 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Light-Weight Facial Affective Behavior Recognition with CLIP
Mar 14, 2024Human affective behavior analysis aims to delve into human expressions and behaviors to deepen our understanding of human emotions. Basic expression categories (EXPR) and Action Units (AUs) are two essential components in this analysis, which categorize emotions and break down facial movements into elemental units, respectively. Despite advancements, existing approaches in expression classification and AU detection often necessitate complex models and substantial computational resources, limiting their applicability in everyday settings. In this work, we introduce the first lightweight framework adept at efficiently tackling both expression classification and AU detection. This framework employs a frozen CLIP image encoder alongside a trainable multilayer perceptron (MLP), enhanced with Conditional Value at Risk (CVaR) for robustness and a loss landscape flattening strategy for improved generalization. Experimental results on the Aff-wild2 dataset demonstrate superior performance in comparison to the baseline while maintaining minimal computational demands, offering a practical solution for affective behavior analysis. The code is available at https://github.com/Purdue-M2/Affective_Behavior_Analysis_M2_PURDUE
Electrocardiogram Instruction Tuning for Report Generation
Mar 13, 2024



Electrocardiogram (ECG) serves as the primary non-invasive diagnostic tool for cardiac conditions monitoring, are crucial in assisting clinicians. Recent studies have concentrated on classifying cardiac conditions using ECG data but have overlooked ECG report generation, which is not only time-consuming but also requires clinical expertise. To automate ECG report generation and ensure its versatility, we propose the Multimodal ECG Instruction Tuning (MEIT) framework, the \textit{first} attempt to tackle ECG report generation with LLMs and multimodal instructions. To facilitate future research, we establish a benchmark to evaluate MEIT with various LLMs backbones across two large-scale ECG datasets. Our approach uniquely aligns the representations of the ECG signal and the report, and we conduct extensive experiments to benchmark MEIT with nine open source LLMs, using more than 800,000 ECG reports. MEIT's results underscore the superior performance of instruction-tuned LLMs, showcasing their proficiency in quality report generation, zero-shot capabilities, and resilience to signal perturbation. These findings emphasize the efficacy of our MEIT framework and its potential for real-world clinical application.
Optimizing Latent Graph Representations of Surgical Scenes for Zero-Shot Domain Transfer
Mar 11, 2024
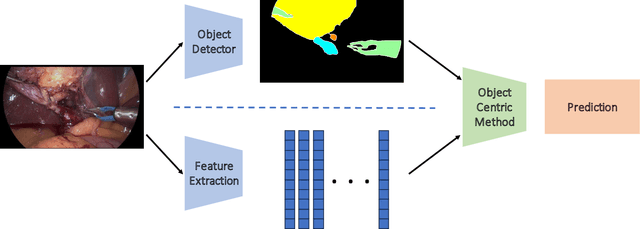

