 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder
Apr 23, 2023



While recent research has made significant progress in speech-driven talking face generation, the quality of the generated video still lags behind that of real recordings. One reason for this is the use of handcrafted intermediate representations like facial landmarks and 3DMM coefficients, which are designed based on human knowledge and are insufficient to precisely describe facial movements. Additionally, these methods require an external pretrained model for extracting these representations, whose performance sets an upper bound on talking face generation. To address these limitations, we propose a novel method called DAE-Talker that leverages data-driven latent representations obtained from a diffusion autoencoder (DAE). DAE contains an image encoder that encodes an image into a latent vector and a DDIM image decoder that reconstructs the image from it. We train our DAE on talking face video frames and then extract their latent representations as the training target for a Conformer-based speech2latent model. This allows DAE-Talker to synthesize full video frames and produce natural head movements that align with the content of speech, rather than relying on a predetermined head pose from a template video. We also introduce pose modelling in speech2latent for pose controllability. Additionally, we propose a novel method for generating continuous video frames with the DDIM image decoder trained on individual frames, eliminating the need for modelling the joint distribution of consecutive frames directly. Our experiments show that DAE-Talker outperforms existing popular methods in lip-sync, video fidelity, and pose naturalness. We also conduct ablation studies to analyze the effectiveness of the proposed techniques and demonstrate the pose controllability of DAE-Talker.
AUDIT: Audio Editing by Following Instructions with Latent Diffusion Models
Apr 05, 2023Audio editing is applicable for various purposes, such as adding background sound effects, replacing a musical instrument, and repairing damaged audio. Recently, some diffusion-based methods achieved zero-shot audio editing by using a diffusion and denoising process conditioned on the text description of the output audio. However, these methods still have some problems: 1) they have not been trained on editing tasks and cannot ensure good editing effects; 2) they can erroneously modify audio segments that do not require editing; 3) they need a complete description of the output audio, which is not always available or necessary in practical scenarios. In this work, we propose AUDIT, an instruction-guided audio editing model based on latent diffusion models. Specifically, AUDIT has three main design features: 1) we construct triplet training data (instruction, input audio, output audio) for different audio editing tasks and train a diffusion model using instruction and input (to be edited) audio as conditions and generating output (edited) audio; 2) it can automatically learn to only modify segments that need to be edited by comparing the difference between the input and output audio; 3) it only needs edit instructions instead of full target audio descriptions as text input. AUDIT achieves state-of-the-art results in both objective and subjective metrics for several audio editing tasks (e.g., adding, dropping, replacement, inpainting, super-resolution). Demo samples are available at https://audit-demo.github.io/.
Improving Autoencoder-based Outlier Detection with Adjustable Probabilistic Reconstruction Error and Mean-shift Outlier Scoring
Apr 03, 2023
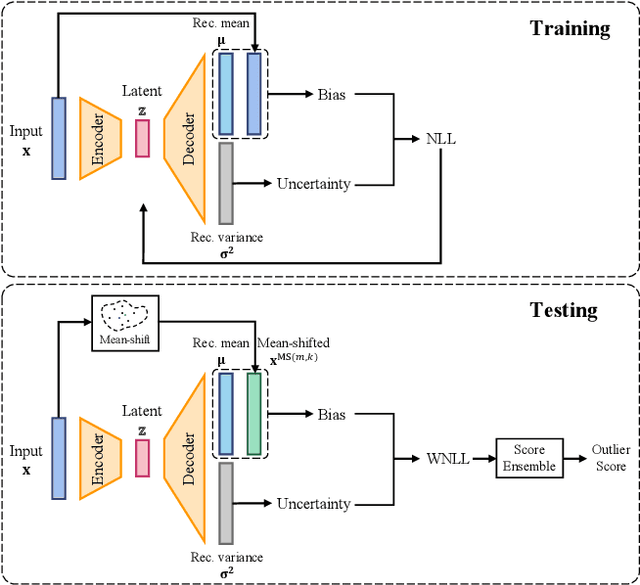
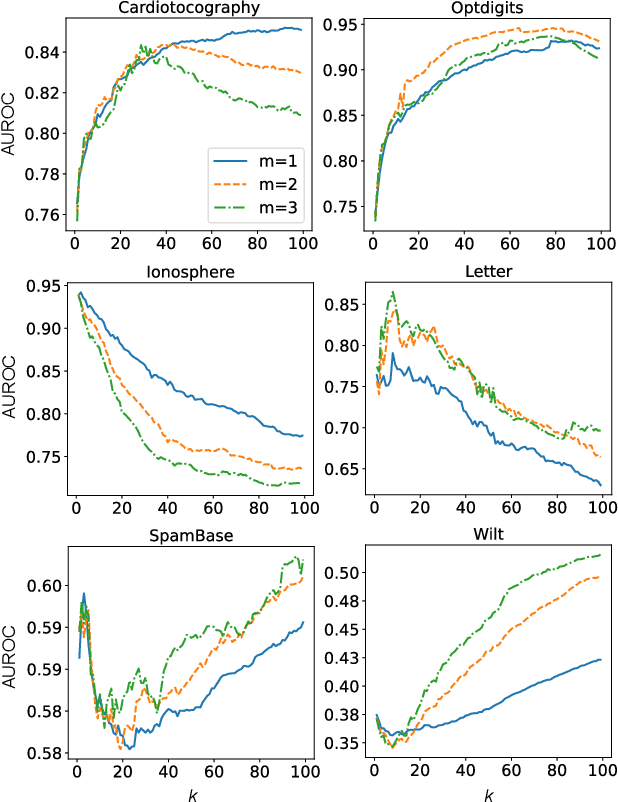
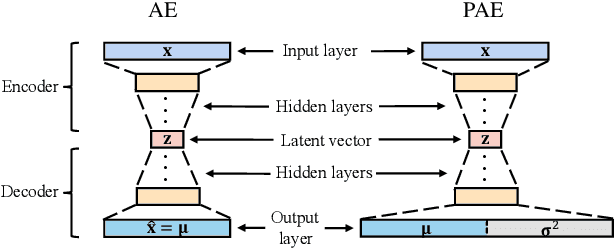
Autoencoders were widely used in many machine learning tasks thanks to their strong learning ability which has drawn great interest among researchers in the field of outlier detection. However, conventional autoencoder-based methods lacked considerations in two aspects. This limited their performance in outlier detection. First, the mean squared error used in conventional autoencoders ignored the judgment uncertainty of the autoencoder, which limited their representation ability. Second, autoencoders suffered from the abnormal reconstruction problem: some outliers can be unexpectedly reconstructed well, making them difficult to identify from the inliers. To mitigate the aforementioned issues, two novel methods were proposed in this paper. First, a novel loss function named Probabilistic Reconstruction Error (PRE) was constructed to factor in both reconstruction bias and judgment uncertainty. To further