 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Real-Time LiDAR 3D Object Detection on a Mobile Device
Dec 26, 2020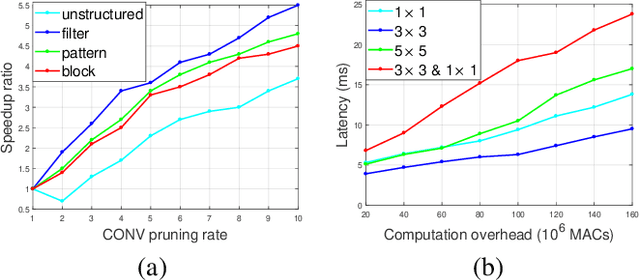
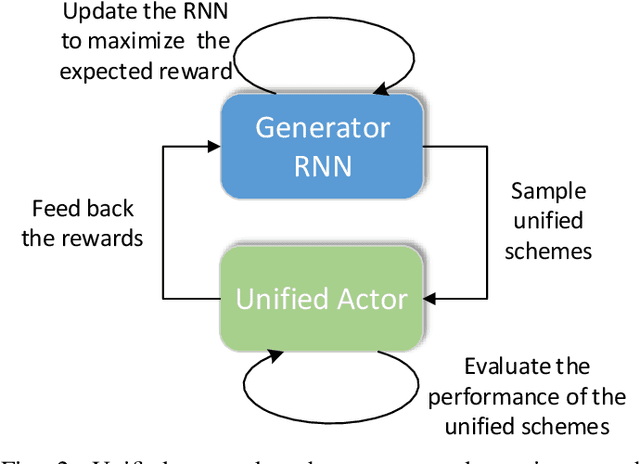
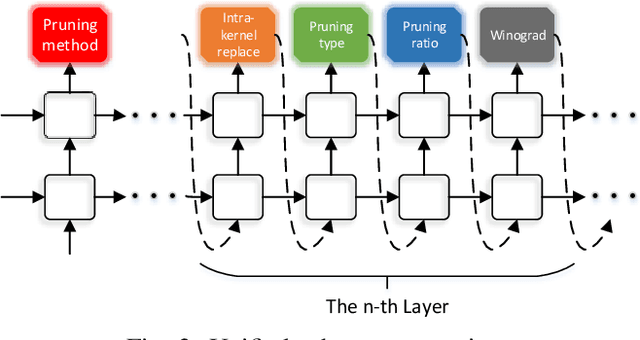

3D object detection is an important task, especially in the autonomous driving application domain. However, it is challenging to support the real-time performance with the limited computation and memory resources on edge-computing devices in self-driving cars. To achieve this, we propose a compiler-aware unified framework incorporating network enhancement and pruning search with the reinforcement learning techniques, to enable real-time inference of 3D object detection on the resource-limited edge-computing devices. Specifically, a generator Recurrent Neural Network (RNN) is employed to provide the unified scheme for both network enhancement and pruning search automatically, without human expertise and assistance. And the evaluated performance of the unified schemes can be fed back to train the generator RNN. The experimental results demonstrate that the proposed framework firstly achieves real-time 3D object detection on mobile devices (Samsung Galaxy S20 phone) with competitive detection performance.
