 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePast- and Future-Informed KV Cache Policy with Salience Estimation in Autoregressive Video Diffusion
Jan 29, 2026Video generation is pivotal to digital media creation, and recent advances in autoregressive video generation have markedly enhanced the efficiency of real-time video synthesis. However, existing approaches generally rely on heuristic KV Cache policies, which ignore differences in token importance in long-term video generation. This leads to the loss of critical spatiotemporal information and the accumulation of redundant, invalid cache, thereby degrading video generation quality and efficiency. To address this limitation, we first observe that token contributions to video generation are highly time-heterogeneous and accordingly propose a novel Past- and Future-Informed KV Cache Policy (PaFu-KV). Specifically, PaFu-KV introduces a lightweight Salience Estimation Head distilled from a bidirectional teacher to estimate salience scores, allowing the KV cache to retain informative tokens while discarding less relevant ones. This policy yields a better quality-efficiency trade-off by shrinking KV cache capacity and reducing memory footprint at inference time. Extensive experiments on benchmarks demonstrate that our method preserves high-fidelity video generation quality while enables accelerated inference, thereby enabling more efficient long-horizon video generation. Our code will be released upon paper acceptance.
Beyond Global Alignment: Fine-Grained Motion-Language Retrieval via Pyramidal Shapley-Taylor Learning
Jan 29, 2026As a foundational task in human-centric cross-modal intelligence, motion-language retrieval aims to bridge the semantic gap between natural language and human motion, enabling intuitive motion analysis, yet existing approaches predominantly focus on aligning entire motion sequences with global textual representations. This global-centric paradigm overlooks fine-grained interactions between local motion segments and individual body joints and text tokens, inevitably leading to suboptimal retrieval performance. To address this limitation, we draw inspiration from the pyramidal process of human motion perception (from joint dynamics to segment coherence, and finally to holistic comprehension) and propose a novel Pyramidal Shapley-Taylor (PST) learning framework for fine-grained motion-language retrieval. Specifically, the framework decomposes human motion into temporal segments and spatial body joints, and learns cross-modal correspondences through progressive joint-wise and segment-wise alignment in a pyramidal fashion, effectively capturing both local semantic details and hierarchical structural relationships. Extensive experiments on multiple public benchmark datasets demonstrate that our approach significantly outperforms state-of-the-art methods, achieving precise alignment between motion segments and body joints and their corresponding text tokens. The code of this work will be released upon acceptance.
Flatter Tokens are More Valuable for Speculative Draft Model Training
Jan 26, 2026Speculative Decoding (SD) is a key technique for accelerating Large Language Model (LLM) inference, but it typically requires training a draft model on a large dataset. We approach this problem from a data-centric perspective, finding that not all training samples contribute equally to the SD acceptance rate. Specifically, our theoretical analysis and empirical validation reveals that tokens inducing flatter predictive distributions from the target model are more valuable than those yielding sharply peaked distributions. Based on this insight, we propose flatness, a new metric to quantify this property, and develop the Sample-level-flatness-based Dataset Distillation (SFDD) approach, which filters the training data to retain only the most valuable samples. Experiments on the EAGLE framework demonstrate that SFDD can achieve over 2$\times$ training speedup using only 50% of the data, while keeping the final model's inference speedup within 4% of the full-dataset baseline. This work introduces an effective, data-centric approach that substantially improves the training efficiency for Speculative Decoding. Our code is available at https://anonymous.4open.science/r/Flatness.
Revealing Perception and Generation Dynamics in LVLMs: Mitigating Hallucinations via Validated Dominance Correction
Dec 21, 2025Large Vision-Language Models (LVLMs) have shown remarkable capabilities, yet hallucinations remain a persistent challenge. This work presents a systematic analysis of the internal evolution of visual perception and token generation in LVLMs, revealing two key patterns. First, perception follows a three-stage GATE process: early layers perform a Global scan, intermediate layers Approach and Tighten on core content, and later layers Explore supplementary regions. Second, generation exhibits an SAD (Subdominant Accumulation to Dominant) pattern, where hallucinated tokens arise from the repeated accumulation of subdominant tokens lacking support from attention (visual perception) or feed-forward network (internal knowledge). Guided by these findings, we devise the VDC (Validated Dominance Correction) strategy, which detects unsupported tokens and replaces them with validated dominant ones to improve output reliability. Extensive experiments across multiple models and benchmarks confirm that VDC substantially mitigates hallucinations.
MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
Nov 18, 2025



Evaluating the robustness of Large Vision-Language Models (LVLMs) is essential for their continued development and responsible deployment in real-world applications. However, existing robustness benchmarks typically focus on hallucination or misleading textual inputs, while largely overlooking the equally critical challenge posed by misleading visual inputs in assessing visual understanding. To fill this important gap, we introduce MVI-Bench, the first comprehensive benchmark specially designed for evaluating how Misleading Visual Inputs undermine the robustness of LVLMs. Grounded in fundamental visual primitives, the design of MVI-Bench centers on three hierarchical levels of misleading visual inputs: Visual Concept, Visual Attribute, and Visual Relationship. Using this taxonomy, we curate six representative categories and compile 1,248 expertly annotated VQA instances. To facilitate fine-grained robustness evaluation, we further introduce MVI-Sensitivity, a novel metric that characterizes LVLM robustness at a granular level. Empirical results across 18 state-of-the-art LVLMs uncover pronounced vulnerabilities to misleading visual inputs, and our in-depth analyses on MVI-Bench provide actionable insights that can guide the development of more reliable and robust LVLMs. The benchmark and codebase can be accessed at https://github.com/chenyil6/MVI-Bench.
MSLoRA: Multi-Scale Low-Rank Adaptation via Attention Reweighting
Nov 16, 2025



We introduce MSLoRA, a backbone-agnostic, parameter-efficient adapter that reweights feature responses rather than re-tuning the underlying backbone. Existing low-rank adaptation methods are mostly confined to vision transformers (ViTs) and struggle to generalize across architectures. MSLoRA unifies adaptation for both convolutional neural networks (CNNs) and ViTs by combining a low-rank linear projection with a multi-scale nonlinear transformation that jointly modulates spatial and channel attention. The two components are fused through pointwise multiplication and a residual connection, yielding a lightweight module that shifts feature attention while keeping pretrained weights frozen. Extensive experiments demonstrate that MSLoRA consistently improves transfer performance on classification, detection, and segmentation tasks with roughly less than 5\% of backbone parameters. The design further enables stable optimization, fast convergence, and strong cross-architecture generalization. By reweighting rather than re-tuning, MSLoRA provides a simple and universal approach for efficient adaptation of frozen vision backbones.
One Request, Multiple Experts: LLM Orchestrates Domain Specific Models via Adaptive Task Routing
Nov 16, 2025With the integration of massive distributed energy resources and the widespread participation of novel market entities, the operation of active distribution networks (ADNs) is progressively evolving into a complex multi-scenario, multi-objective problem. Although expert engineers have developed numerous domain specific models (DSMs) to address distinct technical problems, mastering, integrating, and orchestrating these heterogeneous DSMs still entail considerable overhead for ADN operators. Therefore, an intelligent approach is urgently required to unify these DSMs and enable efficient coordination. To address this challenge, this paper proposes the ADN-Agent architecture, which leverages a general large language model (LLM) to coordinate multiple DSMs, enabling adaptive intent recognition, task decomposition, and DSM invocation. Within the ADN-Agent, we design a novel communication mechanism that provides a unified and flexible interface for diverse heterogeneous DSMs. Finally, for some language-intensive subtasks, we propose an automated training pipeline for fine-tuning small language models, thereby effectively enhancing the overall problem-solving capability of the system. Comprehensive comparisons and ablation experiments validate the efficacy of the proposed method and demonstrate that the ADN-Agent architecture outperforms existing LLM application paradigms.
Efficient and Effective In-context Demonstration Selection with Coreset
Nov 12, 2025In-context learning (ICL) has emerged as a powerful paradigm for Large Visual Language Models (LVLMs), enabling them to leverage a few examples directly from input contexts. However, the effectiveness of this approach is heavily reliant on the selection of demonstrations, a process that is NP-hard. Traditional strategies, including random, similarity-based sampling and infoscore-based sampling, often lead to inefficiencies or suboptimal performance, struggling to balance both efficiency and effectiveness in demonstration selection. In this paper, we propose a novel demonstration selection framework named Coreset-based Dual Retrieval (CoDR). We show that samples within a diverse subset achieve a higher expected mutual information. To implement this, we introduce a cluster-pruning method to construct a diverse coreset that aligns more effectively with the query while maintaining diversity. Additionally, we develop a dual retrieval mechanism that enhances the selection process by achieving global demonstration selection while preserving efficiency. Experimental results demonstrate that our method significantly improves the ICL performance compared to the existing strategies, providing a robust solution for effective and efficient demonstration selection.