control the trade-off of these two factors, two weights were introduced in PRE producing Adjustable Probabilistic Reconstruction Error (APRE), which benefited the outlier detection in different applications. Second, a conceptually new outlier scoring method based on mean-shift (MSS) was proposed to reduce the false inliers caused by the autoencoder. Experiments on 32 real-world outlier detection datasets proved the effectiveness of the proposed methods. The combination of the proposed methods achieved 41% of the relative performance improvement compared to the best baseline. The MSS improved the performance of multiple autoencoder-based outlier detectors by an average of 20%. The proposed two methods have the potential to advance autoencoder's development in outlier detection. The code is available on www.OutlierNet.com for reproducibility.
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace
Apr 02, 2023Solving complicated AI tasks with different domains and modalities is a key step toward advanced artificial intelligence. While there are abundant AI models available for different domains and modalities, they cannot handle complicated AI tasks. Considering large language models (LLMs) have exhibited exceptional ability in language understanding, generation, interaction, and reasoning, we advocate that LLMs could act as a controller to manage existing AI models to solve complicated AI tasks and language could be a generic interface to empower this. Based on this philosophy, we present HuggingGPT, a framework that leverages LLMs (e.g., ChatGPT) to connect various AI models in machine learning communities (e.g., Hugging Face) to solve AI tasks. Specifically, we use ChatGPT to conduct task planning when receiving a user request, select models according to their function descriptions available in Hugging Face, execute each subtask with the selected AI model, and summarize the response according to the execution results. By leveraging the strong language capability of ChatGPT and abundant AI models in Hugging Face, HuggingGPT is able to cover numerous sophisticated AI tasks in different modalities and domains and achieve impressive results in language, vision, speech, and other challenging tasks, which paves a new way towards advanced artificial intelligence.
HiFace: High-Fidelity 3D Face Reconstruction by Learning Static and Dynamic Details
Mar 20, 20233D Morphable Models (3DMMs) demonstrate great potential for reconstructing faithful and animatable 3D facial surfaces from a single image. The facial surface is influenced by the coarse shape, as well as the static detail (e,g., person-specific appearance) and dynamic detail (e.g., expression-driven wrinkles). Previous work struggles to decouple the static and dynamic details through image-level supervision, leading to reconstructions that are not realistic. In this paper, we aim at high-fidelity 3D face reconstruction and propose HiFace to explicitly model the static and dynamic details. Specifically, the static detail is modeled as the linear combination of a displacement basis, while the dynamic detail is modeled as the linear interpolation of two displacement maps with polarized expressions. We exploit several loss functions to jointly learn the coarse shape and fine details with both synthetic and real-world datasets, which enable HiFace to reconstruct high-fidelity 3D shapes with animatable details. Extensive quantitative and qualitative experiments demonstrate that HiFace presents state-of-the-art reconstruction quality and faithfully recovers both the static and dynamic details. Our project page can be found at https://project-hiface.github.io
Improving Few-Shot Learning for Talking Face System with TTS Data Augmentation
Mar 09, 2023Audio-driven talking face has attracted broad interest from academia and industry recently. However, data acquisition and labeling in audio-driven talking face are labor-intensive and costly. The lack of data resource results in poor synthesis effect. To alleviate this issue, we propose to use TTS (Text-To-Speech) for data augmentation to improve few-shot ability of the talking face system. The misalignment problem brought by the TTS audio is solved with the introduction of soft-DTW, which is first adopted in the talking face task. Moreover, features extracted by HuBERT are explored to utilize underlying information of audio, and found to be superior over other features. The proposed method achieves 17%, 14%, 38% dominance on MSE score, DTW score and user study preference repectively over the baseline model, which shows the effectiveness of improving few-shot learning for talking face system with TTS augmentation.