Zeroth-Order Hybrid Gradient Descent: Towards A Principled Black-Box Optimization Framework
Dec 21, 2020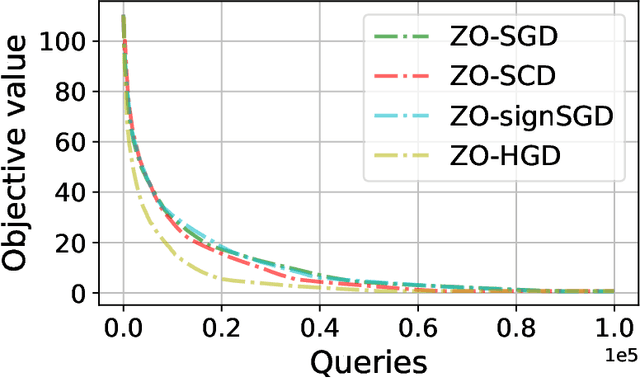
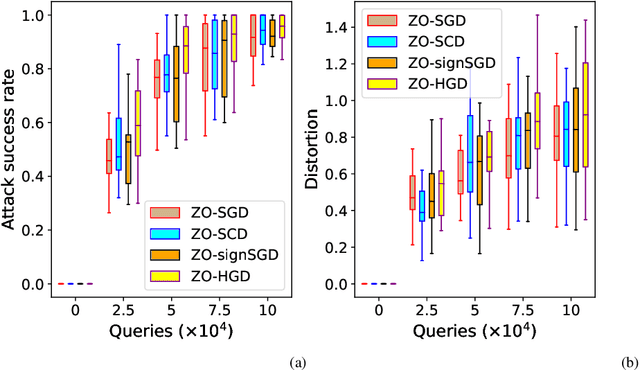
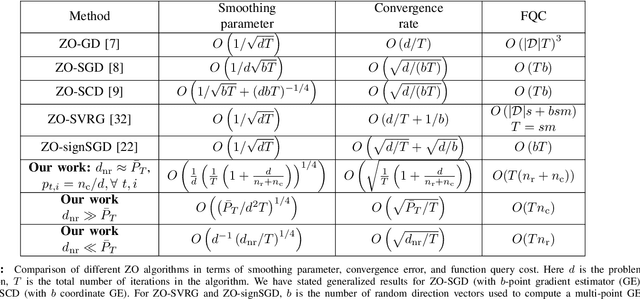

In this work, we focus on the study of stochastic zeroth-order (ZO) optimization which does not require first-order gradient information and uses only function evaluations. The problem of ZO optimization has emerged in many recent machine learning applications, where the gradient of the objective function is either unavailable or difficult to compute. In such cases, we can approximate the full gradients or stochastic gradients through function value based gradient estimates. Here, we propose a novel hybrid gradient estimator (HGE), which takes advantage of the query-efficiency of random gradient estimates as well as the variance-reduction of coordinate-wise gradient estimates. We show that with a graceful design in coordinate importance sampling, the proposed HGE-based ZO optimization method is efficient both in terms of iteration complexity as well as function query cost. We provide a thorough theoretical analysis of the convergence of our proposed method for non-convex, convex, and strongly-convex optimization. We show that the convergence rate that we derive generalizes the results for some prominent existing methods in the nonconvex case, and matches the optimal result in the convex case. We also corroborate the theory with a real-world black-box attack generation application to demonstrate the empirical advantage of our method over state-of-the-art ZO optimization approaches.
Mix and Match: A Novel FPGA-Centric Deep Neural Network Quantization Framework
Dec 12, 2020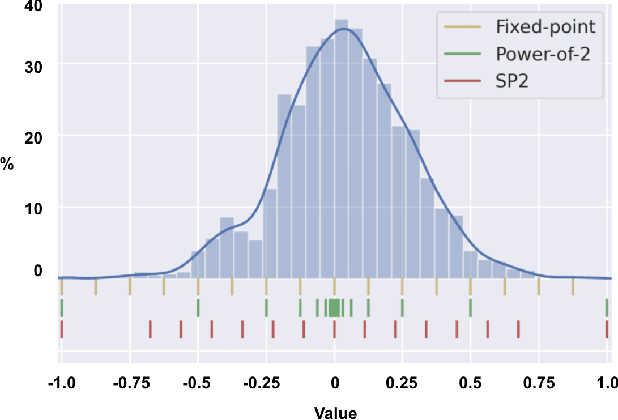
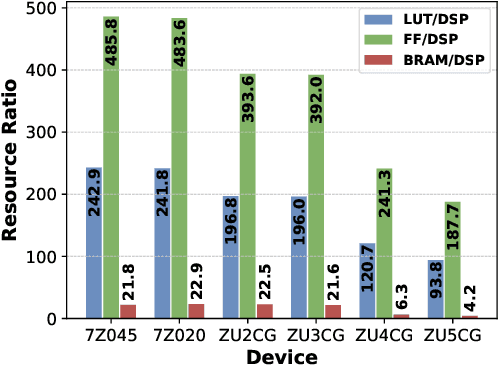
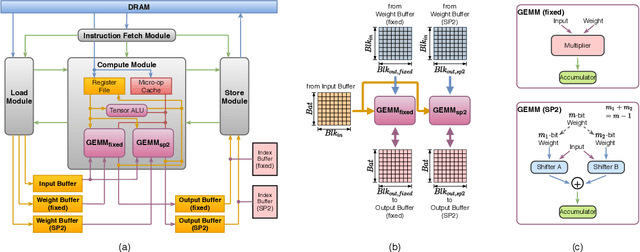
Deep Neural Networks (DNNs) have achieved extraordinary performance in various application domains. To support diverse DNN models, efficient implementations of DNN inference on edge-computing platforms, e.g., ASICs, FPGAs, and embedded systems, are extensively investigated. Due to the huge model size and computation amount, model compression is a critical step to deploy DNN models on edge devices. This paper focuses on weight quantization, a hardware-friendly model compression approach that is complementary to weight pruning. Unlike existing methods that use the same quantization scheme for all weights, we propose the first solution that applies different quantization schemes for different rows of the weight matrix. It is motivated by (1) the distribution of the weights in the different rows are not the same; and (2) the potential of achieving better utilization of heterogeneous FPGA hardware resources. To achieve that, we first propose a hardware-friendly quantization scheme named sum-of-power-of-2 (SP2) suitable for Gaussian-like weight distribution, in which the multiplication arithmetic can be replaced with logic shifter and adder, thereby enabling highly efficient implementations with the FPGA LUT resources. In contrast, the existing fixed-point quantization is suitable for Uniform-like weight distribution and can be implemented efficiently by DSP. Then to fully explore the resources, we propose an FPGA-centric mixed scheme quantization (MSQ) with an ensemble of the proposed SP2 and the fixed-point schemes. Combining the two schemes can maintain, or even increase accuracy due to better matching with weight distributions.
