 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Mode Connectivity in Loss Landscapes and Adversarial Robustness
Apr 30, 2020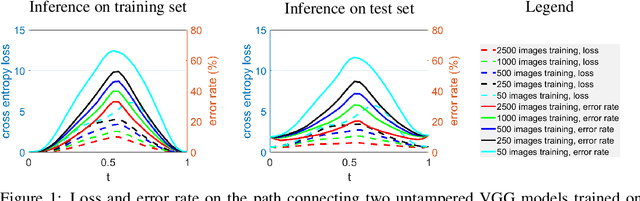

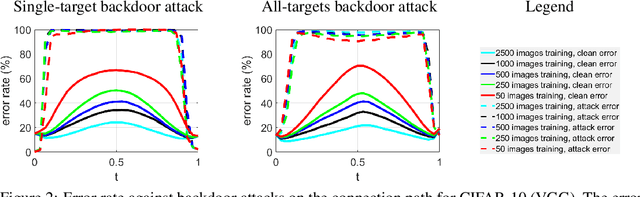
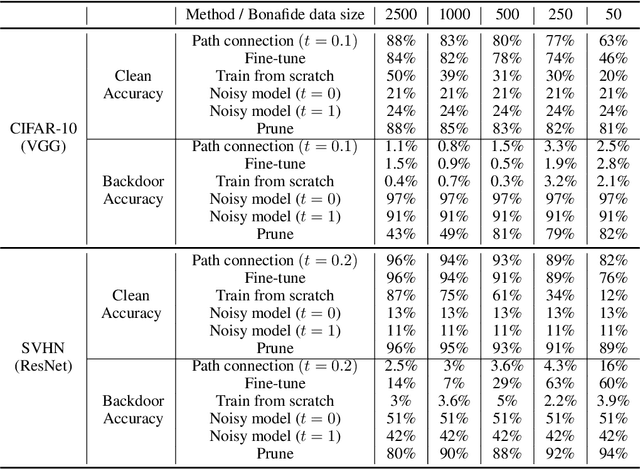
Mode connectivity provides novel geometric insights on analyzing loss landscapes and enables building high-accuracy pathways between well-trained neural networks. In this work, we propose to employ mode connectivity in loss landscapes to study the adversarial robustness of deep neural networks, and provide novel methods for improving this robustness. Our experiments cover various types of adversarial attacks applied to different network architectures and datasets. When network models are tampered with backdoor or error-injection attacks, our results demonstrate that the path connection learned using limited amount of bonafide data can effectively mitigate adversarial effects while maintaining the original accuracy on clean data. Therefore, mode connectivity provides users with the power to repair backdoored or error-injected models. We also use mode connectivity to investigate the loss landscapes of regular and robust models against evasion attacks. Experiments show that there exists a barrier in adversarial robustness loss on the path connecting regular and adversarially-trained models. A high correlation is observed between the adversarial robustness loss and the largest eigenvalue of the input Hessian matrix, for which theoretical justifications are provided. Our results suggest that mode connectivity offers a holistic tool and practical means for evaluating and improving adversarial robustness.
Towards Real-Time DNN Inference on Mobile Platforms with Model Pruning and Compiler Optimization
Apr 22, 2020
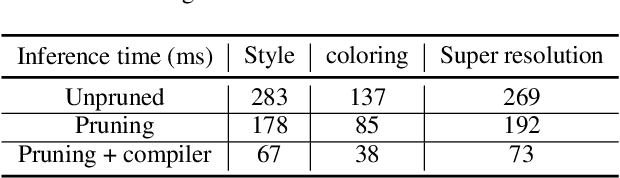
High-end mobile platforms rapidly serve as primary computing devices for a wide range of Deep Neural Network (DNN) applications. However, the constrained computation and storage resources on these devices still pose significant challenges for real-time DNN inference executions. To address this problem, we propose a set of hardware-friendly structured model pruning and compiler optimization techniques to accelerate DNN executions on mobile devices. This demo shows that these optimizations can enable real-time mobile execution of multiple DNN applications, including style transfer, DNN coloring and super resolution.
