 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViroBench: Benchmarking Nucleotide Foundation Models on Viral Genomics Tasks
May 25, 2026Nucleotide sequences constitute the fundamental genetic basis of biological systems, rendering viral genomic analysis critical for biomedical advancement. Despite progress in biological foundation models, specifically nucleotide foundation models (NFMs), the field lacks a unified standard for viral genomics to facilitate community development and enforce biosecurity constraints. To address this, we introduce ViroBench, the first comprehensive and large-scale benchmark specifically designed for NFMs in viral settings. ViroBench evaluates models across two critical dimensions: biological understanding and latent biosecurity risk, covering 18 diverse scenarios within 4 task types. Extensive evaluation of 66 NFMs across diverse architectures yields three critical conclusions. Firstly, NFMs exhibit a performance degradation in biological understanding under phylogenetic and temporal shifts, indicating weak extrapolation capabilities. Secondly, generation tasks reveal a decoupling between statistical likelihood and biological functional validity, posing latent biosecurity risks. Thirdly, controlled ablation studies reveal that taxonomic diversity in pretraining data outweighs parameter scale. Specifically, a lightweight baseline trained on diverse data achieves a 67.5% performance gain over its original model. Overall, ViroBench provides interpretable, diagnostic evaluations and a reproducible measurement framework for future research on viral nucleotide foundation models. The datasets and code are publicly available at https://github.com/QIANJINYDX/ViroBench.
S1-VL: Scientific Multimodal Reasoning Model with Thinking-with-Images
Apr 23, 2026We present S1-VL, a multimodal reasoning model for scientific domains that natively supports two complementary reasoning paradigms: Scientific Reasoning, which relies on structured chain-of-thought, and Thinking-with-Images, which enables the model to actively manipulate images through Python code execution during reasoning. In the Thinking-with-Images mode, the model generates and executes image-processing code in a sandbox environment, obtains intermediate visual results, and continues reasoning in a multi-turn iterative manner. This design is particularly effective for challenging scenarios such as high-resolution scientific chart interpretation, microscopic image understanding, and geometry-assisted reasoning. To construct the training data, we collect scientific multimodal datasets spanning six disciplines: mathematics, physics, chemistry, astronomy, geography, and biology. We further develop a six-dimensional quality filtering framework for reasoning trajectories. To mitigate redundant, ineffective, and erroneous visual operations commonly found in existing datasets, we propose a multi-stage filtering pipeline together with an adaptive data routing strategy. This strategy converts samples with low visual information gain into pure Reasoning-mode data, enabling the model to learn when image operations are truly necessary. S1-VL is trained through a four-stage progressive pipeline: scientific multimodal SFT, Thinking-with-Images cold-start SFT, and two stages of reinforcement learning with SAPO. We build S1-VL-32B on top of Qwen3-VL-32B-Thinking and evaluate it on 13 benchmarks. Experimental results show that S1-VL-32B achieves state-of-the-art performance on all five Thinking-with-Images benchmarks, including HRBench-4K, HRBench-8K, MME-RealWorld-CN, MME-RealWorld-Lite, and V*, and outperforms compared systems on scientific reasoning benchmarks such as Physics and VRSBench.
Weight Group-wise Post-Training Quantization for Medical Foundation Model
Apr 09, 2026Foundation models have achieved remarkable results in medical image analysis. However, its large network architecture and high computational complexity significantly impact inference speed, limiting its application on terminal medical devices. Quantization, a technique that compresses models into low-bit versions, is a solution to this challenge. In this paper, we propose a post-training quantization algorithm, Permutation-COMQ. It eliminates the need for backpropagation by using simple dot products and rounding operations, thereby removing hyperparameter tuning and simplifying the process. Additionally, we introduce a weight-aware strategy that reorders the weight within each layer to address the accuracy degradation induced by channel-wise scaling during quantization, while preserving channel structure. Experiments demonstrate that our method achieves the best results in 2-bit, 4-bit, and 8-bit quantization.