6.7ms on Mobile with over 78% ImageNet Accuracy: Unified Network Pruning and Architecture Search for Beyond Real-Time Mobile Acceleration
Dec 01, 2020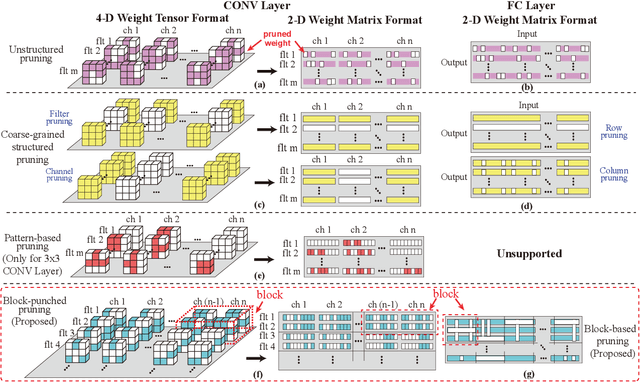
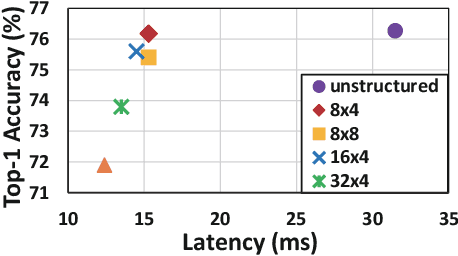
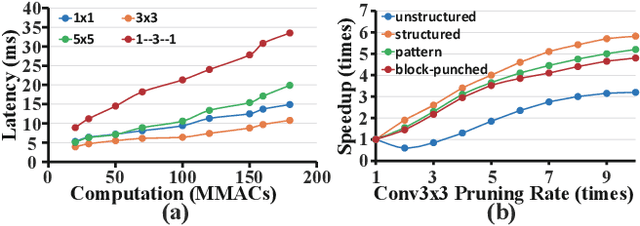
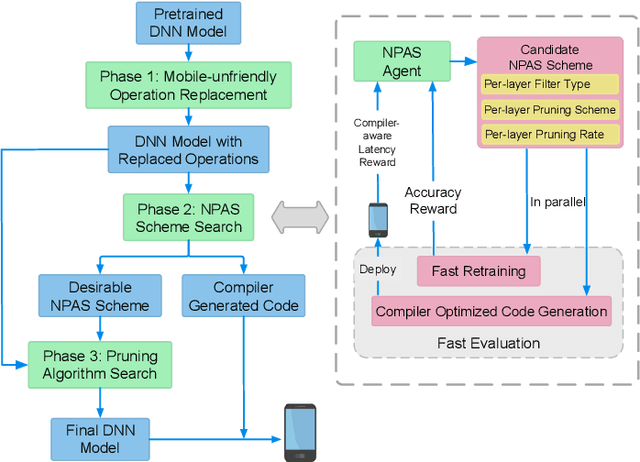
With the increasing demand to efficiently deploy DNNs on mobile edge devices, it becomes much more important to reduce unnecessary computation and increase the execution speed. Prior methods towards this goal, including model compression and network architecture search (NAS), are largely performed independently and do not fully consider compiler-level optimizations which is a must-do for mobile acceleration. In this work, we first propose (i) a general category of fine-grained structured pruning applicable to various DNN layers, and (ii) a comprehensive, compiler automatic code generation framework supporting different DNNs and different pruning schemes, which bridge the gap of model compression and NAS. We further propose NPAS, a compiler-aware unified network pruning, and architecture search. To deal with large search space, we propose a meta-modeling procedure based on reinforcement learning with fast evaluation and Bayesian optimization, ensuring the total number of training epochs comparable with representative NAS frameworks. Our framework achieves 6.7ms, 5.9ms, 3.9ms ImageNet inference times with 78.2%, 75% (MobileNet-V3 level), and 71% (MobileNet-V2 level) Top-1 accuracy respectively on an off-the-shelf mobile phone, consistently outperforming prior work.