Multi-Person Pose Estimation with Enhanced Feature Aggregation and Selection
Mar 20, 2020
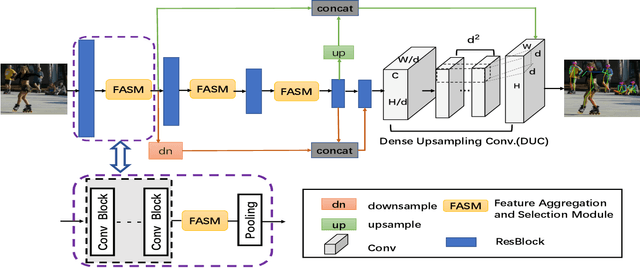
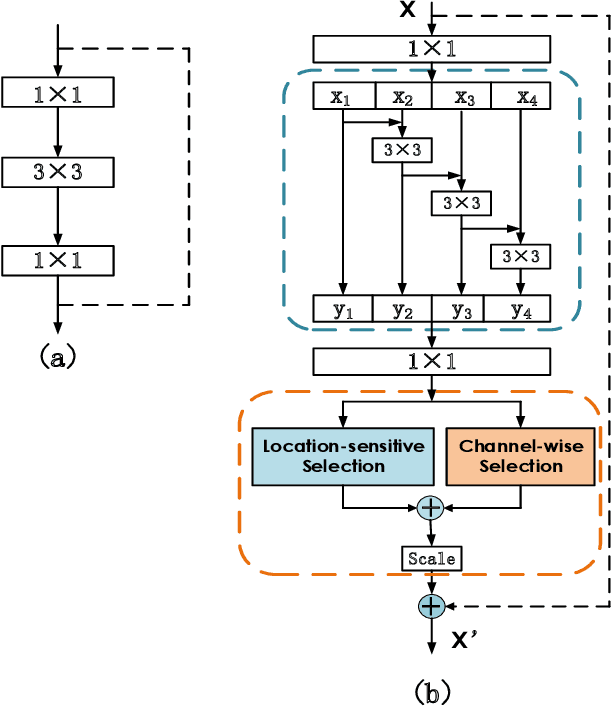
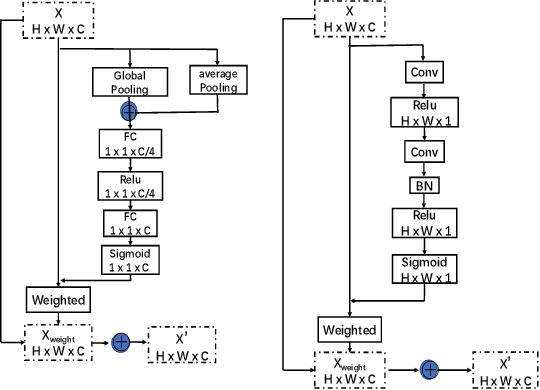
We propose a novel Enhanced Feature Aggregation and Selection network (EFASNet) for multi-person 2D human pose estimation. Due to enhanced feature representation, our method can well handle crowded, cluttered and occluded scenes. More specifically, a Feature Aggregation and Selection Module (FASM), which constructs hierarchical multi-scale feature aggregation and makes the aggregated features discriminative, is proposed to get more accurate fine-grained representation, leading to more precise joint locations. Then, we perform a simple Feature Fusion (FF) strategy which effectively fuses high-resolution spatial features and low-resolution semantic features to obtain more reliable context information for well-estimated joints. Finally, we build a Dense Upsampling Convolution (DUC) module to generate more precise prediction, which can recover missing joint details that are usually unavailable in common upsampling process. As a result, the predicted keypoint heatmaps are more accurate. Comprehensive experiments demonstrate that the proposed approach outperforms the state-of-the-art methods and achieves the superior performance over three benchmark datasets: the recent big dataset CrowdPose, the COCO keypoint detection dataset and the MPII Human Pose dataset. Our code will be released upon acceptance.
