 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSO-Mamba: State-Ownership Mamba for Unrolled MRI Reconstruction
May 21, 2026Accelerated MRI reconstruction requires recovering missing details while preserving anatomically coherent structures across large spatial regions. State-space models such as Mamba provide efficient long-range modeling, making them attractive learned regularizers for unrolled reconstruction. However, in a data-consistency-coupled unrolled solver, different stages operate on different reconstruction iterates, where the resident carrier should preserve coherent reconstruction content across stages while stage-dependent non-resident evidence is tied to the current update. Treating these roles uniformly can place persistent resident-carrier evidence and update-dependent non-resident evidence into the same recurrent content route. We therefore propose SO-Mamba, a state-ownership Mamba regularizer that assigns reconstruction evidence within each Mamba stage to recurrent residency, state-interface access, and non-state output correction. SO-Mamba implements this ownership rule with a State-Ownership Router (SOR), which constructs a resident carrier for recurrent content and routes non-resident evidence to affine modulation of the B/C state interfaces and an output correction outlet. The resident carrier supplies the Mamba content route, while the non-resident evidence stream adapts the state interfaces and contributes through the output outlet without entering the recurrent content route. We further introduce a two-level outer-band leakage diagnostic that separates hidden-state storage from readout expression by measuring outer-band energy in the selective-scan state trajectory and the post-scan Mamba readout. Experiments on five public MRI reconstruction benchmarks spanning diverse anatomies, sampling patterns, and coil configurations show that SO-Mamba consistently improves over CNN-, Transformer-, and Mamba-based baselines with competitive computational efficiency.
CHASM: Cross-frequency Harmonized Axis-Separable Mixing for Spectral Token Operators
May 14, 2026Spectral token mixers based on Fourier transforms provide an efficient way to model global interactions in visual feature maps. Existing designs often either apply filter-wise spectral responses along fixed channel axes, or learn adaptive frequency-indexed channel mixing without explicitly aligning the channel directions used across frequencies. We propose CHASM, a Cross-frequency Harmonized Axis-Separable Mixer, as a structured middle ground. CHASM separates what should be shared from what should remain frequency-specific: all frequencies share a learned channel eigenbasis, while each frequency retains its own positive spectral gains. The shared basis makes channel directions comparable across the spectrum, whereas the positive gains preserve local spectral adaptivity. CHASM applies this structured operator separably along the height and width axes and is used as a drop-in replacement mixer inside existing backbones. We provide a structural characterization of the shared-basis operator family and evaluate CHASM through controlled same-backbone comparisons. Across accelerated MRI reconstruction, undersampled MRI segmentation, and natural-image reconstruction, CHASM consistently improves over same-backbone spectral-mixer baselines. Ablations show that removing the shared-basis constraint weakens performance, and randomizing coherent sampling geometry substantially reduces the gain, supporting cross-frequency harmonization as a useful inductive bias for spectral token operators.
UMo: Unified Sparse Motion Modeling for Real-Time Co-Speech Avatars
May 14, 2026Speech-driven gestures and facial animations are fundamental to expressive digital avatars in games, virtual production, and interactive media. However, existing methods are either limited to a single modality for audio motion alignment, failing to fully utilize the potential of massive human motion data, or are constrained by the representation ability and throughput of multimodal models, which makes it difficult to achieve high-quality motion generation or real-time performance. We present UMo, a unified sparse motion modeling architecture for real-time co-speech avatars, which processes text, audio, and motion tokens within a unified formulation. Leveraging a spatially sparse Mixture-of-Experts framework and a temporally sparse, keyframe-centric design, UMo efficiently performs real-time dense reconstruction, enabling temporally coherent and high-fidelity animation generation for both facial expressions and gestures. Furthermore, we implement a multi-stage training strategy with targeted audio augmentation to enhance acoustic diversity and semantic consistency. Consequently, UMo preserves fine-grained speech-motion alignment even under strict latency constraints. Extensive quantitative and qualitative evaluations show that UMo achieves better output quality under low latency and real-time performance constraints, offering a practical solution for high-fidelity real-time co-speech avatars.
AnchorRoute: Human Motion Synthesis with Interval-Routed Sparse Contro
May 14, 2026Sparse anchors provide a compact interface for human motion authoring: users specify a few root positions, planar trajectory samples, or body-point targets, while the system synthesizes the full-body motion that completes the under-specified intent. We present AnchorRoute, a sparse-anchor motion synthesis framework that uses anchors as a shared scaffold for both generation and refinement. Before generation, AnchorRoute converts sparse anchors into anchor-condition features and injects the resulting condition memory into a frozen Transition Masked Diffusion prior through AnchorKV and dual-context conditioning. This preserves the generation quality of the pretrained text-to-motion prior while learning sparse spatial control. After generation, the same anchors are evaluated as residuals: their timestamps define refinement intervals, and their residuals determine where correction should be concentrated. RouteSolver then refines the motion by projecting soft-token updates onto anchor-defined piecewise-affine interval bases. This couples generation-time anchor conditioning with residual-routed refinement under one anchor scaffold. AnchorRoute supports root-3D, planar-root, and body-point control within the same formulation. In benchmark evaluations, AnchorRoute outperforms prior sparse-control methods under the sparse keyjoint protocol and consistently improves anchor adherence across control families. The results show that the learned anchor-conditioned generator and RouteSolver refinement are complementary: the generator preserves text-motion quality, while RouteSolver provides a controllable path toward stronger anchor adherence.