Fast and Complete: Enabling Complete Neural Network Verification with Rapid and Massively Parallel Incomplete Verifiers
Nov 27, 2020
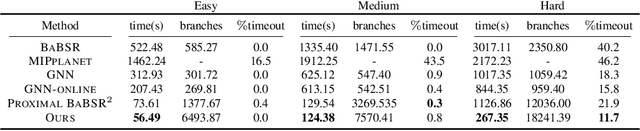
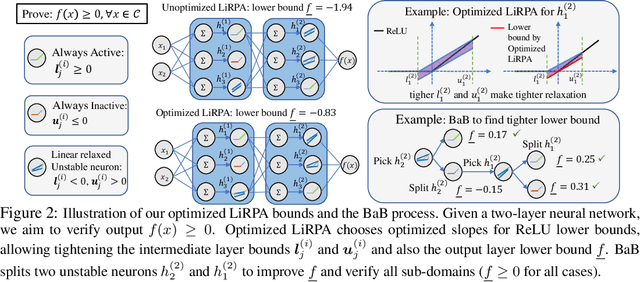

Formal verification of neural networks (NNs) is a challenging and important problem. Existing efficient complete solvers typically require the branch-and-bound (BaB) process, which splits the problem domain into sub-domains and solves each sub-domain using faster but weaker incomplete verifiers, such as Linear Programming (LP) on linearly relaxed sub-domains. In this paper, we propose to use the backward mode linear relaxation based perturbation analysis (LiRPA) to replace LP during the BaB process, which can be efficiently implemented on the typical machine learning accelerators such as GPUs and TPUs. However, unlike LP, LiRPA when applied naively can produce much weaker bounds and even cannot check certain conflicts of sub-domains during splitting, making the entire procedure incomplete after BaB. To address these challenges, we apply a fast gradient based bound tightening procedure combined with batch splits and the design of minimal usage of LP bound procedure, enabling us to effectively use LiRPA on the accelerator hardware for the challenging complete NN verification problem and significantly outperform LP-based approaches. On a single GPU, we demonstrate an order of magnitude speedup compared to existing LP-based approaches.
Learned Fine-Tuner for Incongruous Few-Shot Learning
Oct 20, 2020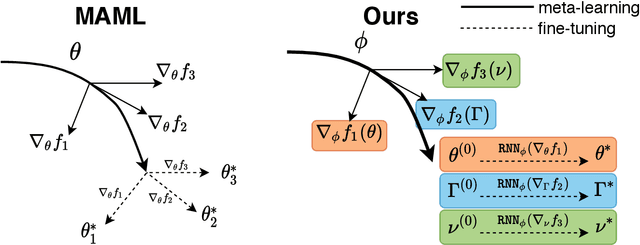
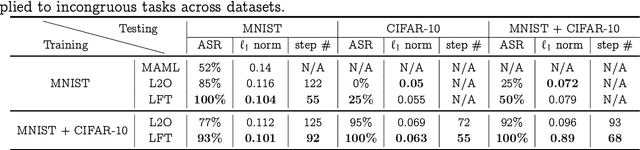
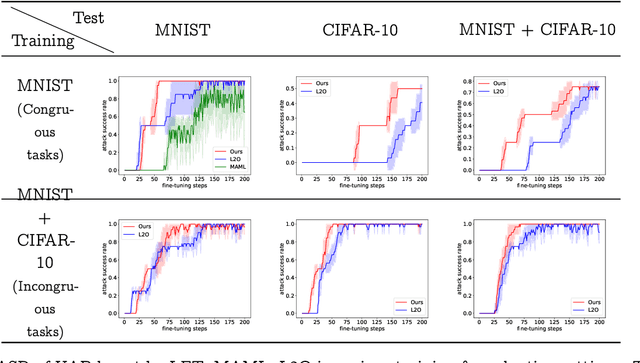
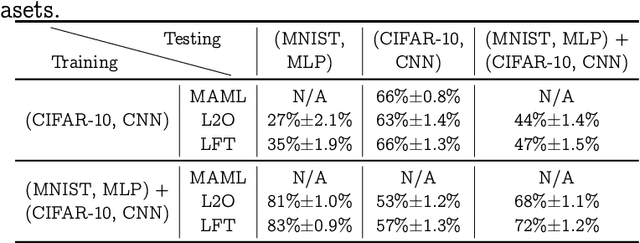
Model-agnostic meta-learning (MAML) effectively meta-learns an initialization of model parameters for few-shot learning where all learning problems share the same format of model parameters -- congruous meta-learning. We extend MAML to incongruous meta-learning where different yet related few-shot learning problems may not share any model parameters. A Learned Fine Tuner (LFT) is used to replace hand-designed optimizers such as SGD for the task-specific fine-tuning. Here, MAML instead meta-learns the parameters of this LFT across incongruous