A Privacy-Preserving DNN Pruning and Mobile Acceleration Framework
Mar 13, 2020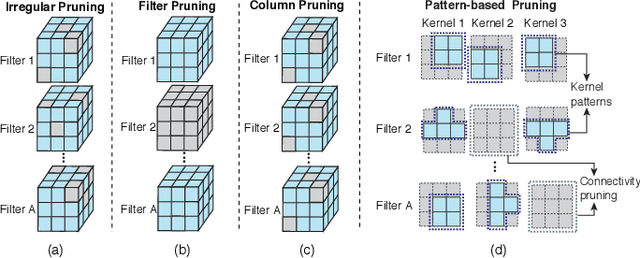
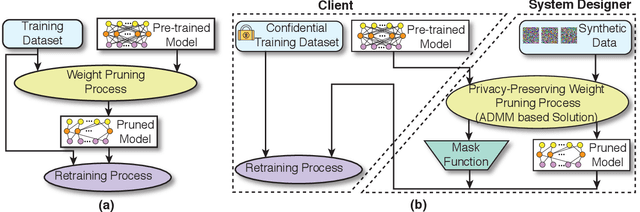
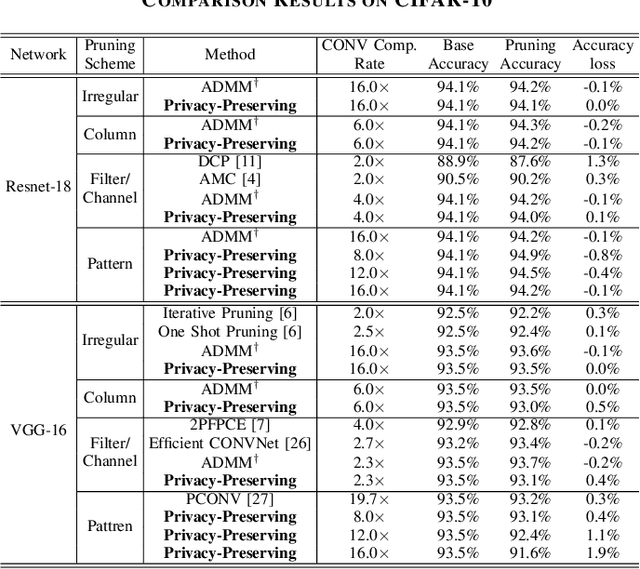
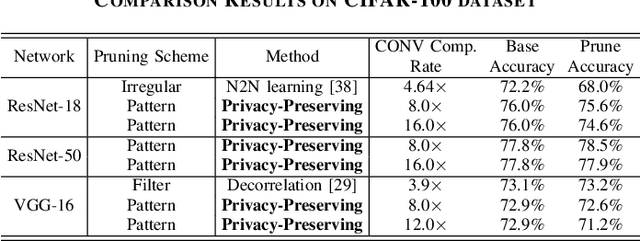
To facilitate the deployment of deep neural networks (DNNs) on resource-constrained computing systems, DNN model compression methods have been proposed. However, previous methods mainly focus on reducing the model size and/or improving hardware performance, without considering the data privacy requirement. This paper proposes a privacy-preserving model compression framework that formulates a privacy-preserving DNN weight pruning problem and develops an ADMM based solution to support different weight pruning schemes. We consider the case that the system designer will perform weight pruning on a pre-trained model provided by the client, whereas the client cannot share her confidential training dataset. To mitigate the non-availability of the training dataset, the system designer distills the knowledge of a pre-trained model into a pruned model using only randomly generated synthetic data. Then the client's effort is simply reduced to performing the retraining process using her confidential training dataset, which is similar as the DNN training process with the help of the mask function from the system designer. Both algorithmic and hardware experiments validate the effectiveness of the proposed framework.
