 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSplat: Unified Spatio-Temporal Fusion via 3D Latent Scaffolds for Dynamic Driving Scene Reconstruction
Nov 06, 2025Feed-forward 3D reconstruction for autonomous driving has advanced rapidly, yet existing methods struggle with the joint challenges of sparse, non-overlapping camera views and complex scene dynamics. We present UniSplat, a general feed-forward framework that learns robust dynamic scene reconstruction through unified latent spatio-temporal fusion. UniSplat constructs a 3D latent scaffold, a structured representation that captures geometric and semantic scene context by leveraging pretrained foundation models. To effectively integrate information across spatial views and temporal frames, we introduce an efficient fusion mechanism that operates directly within the 3D scaffold, enabling consistent spatio-temporal alignment. To ensure complete and detailed reconstructions, we design a dual-branch decoder that generates dynamic-aware Gaussians from the fused scaffold by combining point-anchored refinement with voxel-based generation, and maintain a persistent memory of static Gaussians to enable streaming scene completion beyond current camera coverage. Extensive experiments on real-world datasets demonstrate that UniSplat achieves state-of-the-art performance in novel view synthesis, while providing robust and high-quality renderings even for viewpoints outside the original camera coverage.
DiST-4D: Disentangled Spatiotemporal Diffusion with Metric Depth for 4D Driving Scene Generation
Mar 19, 2025



Current generative models struggle to synthesize dynamic 4D driving scenes that simultaneously support temporal extrapolation and spatial novel view synthesis (NVS) without per-scene optimization. A key challenge lies in finding an efficient and generalizable geometric representation that seamlessly connects temporal and spatial synthesis. To address this, we propose DiST-4D, the first disentangled spatiotemporal diffusion framework for 4D driving scene generation, which leverages metric depth as the core geometric representation. DiST-4D decomposes the problem into two diffusion processes: DiST-T, which predicts future metric depth and multi-view RGB sequences directly from past observations, and DiST-S, which enables spatial NVS by training only on existing viewpoints while enforcing cycle consistency. This cycle consistency mechanism introduces a forward-backward rendering constraint, reducing the generalization gap between observed and unseen viewpoints. Metric depth is essential for both accurate reliable forecasting and accurate spatial NVS, as it provides a view-consistent geometric representation that generalizes well to unseen perspectives. Experiments demonstrate that DiST-4D achieves state-of-the-art performance in both temporal prediction and NVS tasks, while also delivering competitive performance in planning-related evaluations.
MuDG: Taming Multi-modal Diffusion with Gaussian Splatting for Urban Scene Reconstruction
Mar 13, 2025



Recent breakthroughs in radiance fields have significantly advanced 3D scene reconstruction and novel view synthesis (NVS) in autonomous driving. Nevertheless, critical limitations persist: reconstruction-based methods exhibit substantial performance deterioration under significant viewpoint deviations from training trajectories, while generation-based techniques struggle with temporal coherence and precise scene controllability. To overcome these challenges, we present MuDG, an innovative framework that integrates Multi-modal Diffusion model with Gaussian Splatting (GS) for Urban Scene Reconstruction. MuDG leverages aggregated LiDAR point clouds with RGB and geometric priors to condition a multi-modal video diffusion model, synthesizing photorealistic RGB, depth, and semantic outputs for novel viewpoints. This synthesis pipeline enables feed-forward NVS without computationally intensive per-scene optimization, providing comprehensive supervision signals to refine 3DGS representations for rendering robustness enhancement under extreme viewpoint changes. Experiments on the Open Waymo Dataset demonstrate that MuDG outperforms existing methods in both reconstruction and synthesis quality.
Re$^3$Sim: Generating High-Fidelity Simulation Data via 3D-Photorealistic Real-to-Sim for Robotic Manipulation
Feb 12, 2025Real-world data collection for robotics is costly and resource-intensive, requiring skilled operators and expensive hardware. Simulations offer a scalable alternative but often fail to achieve sim-to-real generalization due to geometric and visual gaps. To address these challenges, we propose a 3D-photorealistic real-to-sim system, namely, RE$^3$SIM, addressing geometric and visual sim-to-real gaps. RE$^3$SIM employs advanced 3D reconstruction and neural rendering techniques to faithfully recreate real-world scenarios, enabling real-time rendering of simulated cross-view cameras within a physics-based simulator. By utilizing privileged information to collect expert demonstrations efficiently in simulation, and train robot policies with imitation learning, we validate the effectiveness of the real-to-sim-to-real pipeline across various manipulation task scenarios. Notably, with only simulated data, we can achieve zero-shot sim-to-real transfer with an average success rate exceeding 58%. To push the limit of real-to-sim, we further generate a large-scale simulation dataset, demonstrating how a robust policy can be built from simulation data that generalizes across various objects. Codes and demos are available at: http://xshenhan.github.io/Re3Sim/.
Deformable Radial Kernel Splatting
Dec 16, 2024