tasks leveraging the learning-to-optimize (L2O) framework such that models fine-tuned with LFT (even from random initializations) adapt quickly to new tasks. As novel contributions, we show that the use of LFT within MAML (i) offers the capability to tackle few-shot learning tasks by meta-learning across incongruous yet related problems (e.g., classification over images of different sizes and model architectures), and (ii) can efficiently work with first-order and derivative-free few-shot learning problems. Theoretically, we quantify the difference between LFT (for MAML) and L2O. Empirically, we demonstrate the effectiveness of LFT through both synthetic and real problems and a novel application of generating universal adversarial attacks across different image sources in the few-shot learning regime.
MSP: An FPGA-Specific Mixed-Scheme, Multi-Precision Deep Neural Network Quantization Framework
Sep 16, 2020
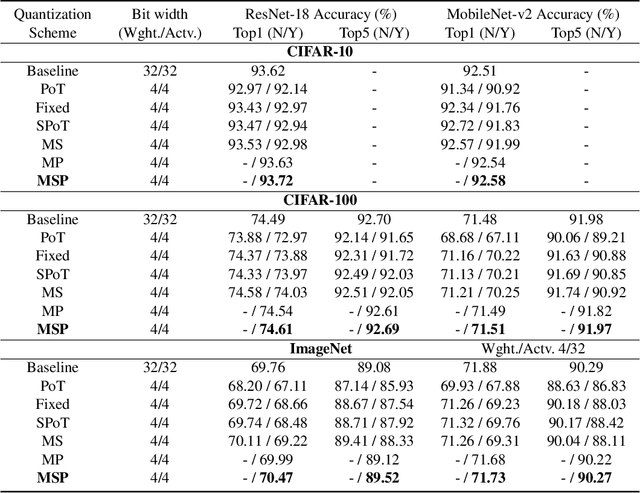
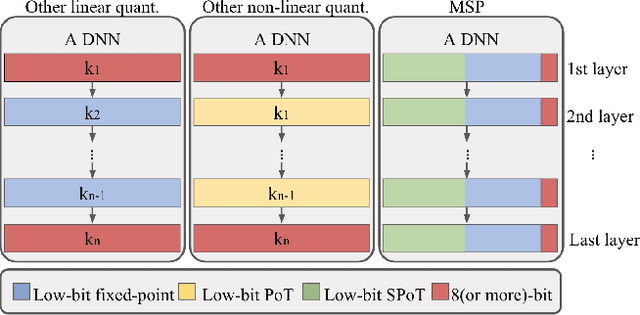
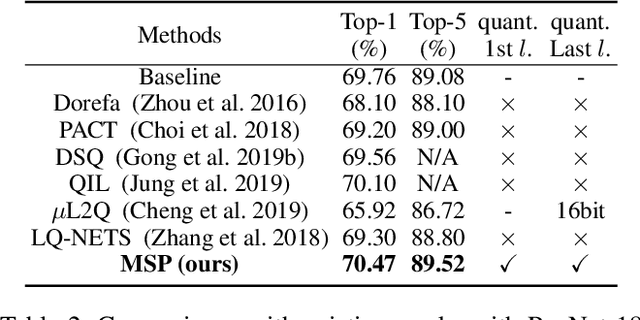
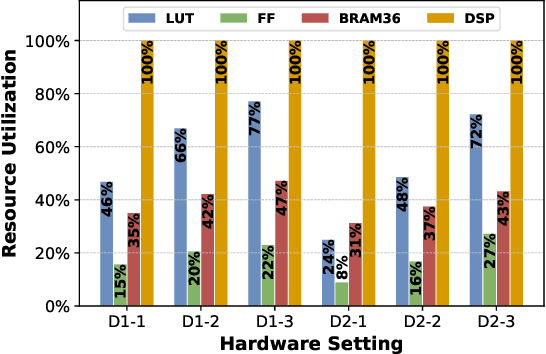
With the tremendous success of deep learning, there exists imminent need to deploy deep learning models onto edge devices. To tackle the limited computing and storage resources in edge devices, model compression techniques have been widely used to trim deep neural network (DNN) models for on-device inference execution. This paper targets the commonly used FPGA (field programmable gate array) devices as the hardware platforms for DNN edge computing. We focus on the DNN quantization as the main model compression technique, since DNN quantization has been of great importance for the implementations of DNN models on the hardware platforms. The novelty of this work comes in twofold: (i) We propose a mixed-scheme DNN quantization method that incorporates both the linear and non-linear number systems for quantization, with the aim to boost the utilization of the heterogeneous computing resources, i.e., LUTs (look up tables) and DSPs (digital signal processors) on an FPGA. Note that all the existing (single-scheme) quantization methods can only utilize one type of resources (either LUTs or DSPs for the MAC (multiply-accumulate) operations in