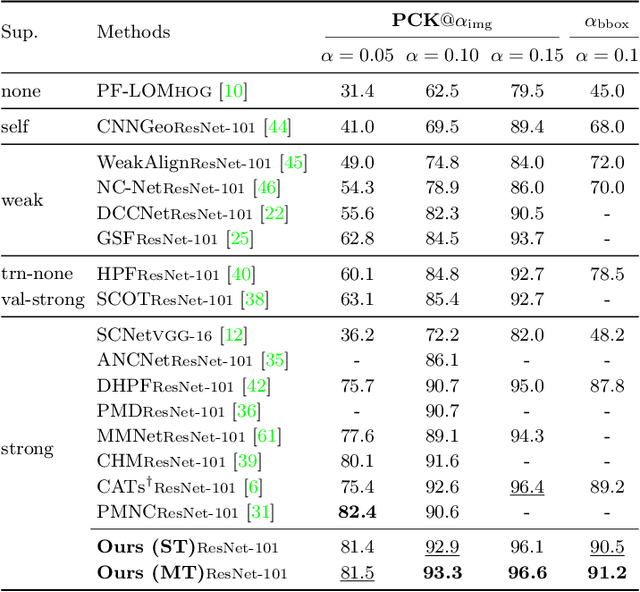
Finding dense semantic correspondence is a fundamental problem in computer vision, which remains challenging in complex scenes due to background clutter, extreme intra-class variation, and a severe lack of ground truth. In this paper, we aim to address the challenge of label sparsity in semantic correspondence by enriching supervision signals from sparse keypoint annotations. To this end, we first propose a teacher-student learning paradigm for generating dense pseudo-labels and then develop two novel strategies for denoising pseudo-labels. In particular, we use spatial priors around the sparse annotations to suppress the noisy pseudo-labels. In addition, we introduce a loss-driven dynamic label selection strategy for label denoising. We instantiate our paradigm with two variants of learning strategies: a single offline teacher setting, and mutual online teachers setting. Our approach achieves notable improvements on three challenging benchmarks for semantic correspondence and establishes the new state-of-the-art. Project page: https://shuaiyihuang.github.io/publications/SCorrSAN.
A Novel Unified Conditional Score-based Generative Framework for Multi-modal Medical Image Completion
Jul 07, 2022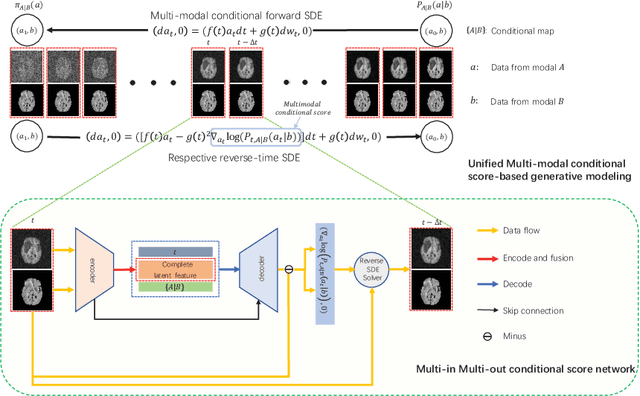
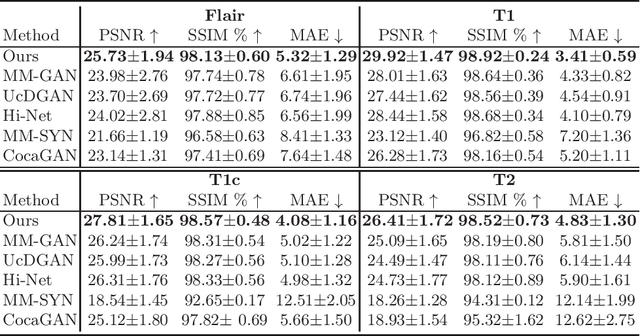
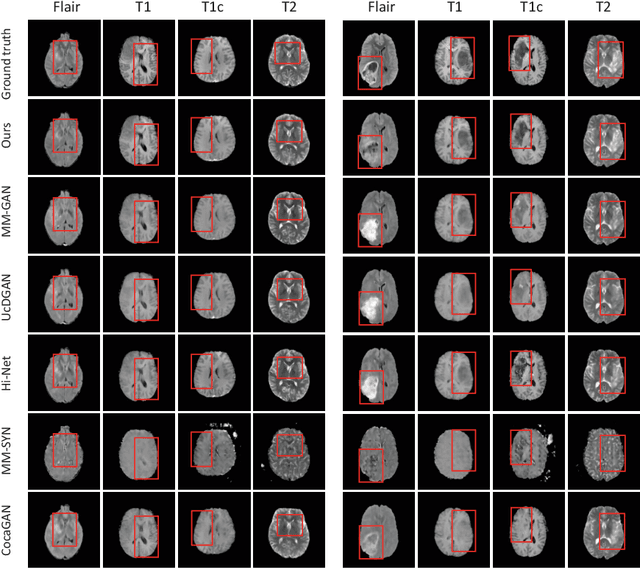
Multi-modal medical image completion has been extensively applied to alleviate the missing modality issue in a wealth of multi-modal diagnostic tasks. However, for most existing synthesis methods, their inferences of missing modalities can collapse into a deterministic mapping from the available ones, ignoring the uncertainties inherent in the cross-modal relationships. Here, we propose the Unified Multi-Modal Conditional Score-based Generative Model (UMM-CSGM) to take advantage of Score-based Generative Model (SGM) in modeling and stochastically sampling a target probability distribution, and further extend SGM to cross-modal conditional synthesis for