Security of Deep Learning based Lane Keeping System under Physical-World Adversarial Attack
Mar 03, 2020
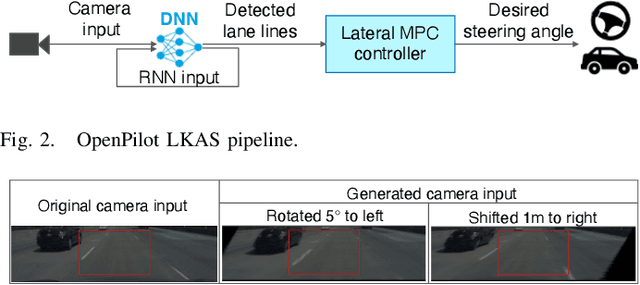
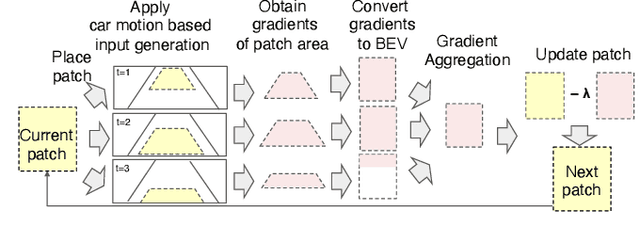

Lane-Keeping Assistance System (LKAS) is convenient and widely available today, but also extremely security and safety critical. In this work, we design and implement the first systematic approach to attack real-world DNN-based LKASes. We identify dirty road patches as a novel and domain-specific threat model for practicality and stealthiness. We formulate the attack as an optimization problem, and address the challenge from the inter-dependencies among attacks on consecutive camera frames. We evaluate our approach on a state-of-the-art LKAS and our preliminary results show that our attack can successfully cause it to drive off lane boundaries within as short as 1.3 seconds.
Automatic Perturbation Analysis on General Computational Graphs
Feb 28, 2020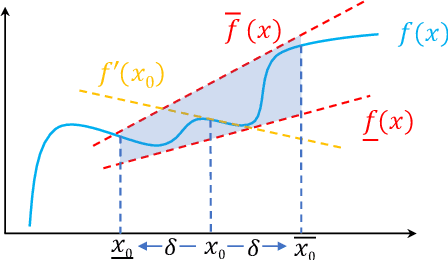

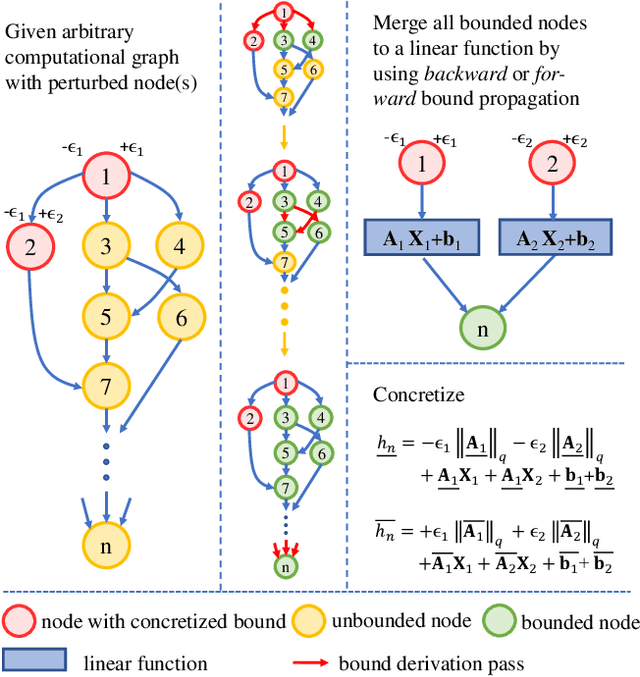

Linear relaxation based perturbation analysis for neural networks, which aims to compute tight linear bounds of output neurons given a certain amount of input perturbation, has become a core component in robustness verification and certified defense. However, the majority of linear relaxation based methods only consider feed-forward ReLU networks. While several works extended them to relatively complicated networks, they often need tedious manual derivations and implementation which are arduous and error-prone. Their limited flexibility makes it difficult to handle more complicated tasks. In this paper, we take a significant leap by developing an automatic perturbation analysis algorithm to enable perturbation analysis on any neural network structure, and its computation can be done automatically in a similar manner as the back-propagation algorithm for gradient computation. The main idea is to express a network as a computational graph and then generalize linear relaxation algorithms such as CROWN as a graph algorithm. Our algorithm itself is differentiable and integrated with PyTorch, which allows to optimize network parameters to reshape bounds into desired specifications, enabling automatic robustness verification and certified defense. In particular, we demonstrate a few tasks that are not easily achievable without an automatic framework. We first perform certified robust training and robustness verification for complex natural language models which could be challenging with manual derivation and implementation. We further show that our algorithm can be used for tasks beyond certified defense - we create a neural network with a provably flat optimization landscape and study its generalization capability, and we show that this network can preserve accuracy better after aggressive weight quantization. Code is available at https://github.com/KaidiXu/auto_LiRPA.