deep learning computations. (ii) We use a quantization method that supports multiple precisions along the intra-layer dimension, while the existing quantization methods apply multi-precision quantization along the inter-layer dimension. The intra-layer multi-precision method can uniform the hardware configurations for different layers to reduce computation overhead and at the same time preserve the model accuracy as the inter-layer approach.
Hold Tight and Never Let Go: Security of Deep Learning based Automated Lane Centering under Physical-World Attack
Sep 14, 2020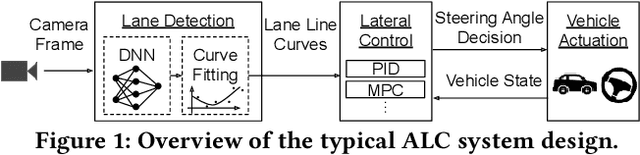


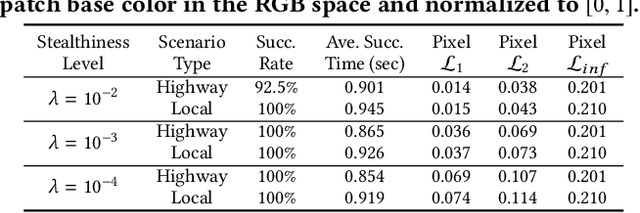
Automated Lane Centering (ALC) systems are convenient and widely deployed today, but also highly security and safety critical. In this work, we are the first to systematically study the security of state-of-the-art deep learning based ALC systems in their designed operational domains under physical-world adversarial attacks. We formulate the problem with a safety-critical attack goal, and a novel and domain-specific attack vector: dirty road patches. To systematically generate the attack, we adopt an optimization-based approach and overcome domain-specific design challenges such as camera frame inter-dependencies due to dynamic vehicle actuation, and the lack of objective function design for lane detection models. We evaluate our attack method on a production ALC system using 80 attack scenarios from real-world driving traces. The results show that our attack is highly effective with over 92% success rates and less than 0.95 sec average success time, which is substantially lower than the average driver reaction time. Such high attack effectiveness is also found (1) robust to motion model inaccuracies, different lane detection model designs, and physical-world factors, and (2) stealthy from the driver's view. To concretely understand the end-to-end safety consequences, we further evaluate on concrete real-world attack scenarios using a production-grade simulator, and find that our attack can successfully cause the victim to hit the highway concrete barrier or a truck in the opposite direction with 98% and 100% success rates. We also discuss defense directions.