Robust Fair Disease Diagnosis in CT Images
Apr 08, 2026Automated diagnosis from chest CT has improved considerably with deep learning, but models trained on skewed datasets tend to perform unevenly across patient demographics. However, the situation is worse than simple demographic bias. In clinical data, class imbalance and group underrepresentation often coincide, creating compound failure modes that neither standard rebalancing nor fairness corrections can fix alone. We introduce a two-level objective that targets both axes of this problem. Logit-adjusted cross-entropy loss operates at the sample level, shifting decision margins by class frequency with provable consistency guarantees. Conditional Value at Risk aggregation operates at the group level, directing optimization pressure toward whichever demographic group currently has the higher loss. We evaluate on the Fair Disease Diagnosis benchmark using a 3D ResNet-18 pretrained on Kinetics-400, classifying CT volumes into Adenocarcinoma, Squamous Cell Carcinoma, COVID-19, and Normal groups with patient sex annotations. The training set illustrates the compound problem concretely: squamous cell carcinoma has 84 samples total, 5 of them female. The combined loss reaches a gender-averaged macro F1 of 0.8403 with a fairness gap of 0.0239, a 13.3% improvement in score and 78% reduction in demographic disparity over the baseline. Ablations show that each component alone falls short. The code is publicly available at https://github.com/Purdue-M2/Fair-Disease-Diagnosis.
Evidence-Based Actor-Verifier Reasoning for Echocardiographic Agents
Apr 07, 2026Echocardiography plays an important role in the screening and diagnosis of cardiovascular diseases. However, automated intelligent analysis of echocardiographic data remains challenging due to complex cardiac dynamics and strong view heterogeneity. In recent years, visual language models (VLM) have opened a new avenue for building ultrasound understanding systems for clinical decision support. Nevertheless, most existing methods formulate this task as a direct mapping from video and question to answer, making them vulnerable to template shortcuts and spurious explanations. To address these issues, we propose EchoTrust, an evidence-driven Actor-Verifier framework for trustworthy reasoning in echocardiography VLM-based agents. EchoTrust produces a structured intermediate representation that is subsequently analyzed by distinct roles, enabling more reliable and interpretable decision-making for high-stakes clinical applications.
Robust Multi-Source Covid-19 Detection in CT Images
Apr 02, 2026Deep learning models for COVID-19 detection from chest CT scans generally perform well when the training and test data originate from the same institution, but they often struggle when scans are drawn from multiple centres with differing scanners, imaging protocols, and patient populations. One key reason is that existing methods treat COVID-19 classification as the sole training objective, without accounting for the data source of each scan. As a result, the learned representations tend to be biased toward centres that contribute more training data. To address this, we propose a multi-task learning approach in which the model is trained to predict both the COVID-19 diagnosis and the originating data centre. The two tasks share an EfficientNet-B7 backbone, which encourages the feature extractor to learn representations that hold across all four participating centres. Since the training data is not evenly distributed across sources, we apply a logit-adjusted cross-entropy loss [1] to the source classification head to prevent underrepresented centres from being overlooked. Our pre-processing follows the SSFL framework with KDS [2], selecting eight representative slices per scan. Our method achieves an F1 score of 0.9098 and an AUC-ROC of 0.9647 on a validation set of 308 scans. The code is publicly available at https://github.com/Purdue-M2/-multisource-covid-ct.