CoT Vectors: Transferring and Probing the Reasoning Mechanisms of LLMs
Oct 01, 2025Chain-of-Thought (CoT) prompting has emerged as a powerful approach to enhancing the reasoning capabilities of Large Language Models (LLMs). However, existing implementations, such as in-context learning and fine-tuning, remain costly and inefficient. To improve CoT reasoning at a lower cost, and inspired by the task vector paradigm, we introduce CoT Vectors, compact representations that encode task-general, multi-step reasoning knowledge. Through experiments with Extracted CoT Vectors, we observe pronounced layer-wise instability, manifesting as a U-shaped performance curve that reflects a systematic three-stage reasoning process in LLMs. To address this limitation, we propose Learnable CoT Vectors, optimized under a teacher-student framework to provide more stable and robust guidance. Extensive evaluations across diverse benchmarks and models demonstrate that CoT Vectors not only outperform existing baselines but also achieve performance comparable to parameter-efficient fine-tuning methods, while requiring fewer trainable parameters. Moreover, by treating CoT Vectors as a probe, we uncover how their effectiveness varies due to latent space structure, information density, acquisition mechanisms, and pre-training differences, offering new insights into the functional organization of multi-step reasoning in LLMs. The source code will be released.
Towards Understanding Feature Learning in Parameter Transfer
Sep 26, 2025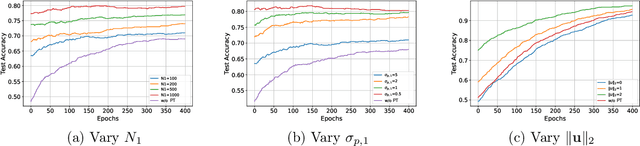
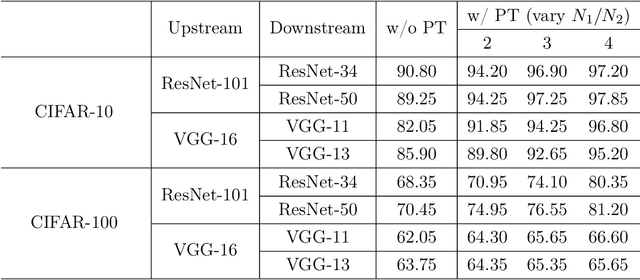
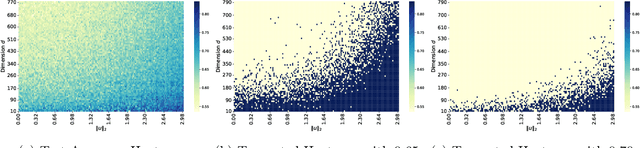
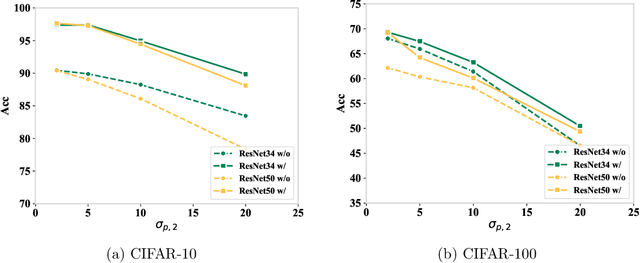
Parameter transfer is a central paradigm in transfer learning, enabling knowledge reuse across tasks and domains by sharing model parameters between upstream and downstream models. However, when only a subset of parameters from the upstream model is transferred to the downstream model, there remains a lack of theoretical understanding of the conditions under which such partial parameter reuse is beneficial and of the factors that govern its effectiveness. To address this gap, we analyze a setting in which both the upstream and downstream models are ReLU convolutional neural networks (CNNs). Within this theoretical framework, we characterize how the inherited parameters act as carriers of universal knowledge and identify key factors that amplify their beneficial impact on the target task. Furthermore, our analysis provides insight into why, in certain cases, transferring parameters can lead to lower test accuracy on the target task than training a new model from scratch. Numerical experiments and real-world data experiments are conducted to empirically validate our theoretical findings.