Alleviating Human-level Shift : A Robust Domain Adaptation Method for Multi-person Pose Estimation
Aug 13, 2020
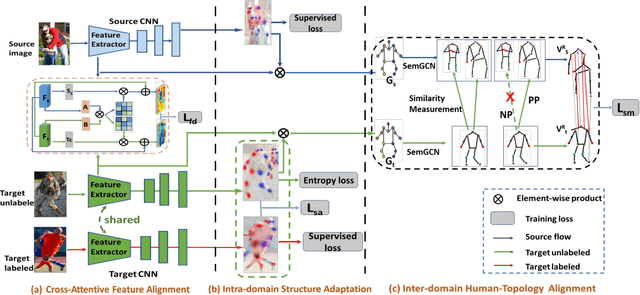
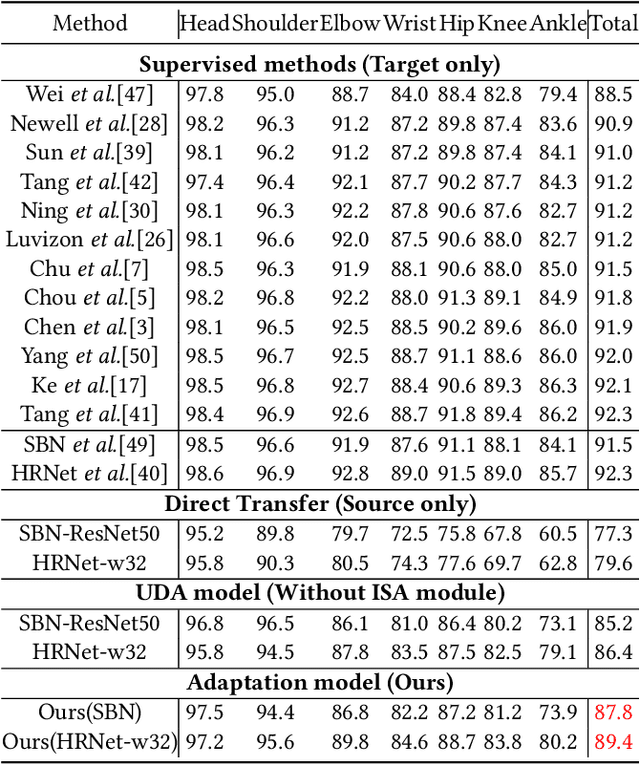
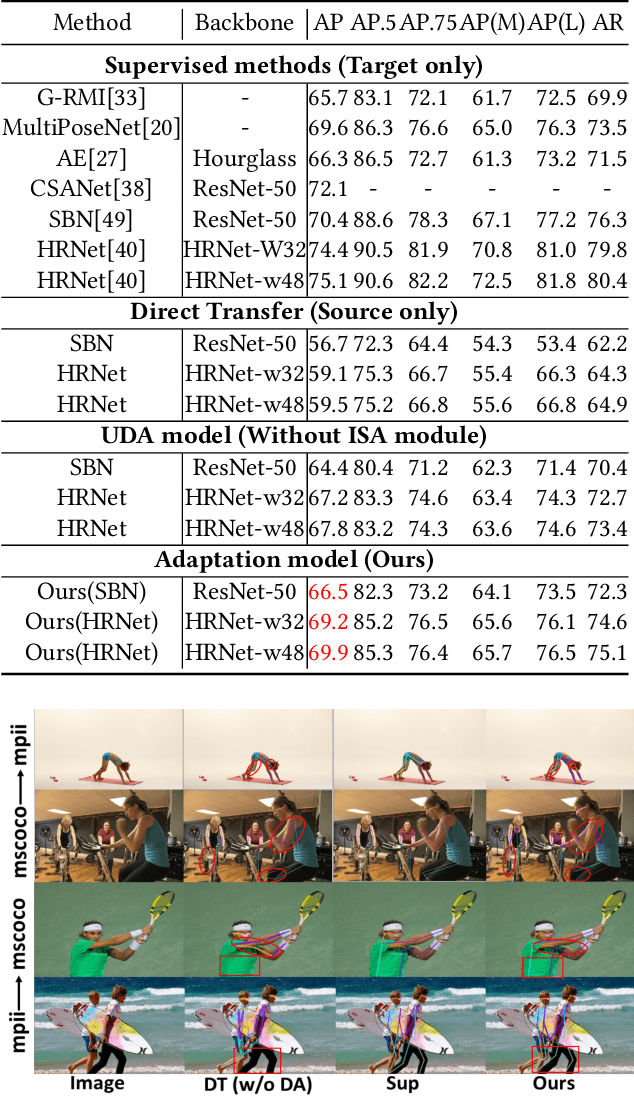
Human pose estimation has been widely studied with much focus on supervised learning requiring sufficient annotations. However, in real applications, a pretrained pose estimation model usually need be adapted to a novel domain with no labels or sparse labels. Such domain adaptation for 2D pose estimation hasn't been explored. The main reason is that a pose, by nature, has typical topological structure and needs fine-grained features in local keypoints. While existing adaptation methods do not consider topological structure of object-of-interest and they align the whole images coarsely. Therefore, we propose a novel domain adaptation method for multi-person pose estimation to conduct the human-level topological structure alignment and fine-grained feature alignment. Our method consists of three modules: Cross-Attentive Feature Alignment (CAFA), Intra-domain Structure Adaptation (ISA) and Inter-domain Human-Topology Alignment (IHTA) module. The CAFA adopts a bidirectional spatial attention module (BSAM)that focuses on fine-grained local feature correlation between two humans to adaptively aggregate consistent features for adaptation. We adopt ISA only in semi-supervised domain adaptation (SSDA) to exploit the corresponding keypoint semantic relationship for reducing the intra-domain bias. Most importantly, we propose an IHTA to learn more domain-invariant human topological representation for reducing the inter-domain discrepancy. We model the human topological structure via the graph convolution network (GCN), by passing messages on which, high-order relations can be considered. This structure preserving alignment based on GCN is beneficial to the occluded or extreme pose inference. Extensive experiments are conducted on two popular benchmarks and results demonstrate the competency of our method compared with existing supervised approaches.