Fairness-Aware Deepfake Detection: Leveraging Dual-Mechanism Optimization
Nov 19, 2025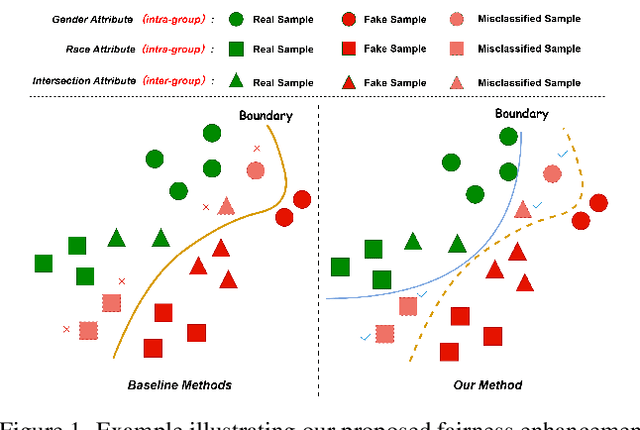
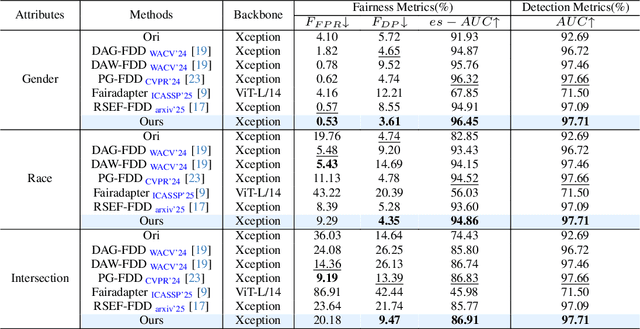
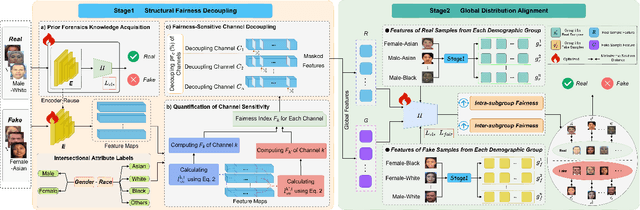
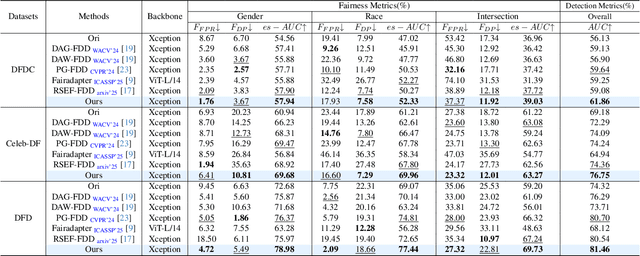
Fairness is a core element in the trustworthy deployment of deepfake detection models, especially in the field of digital identity security. Biases in detection models toward different demographic groups, such as gender and race, may lead to systemic misjudgments, exacerbating the digital divide and social inequities. However, current fairness-enhanced detectors often improve fairness at the cost of detection accuracy. To address this challenge, we propose a dual-mechanism collaborative optimization framework. Our proposed method innovatively integrates structural fairness decoupling and global distribution alignment: decoupling channels sensitive to demographic groups at the model architectural level, and subsequently reducing the distance between the overall sample distribution and the distributions corresponding to each demographic group at the feature level. Experimental results demonstrate that, compared with other methods, our framework improves both inter-group and intra-group fairness while maintaining overall detection accuracy across domains.
SynthGuard: An Open Platform for Detecting AI-Generated Multimedia with Multimodal LLMs
Nov 16, 2025
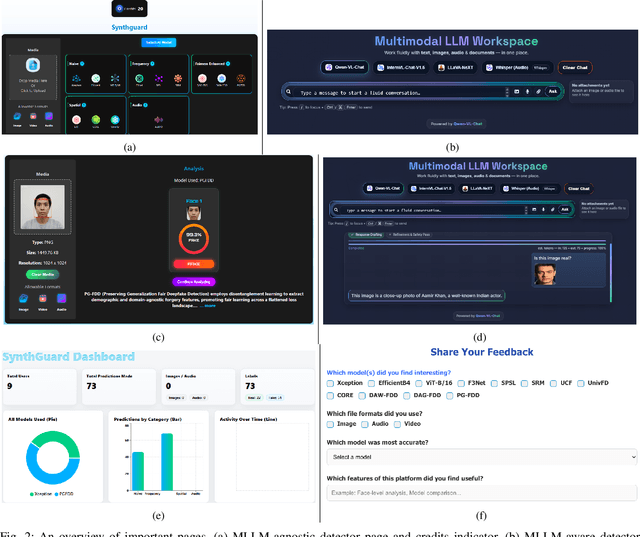
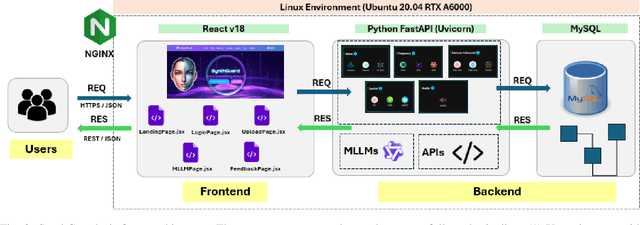
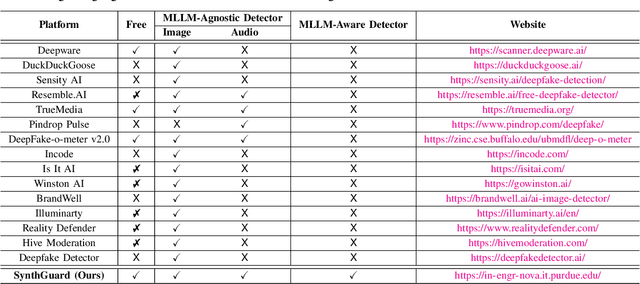
Artificial Intelligence (AI) has made it possible for anyone to create images, audio, and video with unprecedented ease, enriching education, communication, and creative expression. At the same time, the rapid rise of AI-generated media has introduced serious risks, including misinformation, identity misuse, and the erosion of public trust as synthetic content becomes increasingly indistinguishable from real media. Although deepfake detection has advanced, many existing tools remain closed-source, limited in modality, or lacking transparency and educational value, making it difficult for users to understand how detection decisions are made. To address these gaps, we introduce SynthGuard, an open, user-friendly platform for detecting and analyzing AI-generated multimedia using both traditional detectors and multimodal large language models (MLLMs). SynthGuard provides explainable inference, unified image and audio support, and an interactive interface designed to make forensic analysis accessible to researchers, educators, and the public. The SynthGuard platform is available at: https://in-engr-nova.it.purdue.edu/
A Lightweight Convolution and Vision Transformer integrated model with Multi-scale Self-attention Mechanism