various missing-modality configurations in a unified framework. Specifically, UMM-CSGM employs a novel multi-in multi-out Conditional Score Network (mm-CSN) to learn a comprehensive set of cross-modal conditional distributions via conditional diffusion and reverse generation in the complete modality space. In this way, the generation process can be accurately conditioned by all available information, and can fit all possible configurations of missing modalities in a single network. Experiments on BraTS19 dataset show that the UMM-CSGM can more reliably synthesize the heterogeneous enhancement and irregular area in tumor-induced lesions for any missing modalities.
Mutual Information-guided Knowledge Transfer for Novel Class Discovery
Jun 24, 2022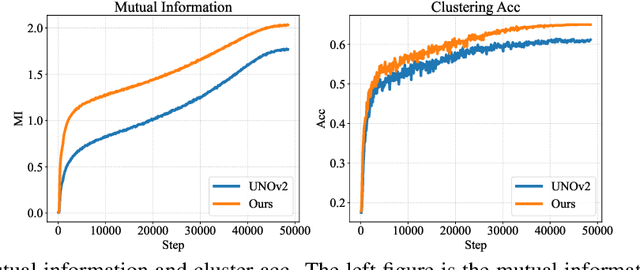
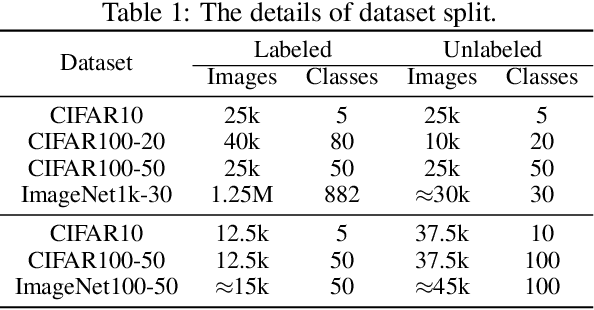
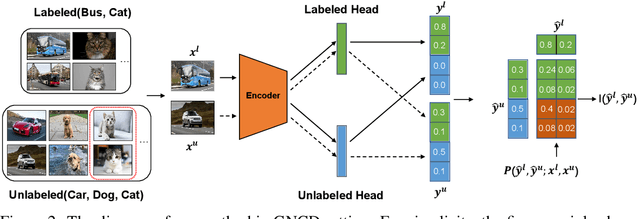
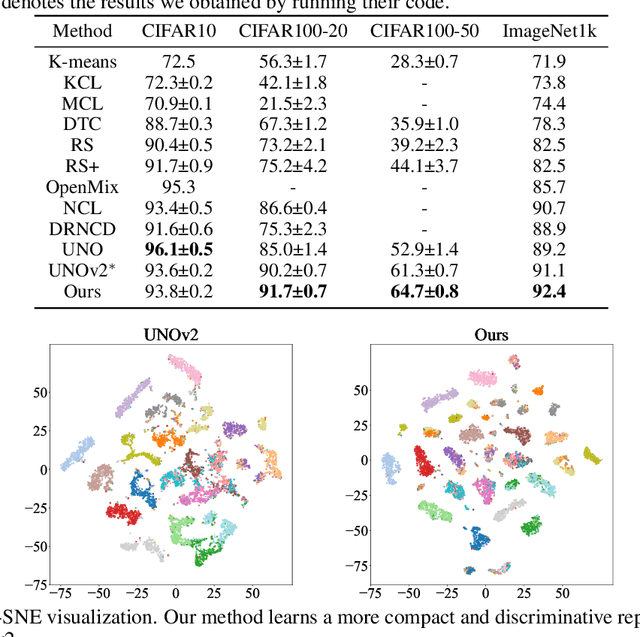
We tackle the novel class discovery problem, aiming to discover novel classes in unlabeled data based on labeled data from seen classes. The main challenge is to transfer knowledge contained in the seen classes to unseen ones. Previous methods mostly transfer knowledge through sharing representation space or joint label space. However, they tend to neglect the class relation between seen and unseen categories, and thus the learned representations are less effective for clustering unseen classes. In this paper, we propose a principle and general method to transfer semantic knowledge between seen and unseen classes. Our insight is to utilize mutual information to measure the relation between seen classes and unseen classes in a restricted label space and maximizing mutual information promotes transferring semantic knowledge. To validate the effectiveness and generalization of our method, we conduct extensive experiments both on novel class discovery and general novel class discovery settings. Our results show that the proposed method outperforms previous SOTA by a significant margin on several benchmarks.