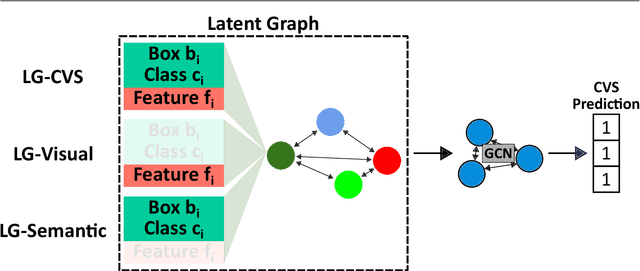
Purpose: Advances in deep learning have resulted in effective models for surgical video analysis; however, these models often fail to generalize across medical centers due to domain shift caused by variations in surgical workflow, camera setups, and patient demographics. Recently, object-centric learning has emerged as a promising approach for improved surgical scene understanding, capturing and disentangling visual and semantic properties of surgical tools and anatomy to improve downstream task performance. In this work, we conduct a multi-centric performance benchmark of object-centric approaches, focusing on Critical View of Safety assessment in laparoscopic cholecystectomy, then propose an improved approach for unseen domain generalization. Methods: We evaluate four object-centric approaches for domain generalization, establishing baseline performance. Next, leveraging the disentangled nature of object-centric representations, we dissect one of these methods through a series of ablations (e.g. ignoring either visual or semantic features for downstream classification). Finally, based on the results of these ablations, we develop an optimized method specifically tailored for domain generalization, LG-DG, that includes a novel disentanglement loss function. Results: Our optimized approach, LG-DG, achieves an improvement of 9.28% over the best baseline approach. More broadly, we show that object-centric approaches are highly effective for domain generalization thanks to their modular approach to representation learning. Conclusion: We investigate the use of object-centric methods for unseen domain generalization, identify method-agnostic factors critical for performance, and present an optimized approach that substantially outperforms existing methods.
UAV-Enabled Asynchronous Federated Learning
Mar 11, 2024To exploit unprecedented data generation in mobile edge networks, federated learning (FL) has emerged as a promising alternative to the conventional centralized machine learning (ML). However, there are some critical challenges for FL deployment. One major challenge called straggler issue severely limits FL's coverage where the device with the weakest channel condition becomes the bottleneck of the model aggregation performance. Besides, the huge uplink communication overhead compromises the effectiveness of FL, which is particularly pronounced in large-scale systems. To address the straggler issue, we propose the integration of an unmanned aerial vehicle (UAV) as the parameter server (UAV-PS) to coordinate the FL implementation. We further employ over-the-air computation technique that leverages the superposition property of wireless channels for efficient uplink communication. Specifically, in this paper, we develop a novel UAV-enabled over-the-air asynchronous FL (UAV-AFL) framework which supports the UAV-PS in updating the model continuously to enhance the learning performance. Moreover, we conduct a convergence analysis to quantitatively capture the impact of model asynchrony, device selection and communication errors on the UAV-AFL learning performance. Based on this, a unified communication-learning problem is formulated to maximize asymptotical learning performance by optimizing the UAV-PS trajectory, device selection and over-the-air transceiver design. Simulation results demonstrate that the proposed scheme achieves substantially learning efficiency improvement compared with the state-of-the-art approaches.
Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts
Mar 08, 2024Dynamic graph neural networks (DyGNNs) currently struggle with handling distribution shifts that are inherent in dynamic graphs. Existing work on DyGNNs with out-of-distribution settings only focuses on the time domain, failing to handle cases involving distribution shifts in the spectral domain. In this paper, we discover that there exist cases with distribution shifts unobservable in the time domain while observable in the spectral domain, and propose to study distribution shifts on dynamic graphs in the spectral domain for the first time. However, this investigation poses two key challenges: i) it is non-trivial to capture different graph patterns that are driven by various frequency components entangled in the spectral domain; and ii) it remains unclear how to handle distribution shifts with the discovered spectral patterns. To address these challenges, we propose Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts (SILD), which can handle distribution shifts on dynamic graphs by capturing and utilizing invariant and variant spectral patterns. Specifically, we first design a DyGNN with Fourier transform to obtain the ego-graph trajectory spectrums, allowing the mixed dynamic graph patterns to be transformed into separate frequency components. We then develop a disentangled spectrum mask to filter graph dynamics from various frequency components and discover the invariant and variant spectral patterns. Finally, we propose invariant spectral filtering, which encourages the model to rely on invariant patterns for generalization under distribution shifts. Experimental results on synthetic and real-world dynamic graph datasets demonstrate the superiority of our method for both node classification and link prediction tasks under distribution shifts.
Unsupervised Graph Neural Architecture Search with Disentangled Self-supervision
Mar 08, 2024



The existing graph neural architecture search (GNAS) methods heavily rely on supervised labels during the search process, failing to handle ubiquitous scenarios where supervisions are not available. In this paper, we study the problem of unsupervised graph neural architecture search, which remains unexplored in the literature. The key problem is to discover the latent graph factors that drive the formation of graph data as well as the underlying relations between the factors and the optimal neural architectures. Handling this problem is challenging given that the latent graph factors together with architectures are highly entangled due to the nature of the graph and the complexity of the neural architecture search process. To address the challenge, we propose a novel Disentangled Self-supervised Graph Neural Architecture Search (DSGAS) model, which is able to discover the optimal architectures capturing various latent graph factors in a self-supervised fashion based on unlabeled graph data. Specifically, we first design a disentangled graph super-network capable of incorporating multiple architectures with factor-wise disentanglement, which are optimized simultaneously. Then, we estimate the performance of architectures under different factors by our proposed self-supervised training with joint architecture-graph disentanglement. Finally, we propose a contrastive search with architecture augmentations to discover architectures with factor-specific expertise. Extensive experiments on 11 real-world datasets demonstrate that the proposed model is able to achieve state-of-the-art performance against several baseline methods in an unsupervised manner.
Parameterized quantum comb and simpler circuits for reversing unknown qubit-unitary operations
Mar 06, 2024