Defending against Backdoor Attack on Deep Neural Networks
Feb 26, 2020
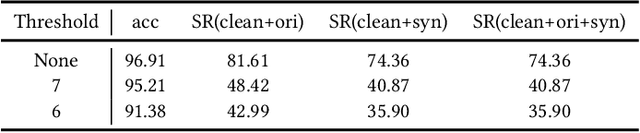
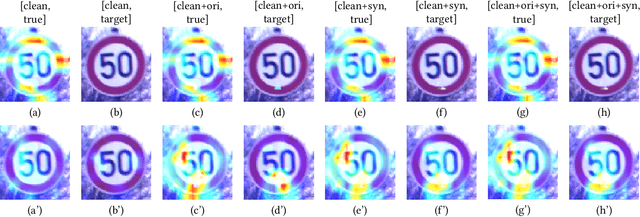
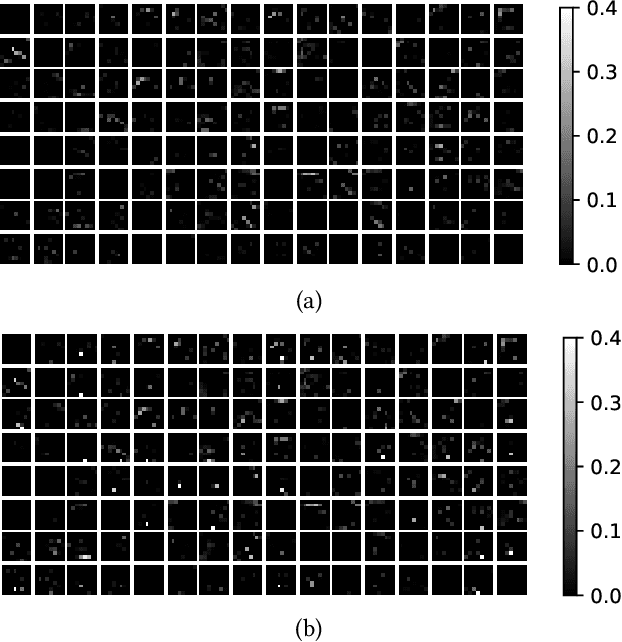
Although deep neural networks (DNNs) have achieved a great success in various computer vision tasks, it is recently found that they are vulnerable to adversarial attacks. In this paper, we focus on the so-called \textit{backdoor attack}, which injects a backdoor trigger to a small portion of training data (also known as data poisoning) such that the trained DNN induces misclassification while facing examples with this trigger. To be specific, we carefully study the effect of both real and synthetic backdoor attacks on the internal response of vanilla and backdoored DNNs through the lens of Gard-CAM. Moreover, we show that the backdoor attack induces a significant bias in neuron activation in terms of the $\ell_\infty$ norm of an activation map compared to its $\ell_1$ and $\ell_2$ norm. Spurred by our results, we propose the \textit{$\ell_\infty$-based neuron pruning} to remove the backdoor from the backdoored DNN. Experiments show that our method could effectively decrease the attack success rate, and also hold a high classification accuracy for clean images.