ROI-Constrained Bidding via Curriculum-Guided Bayesian Reinforcement Learning
Jun 23, 2022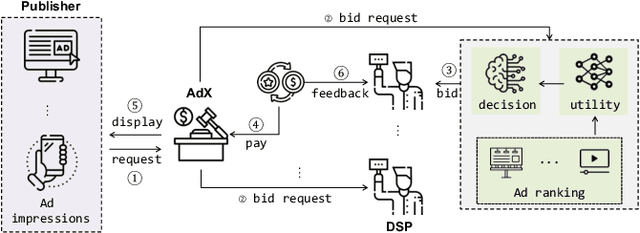
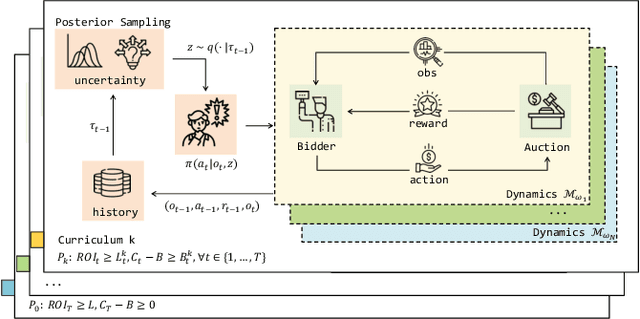
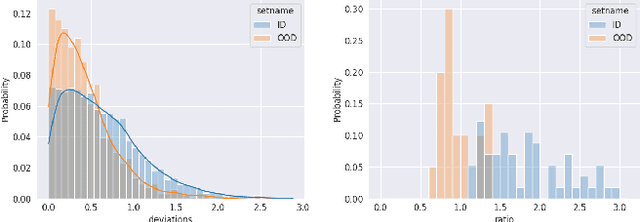
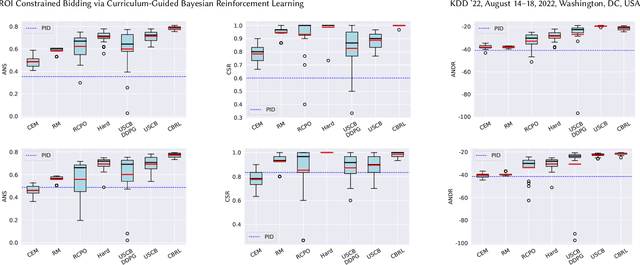
Real-Time Bidding (RTB) is an important mechanism in modern online advertising systems. Advertisers employ bidding strategies in RTB to optimize their advertising effects subject to various financial requirements, especially the return-on-investment (ROI) constraint. ROIs change non-monotonically during the sequential bidding process, and often induce a see-saw effect between constraint satisfaction and objective optimization. While some existing approaches show promising results in static or mildly changing ad markets, they fail to generalize to highly dynamic ad markets with ROI constraints, due to their inability to adaptively balance constraints and objectives amidst non-stationarity and partial observability. In this work, we specialize in ROI-Constrained Bidding in non-stationary markets. Based on a Partially Observable Constrained Markov Decision Process, our method exploits an indicator-augmented reward function free of extra trade-off parameters and develops a Curriculum-Guided Bayesian Reinforcement Learning (CBRL) framework to adaptively control the constraint-objective trade-off in non-stationary ad markets. Extensive experiments on a large-scale industrial dataset with two problem settings reveal that CBRL generalizes well in both in-distribution and out-of-distribution data regimes, and enjoys superior learning efficiency and stability.