Quantum comb is an essential tool for characterizing complex quantum protocols in quantum information processing. In this work, we introduce PQComb, a framework leveraging parameterized quantum circuits to explore the capabilities of quantum combs for general quantum process transformation tasks and beyond. By optimizing PQComb for time-reversal simulations of unknown unitary evolutions, we develop a simpler protocol for unknown qubit unitary inversion that reduces the ancilla qubit overhead from 6 to 3 compared to the existing method in [Yoshida, Soeda, Murao, PRL 131, 120602, 2023]. This demonstrates the utility of quantum comb structures and showcases PQComb's potential for solving complex quantum tasks. Our results pave the way for broader PQComb applications in quantum computing and quantum information, emphasizing its versatility for tackling diverse problems in quantum machine learning.
Neural Radiance Fields in Medical Imaging: Challenges and Next Steps
Mar 02, 2024Neural Radiance Fields (NeRF), as a pioneering technique in computer vision, offer great potential to revolutionize medical imaging by synthesizing three-dimensional representations from the projected two-dimensional image data. However, they face unique challenges when applied to medical applications. This paper presents a comprehensive examination of applications of NeRFs in medical imaging, highlighting four imminent challenges, including fundamental imaging principles, inner structure requirement, object boundary definition, and color density significance. We discuss current methods on different organs and discuss related limitations. We also review several datasets and evaluation metrics and propose several promising directions for future research.
Preserving Fairness Generalization in Deepfake Detection
Feb 27, 2024



Although effective deepfake detection models have been developed in recent years, recent studies have revealed that these models can result in unfair performance disparities among demographic groups, such as race and gender. This can lead to particular groups facing unfair targeting or exclusion from detection, potentially allowing misclassified deepfakes to manipulate public opinion and undermine trust in the model. The existing method for addressing this problem is providing a fair loss function. It shows good fairness performance for intra-domain evaluation but does not maintain fairness for cross-domain testing. This highlights the significance of fairness generalization in the fight against deepfakes. In this work, we propose the first method to address the fairness generalization problem in deepfake detection by simultaneously considering features, loss, and optimization aspects. Our method employs disentanglement learning to extract demographic and domain-agnostic forgery features, fusing them to encourage fair learning across a flattened loss landscape. Extensive experiments on prominent deepfake datasets demonstrate our method's effectiveness, surpassing state-of-the-art approaches in preserving fairness during cross-domain deepfake detection. The code is available at https://github.com/Purdue-M2/Fairness-Generalization
Two-stage Cytopathological Image Synthesis for Augmenting Cervical Abnormality Screening
Feb 25, 2024



Automatic thin-prep cytologic test (TCT) screening can assist pathologists in finding cervical abnormality towards accurate and efficient cervical cancer diagnosis. Current automatic TCT screening systems mostly involve abnormal cervical cell detection, which generally requires large-scale and diverse training data with high-quality annotations to achieve promising performance. Pathological image synthesis is naturally raised to minimize the efforts in data collection and annotation. However, it is challenging to generate realistic large-size cytopathological images while simultaneously synthesizing visually plausible appearances for small-size abnormal cervical cells. In this paper, we propose a two-stage image synthesis framework to create synthetic data for augmenting cervical abnormality screening. In the first Global Image Generation stage, a Normal Image Generator is designed to generate cytopathological images full of normal cervical cells. In the second Local Cell Editing stage, normal cells are randomly selected from the generated images and then are converted to different types of abnormal cells using the proposed Abnormal Cell Synthesizer. Both Normal Image Generator and Abnormal Cell Synthesizer are built upon Stable Diffusion, a pre-trained foundation model for image synthesis, via parameter-efficient fine-tuning methods for customizing cytopathological image contents and extending spatial layout controllability, respectively. Our experiments demonstrate the synthetic image quality, diversity, and controllability of the proposed synthesis framework, and validate its data augmentation effectiveness in enhancing the performance of abnormal cervical cell detection.