FoundationTTS: Text-to-Speech for ASR Customization with Generative Language Model
Mar 08, 2023Neural text-to-speech (TTS) generally consists of cascaded architecture with separately optimized acoustic model and vocoder, or end-to-end architecture with continuous mel-spectrograms or self-extracted speech frames as the intermediate representations to bridge acoustic model and vocoder, which suffers from two limitations: 1) the continuous acoustic frames are hard to predict with phoneme only, and acoustic information like duration or pitch is also needed to solve the one-to-many problem, which is not easy to scale on large scale and noise datasets; 2) to achieve diverse speech output based on continuous speech features, complex VAE or flow-based models are usually required. In this paper, we propose FoundationTTS, a new speech synthesis system with a neural audio codec for discrete speech token extraction and waveform reconstruction and a large language model for discrete token generation from linguistic (phoneme) tokens. Specifically, 1) we propose a hierarchical codec network based on vector-quantized auto-encoders with adversarial training (VQ-GAN), which first extracts continuous frame-level speech representations with fine-grained codec, and extracts a discrete token from each continuous speech frame with coarse-grained codec; 2) we jointly optimize speech token, linguistic tokens, speaker token together with a large language model and predict the discrete speech tokens autoregressively. Experiments show that FoundationTTS achieves a MOS gain of +0.14 compared to the baseline system. In ASR customization tasks, our method achieves 7.09\% and 10.35\% WERR respectively over two strong customized ASR baselines.
A Study on ReLU and Softmax in Transformer
Feb 13, 2023The Transformer architecture consists of self-attention and feed-forward networks (FFNs) which can be viewed as key-value memories according to previous works. However, FFN and traditional memory utilize different activation functions (i.e., ReLU and Softmax respectively), which makes them not equivalent. In this paper, we first rebuild the connections between FFN and key-value memory by conducting extensive studies on ReLU and Softmax, and find they are equivalent when adding an additional layer normalization module on Softmax. In addition, ReLU outperforms Softmax on both FFN and key-value memory when the number of value slots is large. We analyze the reasons and then explore this good property of ReLU on the self-attention network where the original Softmax activation performs poorly on long input sequences. We then propose a full ReLU architecture named ReLUFormer which performs better than the baseline Transformer on long sequence tasks such as document translation. This paper sheds light on the following points: 1) Softmax and ReLU use different normalization methods over elements which lead to different variances of results, and ReLU is good at dealing with a large number of key-value slots; 2) FFN and key-value memory are equivalent, and thus the Transformer can be viewed as a memory network where FFNs and self-attention networks are both key-value memories.
N-Gram Nearest Neighbor Machine Translation
Feb 07, 2023Nearest neighbor machine translation augments the Autoregressive Translation~(AT) with $k$-nearest-neighbor retrieval, by comparing the similarity between the token-level context representations of the target tokens in the query and the datastore. However, the token-level representation may introduce noise when translating ambiguous words, or fail to provide accurate retrieval results when the representation generated by the model contains indistinguishable context information, e.g., Non-Autoregressive Translation~(NAT) models. In this paper, we propose a novel $n$-gram nearest neighbor retrieval method that is model agnostic and applicable to both AT and NAT models. Specifically, we concatenate the adjacent $n$-gram hidden representations as the key, while the tuple of corresponding target tokens is the value. In inference, we propose tailored decoding algorithms for AT and NAT models respectively. We demonstrate that the proposed method consistently outperforms the token-level method on both AT and NAT models as well on general as on domain adaptation translation tasks. On domain adaptation, the proposed method brings $1.03$ and $2.76$ improvements regarding the average BLEU score on AT and NAT models respectively.
ERA-Solver: Error-Robust Adams Solver for Fast Sampling of Diffusion Probabilistic Models
Feb 06, 2023



Though denoising diffusion probabilistic models (DDPMs) have achieved remarkable generation results, the low sampling efficiency of DDPMs still limits further applications. Since DDPMs can be formulated as diffusion ordinary differential equations (ODEs), various fast sampling methods can be derived from solving diffusion ODEs. However, we notice that previous sampling methods with fixed analytical form are not robust with the error in the noise estimated from pretrained diffusion models. In this work, we construct an error-robust Adams solver (ERA-Solver), which utilizes the implicit Adams numerical method that consists of a predictor and a corrector. Different from the traditional predictor based on explicit Adams methods, we leverage a Lagrange interpolation function as the predictor, which is further enhanced with an error-robust strategy to adaptively select the Lagrange bases with lower error in the estimated noise. Experiments on Cifar10, LSUN-Church, and LSUN-Bedroom datasets demonstrate that our proposed ERA-Solver achieves 5.14, 9.42, and 9.69 Fenchel Inception Distance (FID) for image generation, with only 10 network evaluations.