FishGym: A High-Performance Physics-based Simulation Framework for Underwater Robot Learning
Jun 03, 2022
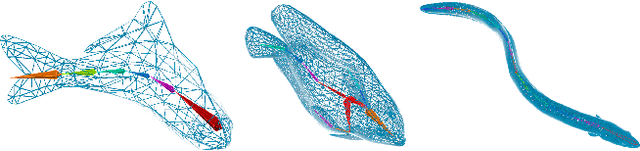

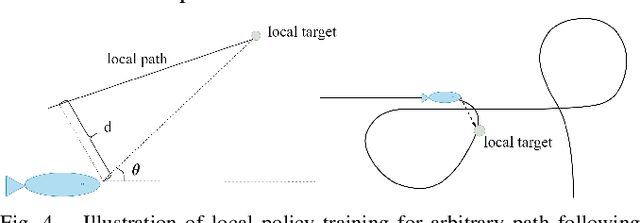
Bionic underwater robots have demonstrated their superiority in many applications. Yet, training their intelligence for a variety of tasks that mimic the behavior of underwater creatures poses a number of challenges in practice, mainly due to lack of a large amount of available training data as well as the high cost in real physical environment. Alternatively, simulation has been considered as a viable and important tool for acquiring datasets in different environments, but it mostly targeted rigid and soft body systems. There is currently dearth of work for more complex fluid systems interacting with immersed solids that can be efficiently and accurately simulated for robot training purposes. In this paper, we propose a new platform called "FishGym", which can be used to train fish-like underwater robots. The framework consists of a robotic fish modeling module using articulated body with skinning, a GPU-based high-performance localized two-way coupled fluid-structure interaction simulation module that handles both finite and infinitely large domains, as well as a reinforcement learning module. We leveraged existing training methods with adaptations to underwater fish-like robots and obtained learned control policies for multiple benchmark tasks. The training results are demonstrated with reasonable motion trajectories, with comparisons and analyses to empirical models as well as known real fish swimming behaviors to highlight the advantages of the proposed platform.
Automatic spinal curvature measurement on ultrasound spine images using Faster R-CNN
Apr 20, 2022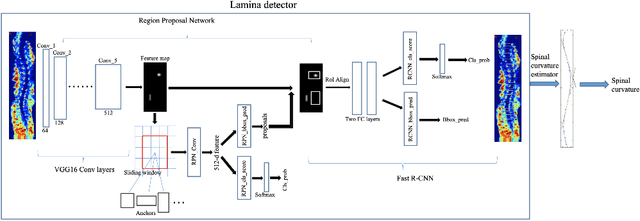
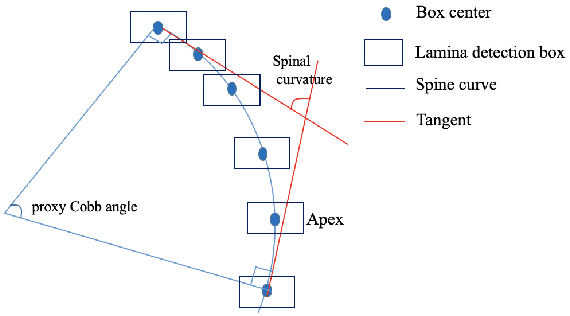
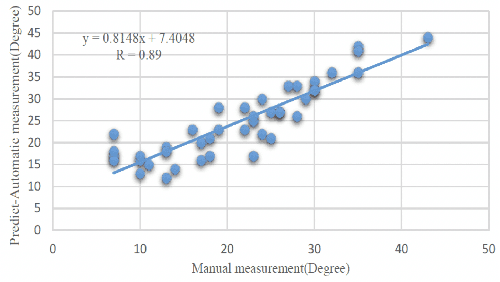
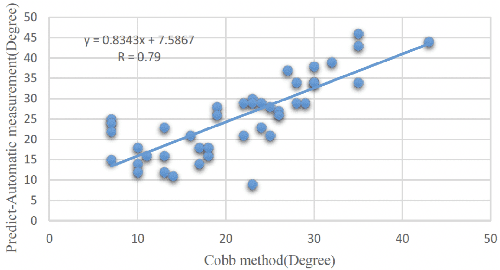
Ultrasound spine imaging technique has been applied to the assessment of spine deformity. However, manual measurements of scoliotic angles on ultrasound images are time-consuming and heavily rely on raters experience. The objectives of this study are to construct a fully automatic framework based on Faster R-CNN for detecting vertebral lamina and to measure the fitting spinal curves from the detected lamina pairs. The framework consisted of two closely linked modules: 1) the lamina detector for identifying and locating each lamina pairs on ultrasound coronal images, and 2) the spinal curvature estimator for calculating the scoliotic angles based on the chain of detected lamina. Two hundred ultrasound images obtained from AIS patients were identified and used for the training and evaluation of the proposed method. The experimental results showed the 0.76 AP on the test set, and the Mean Absolute Difference (MAD) between automatic and manual measurement which was within the clinical acceptance error. Meanwhile the correlation between automatic measurement and Cobb angle from radiographs was 0.79. The results revealed that our proposed technique could provide accurate and reliable automatic curvature measurements on ultrasound spine images for spine deformities.