Towards an Efficient and General Framework of Robust Training for Graph Neural Networks
Feb 25, 2020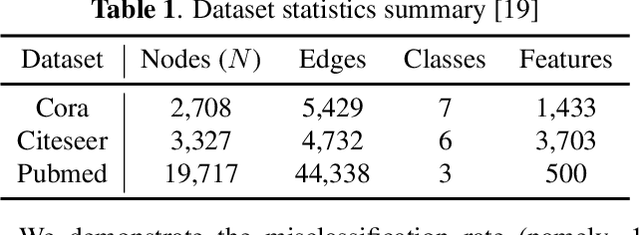
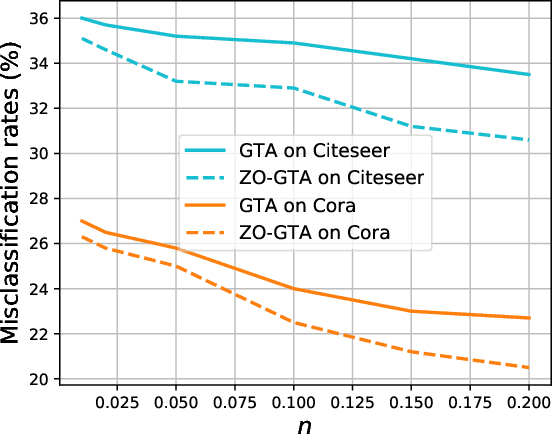
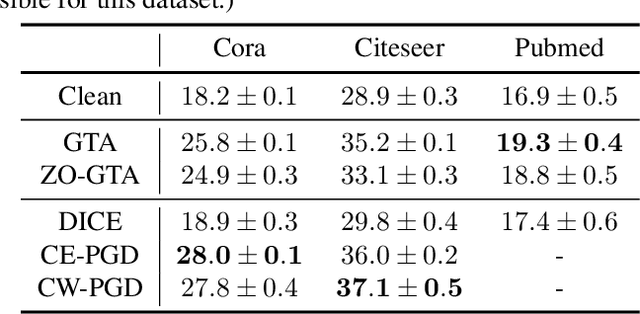
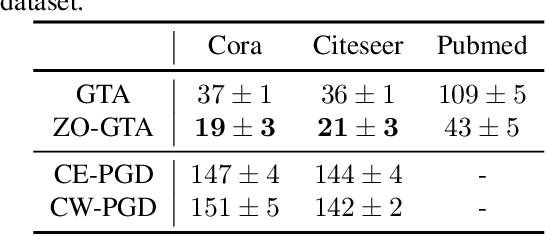
Graph Neural Networks (GNNs) have made significant advances on several fundamental inference tasks. As a result, there is a surge of interest in using these models for making potentially important decisions in high-regret applications. However, despite GNNs' impressive performance, it has been observed that carefully crafted perturbations on graph structures (or nodes attributes) lead them to make wrong predictions. Presence of these adversarial examples raises serious security concerns. Most of the existing robust GNN design/training methods are only applicable to white-box settings where model parameters are known and gradient based methods can be used by performing convex relaxation of the discrete graph domain. More importantly, these methods are not efficient and scalable which make them infeasible in time sensitive tasks and massive graph datasets. To overcome these limitations, we propose a general framework which leverages the greedy search algorithms and zeroth-order methods to obtain robust GNNs in a generic and an efficient manner. On several applications, we show that the proposed techniques are significantly less computationally expensive and, in some cases, more robust than the state-of-the-art methods making them suitable to large-scale problems which were out of the reach of traditional robust training methods.