Aug 23, 2025Vision Transformer (ViT) has prevailed in computer vision tasks due to its strong long-range dependency modelling ability. However, its large model size with high computational cost and weak local feature modeling ability hinder its application in real scenarios. To balance computation efficiency and performance, we propose SAEViT (Sparse-Attention-Efficient-ViT), a lightweight ViT based model with convolution blocks, in this paper to achieve efficient downstream vision tasks. Specifically, SAEViT introduces a Sparsely Aggregated Attention (SAA) module that performs adaptive sparse sampling based on image redundancy and recovers the feature map via deconvolution operation, which significantly reduces the computational complexity of attention operations. In addition, a Channel-Interactive Feed-Forward Network (CIFFN) layer is developed to enhance inter-channel information exchange through feature decomposition and redistribution, mitigating redundancy in traditional feed-forward networks (FNN). Finally, a hierarchical pyramid structure with embedded depth-wise separable convolutional blocks (DWSConv) is devised to further strengthen convolutional features. Extensive experiments on mainstream datasets show that SAEViT achieves Top-1 accuracies of 76.3\% and 79.6\% on the ImageNet-1K classification task with only 0.8 GFLOPs and 1.3 GFLOPs, respectively, demonstrating a lightweight solution for various fundamental vision tasks.
MedChat: A Multi-Agent Framework for Multimodal Diagnosis with Large Language Models
Jun 09, 2025The integration of deep learning-based glaucoma detection with large language models (LLMs) presents an automated strategy to mitigate ophthalmologist shortages and improve clinical reporting efficiency. However, applying general LLMs to medical imaging remains challenging due to hallucinations, limited interpretability, and insufficient domain-specific medical knowledge, which can potentially reduce clinical accuracy. Although recent approaches combining imaging models with LLM reasoning have improved reporting, they typically rely on a single generalist agent, restricting their capacity to emulate the diverse and complex reasoning found in multidisciplinary medical teams. To address these limitations, we propose MedChat, a multi-agent diagnostic framework and platform that combines specialized vision models with multiple role-specific LLM agents, all coordinated by a director agent. This design enhances reliability, reduces hallucination risk, and enables interactive diagnostic reporting through an interface tailored for clinical review and educational use. Code available at https://github.com/Purdue-M2/MedChat.