Dual-Pathway Circuits of Object Hallucination in Vision-Language Models
May 13, 2026Vision-language models (VLMs) have demonstrated remarkable capabilities in bridging visual perception and natural language understanding, enabling a wide range of multimodal reasoning tasks. However, they often produce object hallucinations, describing content absent from the input image, which limits their reliability and interpretability. To address this limitation, we propose Dual-Pathway Circuit Analysis, a framework that identifies and characterizes hallucination-related circuits in VLMs for mechanistic understanding and causal probing. We first apply activation patching across five architecturally diverse VLMs to identify a visual grounding pathway that supports correct predictions and a hallucination pathway that drives erroneous outputs. We then introduce Conditional Pathway Analysis (CPA) to characterize pathway-level interactions, revealing that grounding components remain strongly redundant in both correct and hallucinating samples but undergo a consistent polarity flip, shifting from supporting the ground truth on correct samples to aligning with the hallucinated answer on erroneous ones. We further perform targeted suppression of hallucination-pathway components, showing that scaling these components reduces object hallucination by up to 76% with minimal accuracy cost, and validate that the same circuit selectively transfers to relational but not attribute hallucination. Evaluations on POPE-adversarial and AMBER show that the identified circuits are consistent across architectures, support causal intervention, and transfer selectively across hallucination types.
Privileged Foresight Distillation: Zero-Cost Future Correction for World Action Models
Apr 28, 2026World action models jointly predict future video and action during training, raising an open question about what role the future-prediction branch actually plays. A recent finding shows that this branch can be removed at inference with little to no loss on common manipulation benchmarks, suggesting that future information may act merely as a regularizer on the shared visual backbone. We propose instead that joint training induces an action-conditioned correction that privileged future observations impose on action denoising, and that current-only policies capture this correction only partially. Making the account precise, we formulate privileged foresight as a residual in the action-denoising direction -- the difference between what a model predicts given the true future and what it predicts given only the current frame -- and introduce \emph{Privileged Foresight Distillation (PFD)}, which transfers this residual from a training-time teacher into a small adapter on a current-only student. The teacher and student share the same backbone and differ only in the attention mask over video tokens; future video is never generated at inference. Controlled experiments verify that this gain reflects a genuine future-conditioned correction rather than a side effect of capacity or regularization. Empirically, PFD achieves consistent improvements on LIBERO and RoboTwin manipulation benchmarks while preserving the current-only inference interface at negligible added latency. This view reframes the role of future information in world action models: not as a target to predict, nor as a regularizer to absorb, but as a compressible correction to be distilled.
GRASPTrack: Geometry-Reasoned Association via Segmentation and Projection for Multi-Object Tracking
Aug 11, 2025Multi-object tracking (MOT) in monocular videos is fundamentally challenged by occlusions and depth ambiguity, issues that conventional tracking-by-detection (TBD) methods struggle to resolve owing to a lack of geometric awareness. To address these limitations, we introduce GRASPTrack, a novel depth-aware MOT framework that integrates monocular depth estimation and instance segmentation into a standard TBD pipeline to generate high-fidelity 3D point clouds from 2D detections, thereby enabling explicit 3D geometric reasoning. These 3D point clouds are then voxelized to enable a precise and robust Voxel-Based 3D Intersection-over-Union (IoU) for spatial association. To further enhance tracking robustness, our approach incorporates Depth-aware Adaptive Noise Compensation, which dynamically adjusts the Kalman filter process noise based on occlusion severity for more reliable state estimation. Additionally, we propose a Depth-enhanced Observation-Centric Momentum, which extends the motion direction consistency from the image plane into 3D space to improve motion-based association cues, particularly for objects with complex trajectories. Extensive experiments on the MOT17, MOT20, and DanceTrack benchmarks demonstrate that our method achieves competitive performance, significantly improving tracking robustness in complex scenes with frequent occlusions and intricate motion patterns.