BLK-REW: A Unified Block-based DNN Pruning Framework using Reweighted Regularization Method
Feb 22, 2020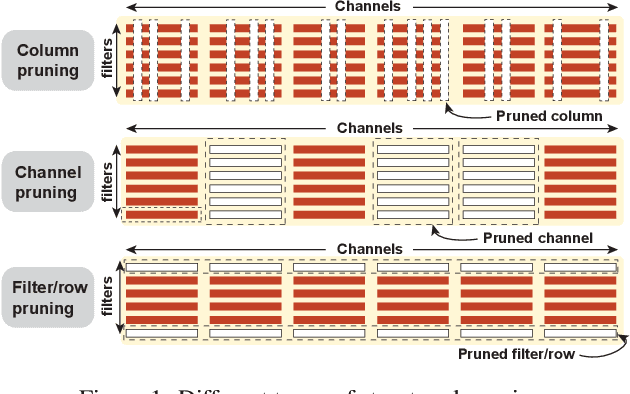
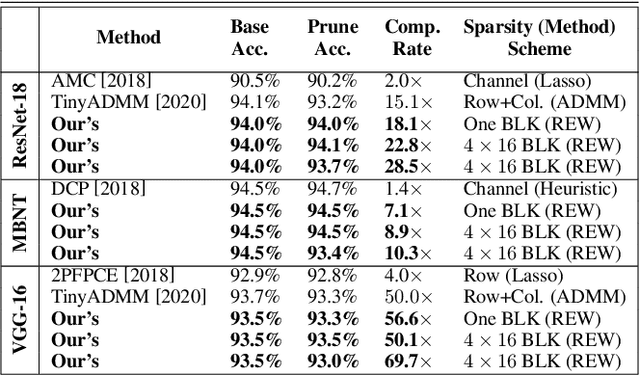
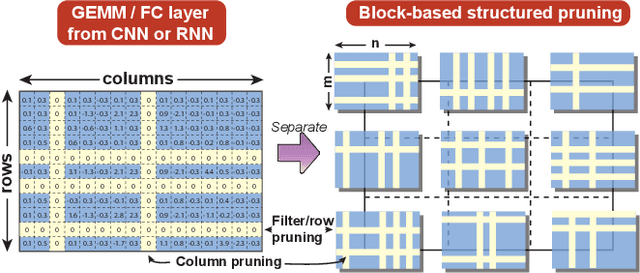
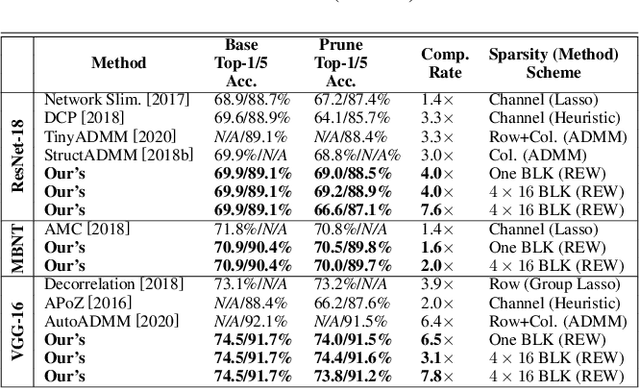
Accelerating DNN execution on various resource-limited computing platforms has been a long-standing problem. Prior works utilize l1-based group lasso or dynamic regularization such as ADMM to perform structured pruning on DNN models to leverage the parallel computing architectures. However, both of the pruning dimensions and pruning methods lack universality, which leads to degraded performance and limited applicability. To solve the problem, we propose a new block-based pruning framework that comprises a general and flexible structured pruning dimension as well as a powerful and efficient reweighted regularization method. Our framework is universal, which can be applied to both CNNs and RNNs, implying complete support for the two major kinds of computation-intensive layers (i.e., CONV and FC layers). To complete all aspects of the pruning-for-acceleration task, we also integrate compiler-based code optimization into our framework that can perform DNN inference in a real-time manner. To the best of our knowledge, it is the first time that the weight pruning framework achieves universal coverage for both CNNs and RNNs with real-time mobile acceleration and no accuracy compromise.