Achieving Real-Time Execution of 3D Convolutional Neural Networks on Mobile Devices
Jul 20, 2020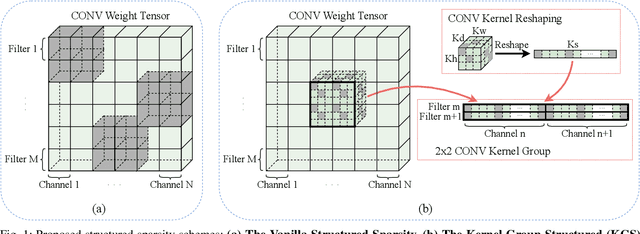
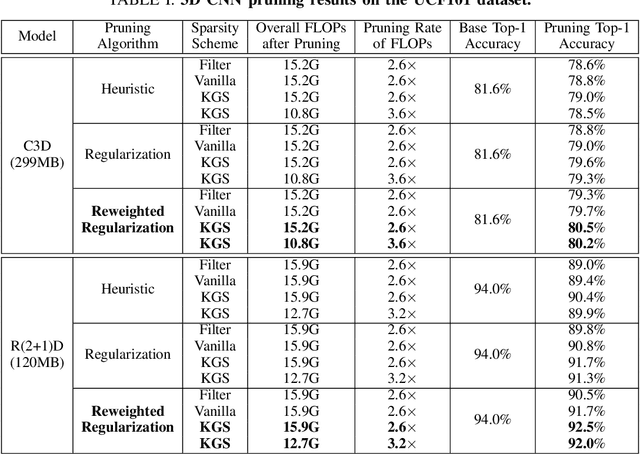
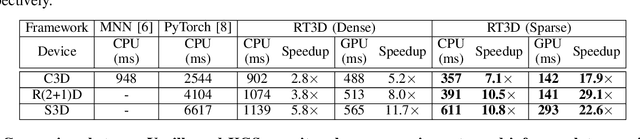

Mobile devices are becoming an important carrier for deep learning tasks, as they are being equipped with powerful, high-end mobile CPUs and GPUs. However, it is still a challenging task to execute 3D Convolutional Neural Networks (CNNs) targeting for real-time performance, besides high inference accuracy. The reason is more complex model structure and higher model dimensionality overwhelm the available computation/storage resources on mobile devices. A natural way may be turning to deep learning weight pruning techniques. However, the direct generalization of existing 2D CNN weight pruning methods to 3D CNNs is not ideal for fully exploiting mobile parallelism while achieving high inference accuracy. This paper proposes RT3D, a model compression and mobile acceleration framework for 3D CNNs, seamlessly integrating neural network weight pruning and compiler code generation techniques. We propose and investigate two structured sparsity schemes i.e., the vanilla structured sparsity and kernel group structured (KGS) sparsity that are mobile acceleration friendly. The vanilla sparsity removes whole kernel groups, while KGS sparsity is a more fine-grained structured sparsity that enjoys higher flexibility while exploiting full on-device parallelism. We propose a reweighted regularization pruning algorithm to achieve the proposed sparsity schemes. The inference time speedup due to sparsity is approaching the pruning rate of the whole model FLOPs (floating point operations). RT3D demonstrates up to 29.1$\times$ speedup in end-to-end inference time comparing with current mobile frameworks supporting 3D CNNs, with moderate 1%-1.5% accuracy loss. The end-to-end inference time for 16 video frames could be within 150 ms, when executing representative C3D and R(2+1)D models on a cellphone. For the first time, real-time execution of 3D CNNs is achieved on off-the-shelf mobiles.