MOGO: Residual Quantized Hierarchical Causal Transformer for High-Quality and Real-Time 3D Human Motion Generation
Jun 06, 2025Recent advances in transformer-based text-to-motion generation have led to impressive progress in synthesizing high-quality human motion. Nevertheless, jointly achieving high fidelity, streaming capability, real-time responsiveness, and scalability remains a fundamental challenge. In this paper, we propose MOGO (Motion Generation with One-pass), a novel autoregressive framework tailored for efficient and real-time 3D motion generation. MOGO comprises two key components: (1) MoSA-VQ, a motion scale-adaptive residual vector quantization module that hierarchically discretizes motion sequences with learnable scaling to produce compact yet expressive representations; and (2) RQHC-Transformer, a residual quantized hierarchical causal transformer that generates multi-layer motion tokens in a single forward pass, significantly reducing inference latency. To enhance semantic fidelity, we further introduce a text condition alignment mechanism that improves motion decoding under textual control. Extensive experiments on benchmark datasets including HumanML3D, KIT-ML, and CMP demonstrate that MOGO achieves competitive or superior generation quality compared to state-of-the-art transformer-based methods, while offering substantial improvements in real-time performance, streaming generation, and generalization under zero-shot settings.
Hi-ResNet: A High-Resolution Remote Sensing Network for Semantic Segmentation
May 23, 2023



High-resolution remote sensing (HRS) semantic segmentation extracts key objects from high-resolution coverage areas. However, objects of the same category within HRS images generally show significant differences in scale and shape across diverse geographical environments, making it difficult to fit the data distribution. Additionally, a complex background environment causes similar appearances of objects of different categories, which precipitates a substantial number of objects into misclassification as background. These issues make existing learning algorithms sub-optimal. In this work, we solve the above-mentioned problems by proposing a High-resolution remote sensing network (Hi-ResNet) with efficient network structure designs, which consists of a funnel module, a multi-branch module with stacks of information aggregation (IA) blocks, and a feature refinement module, sequentially, and Class-agnostic Edge Aware (CEA) loss. Specifically, we propose a funnel module to downsample, which reduces the computational cost, and extract high-resolution semantic information from the initial input image. Secondly, we downsample the processed feature images into multi-resolution branches incrementally to capture image features at different scales and apply IA blocks, which capture key latent information by leveraging attention mechanisms, for effective feature aggregation, distinguishing image features of the same class with variant scales and shapes. Finally, our feature refinement module integrate the CEA loss function, which disambiguates inter-class objects with similar shapes and increases the data distribution distance for correct predictions. With effective pre-training strategies, we demonstrated the superiority of Hi-ResNet over state-of-the-art methods on three HRS segmentation benchmarks.
MFR 2021: Masked Face Recognition Competition
Jun 29, 2021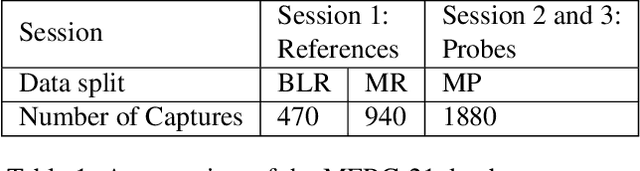

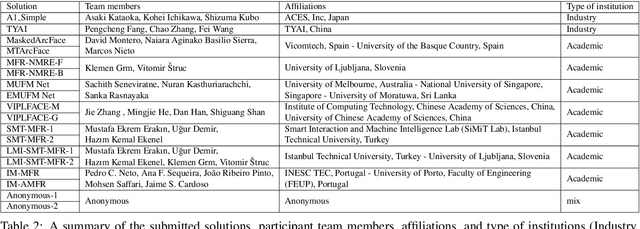
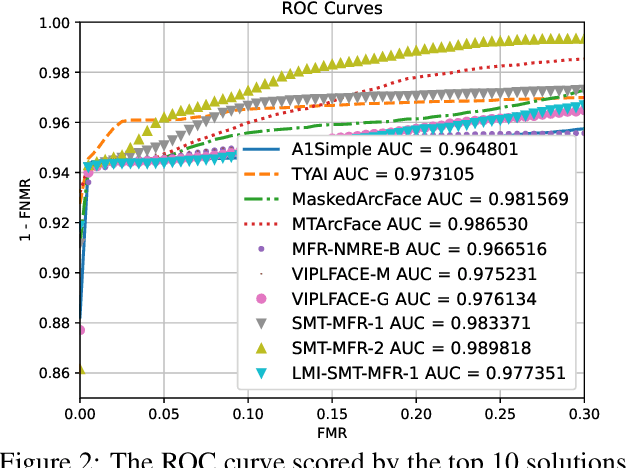
This paper presents a summary of the Masked Face Recognition Competitions (MFR) held within the 2021 International Joint Conference on Biometrics (IJCB 2021). The competition attracted a total of 10 participating teams with valid submissions. The affiliations of these teams are diverse and associated with academia and industry in nine different countries. These teams successfully submitted 18 valid solutions. The competition is designed to motivate solutions aiming at enhancing the face recognition accuracy of masked faces. Moreover, the competition considered the deployability of the proposed solutions by taking the compactness of the face recognition models into account. A private dataset representing a collaborative, multi-session, real masked, capture scenario is used to evaluate the submitted solutions. In comparison to one of the top-performing academic face recognition solutions, 10 out of the 18 submitted solutions did score higher masked face verification accuracy.