AdvMS: A Multi-source Multi-cost Defense Against Adversarial Attacks
Feb 19, 2020
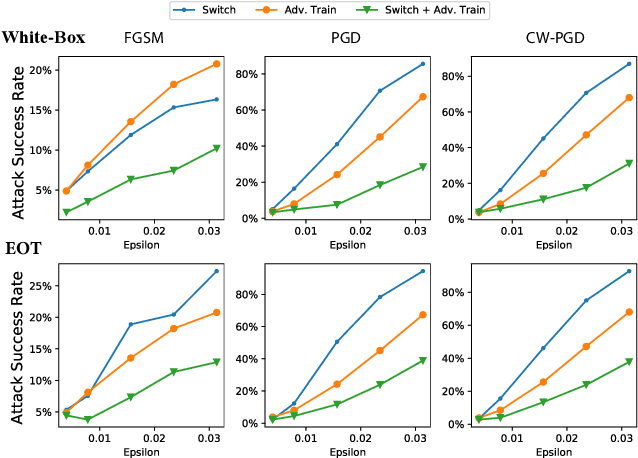
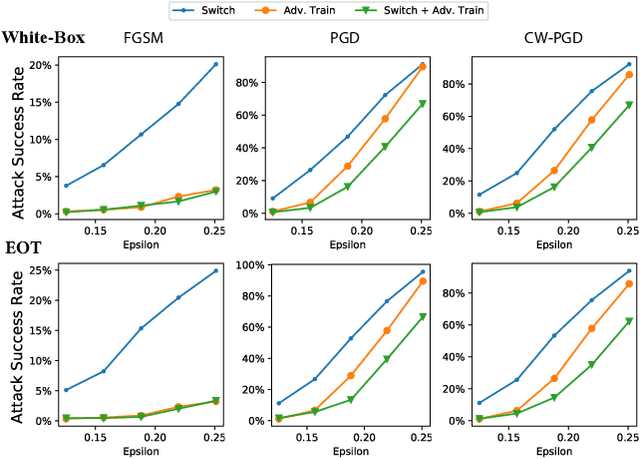
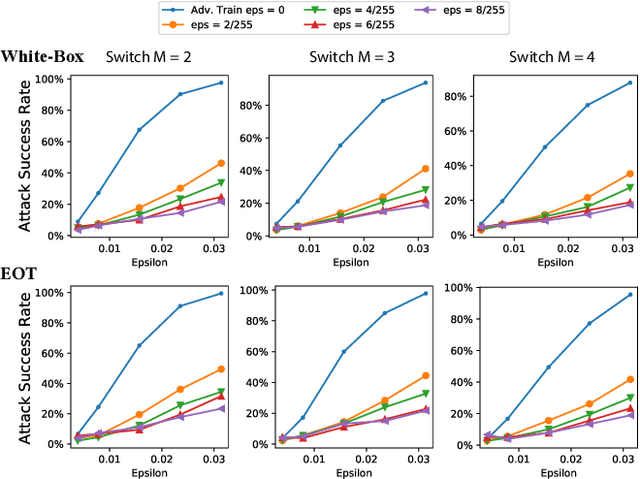
Designing effective defense against adversarial attacks is a crucial topic as deep neural networks have been proliferated rapidly in many security-critical domains such as malware detection and self-driving cars. Conventional defense methods, although shown to be promising, are largely limited by their single-source single-cost nature: The robustness promotion tends to plateau when the defenses are made increasingly stronger while the cost tends to amplify. In this paper, we study principles of designing multi-source and multi-cost schemes where defense performance is boosted from multiple defending components. Based on this motivation, we propose a multi-source and multi-cost defense scheme, Adversarially Trained Model Switching (AdvMS), that inherits advantages from two leading schemes: adversarial training and random model switching. We show that the multi-source nature of AdvMS mitigates the performance plateauing issue and the multi-cost nature enables improving robustness at a flexible and adjustable combination of costs over different factors which can better suit specific restrictions and needs in practice.