Recently, Gaussian splatting has emerged as a robust technique for representing 3D scenes, enabling real-time rasterization and high-fidelity rendering. However, Gaussians' inherent radial symmetry and smoothness constraints limit their ability to represent complex shapes, often requiring thousands of primitives to approximate detailed geometry. We introduce Deformable Radial Kernel (DRK), which extends Gaussian splatting into a more general and flexible framework. Through learnable radial bases with adjustable angles and scales, DRK efficiently models diverse shape primitives while enabling precise control over edge sharpness and boundary curvature. iven DRK's planar nature, we further develop accurate ray-primitive intersection computation for depth sorting and introduce efficient kernel culling strategies for improved rasterization efficiency. Extensive experiments demonstrate that DRK outperforms existing methods in both representation efficiency and rendering quality, achieving state-of-the-art performance while dramatically reducing primitive count.
What Matters in Detecting AI-Generated Videos like Sora?
Jun 27, 2024Recent advancements in diffusion-based video generation have showcased remarkable results, yet the gap between synthetic and real-world videos remains under-explored. In this study, we examine this gap from three fundamental perspectives: appearance, motion, and geometry, comparing real-world videos with those generated by a state-of-the-art AI model, Stable Video Diffusion. To achieve this, we train three classifiers using 3D convolutional networks, each targeting distinct aspects: vision foundation model features for appearance, optical flow for motion, and monocular depth for geometry. Each classifier exhibits strong performance in fake video detection, both qualitatively and quantitatively. This indicates that AI-generated videos are still easily detectable, and a significant gap between real and fake videos persists. Furthermore, utilizing the Grad-CAM, we pinpoint systematic failures of AI-generated videos in appearance, motion, and geometry. Finally, we propose an Ensemble-of-Experts model that integrates appearance, optical flow, and depth information for fake video detection, resulting in enhanced robustness and generalization ability. Our model is capable of detecting videos generated by Sora with high accuracy, even without exposure to any Sora videos during training. This suggests that the gap between real and fake videos can be generalized across various video generative models. Project page: https://justin-crchang.github.io/3DCNNDetection.github.io/
Splatter a Video: Video Gaussian Representation for Versatile Processing
Jun 19, 2024



Video representation is a long-standing problem that is crucial for various down-stream tasks, such as tracking,depth prediction,segmentation,view synthesis,and editing. However, current methods either struggle to model complex motions due to the absence of 3D structure or rely on implicit 3D representations that are ill-suited for manipulation tasks. To address these challenges, we introduce a novel explicit 3D representation-video Gaussian representation -- that embeds a video into 3D Gaussians. Our proposed representation models video appearance in a 3D canonical space using explicit Gaussians as proxies and associates each Gaussian with 3D motions for video motion. This approach offers a more intrinsic and explicit representation than layered atlas or volumetric pixel matrices. To obtain such a representation, we distill 2D priors, such as optical flow and depth, from foundation models to regularize learning in this ill-posed setting. Extensive applications demonstrate the versatility of our new video representation. It has been proven effective in numerous video processing tasks, including tracking, consistent video depth and feature refinement, motion and appearance editing, and stereoscopic video generation. Project page: https://sunyangtian.github.io/spatter_a_video_web/
Total-Decom: Decomposed 3D Scene Reconstruction with Minimal Interaction
Mar 30, 2024



Scene reconstruction from multi-view images is a fundamental problem in computer vision and graphics. Recent neural implicit surface reconstruction methods have achieved high-quality results; however, editing and manipulating the 3D geometry of reconstructed scenes remains challenging due to the absence of naturally decomposed object entities and complex object/background compositions. In this paper, we present Total-Decom, a novel method for decomposed 3D reconstruction with minimal human interaction. Our approach seamlessly integrates the Segment Anything Model (SAM) with hybrid implicit-explicit neural surface representations and a mesh-based region-growing technique for accurate 3D object decomposition. Total-Decom requires minimal human annotations while providing users with real-time control over the granularity and quality of decomposition. We extensively evaluate our method on benchmark datasets and demonstrate its potential for downstream applications, such as animation and scene editing. The code is available at https://github.com/CVMI-Lab/Total-Decom.git.
3DGSR: Implicit Surface Reconstruction with 3D Gaussian Splatting
Mar 30, 2024In this paper, we present an implicit surface reconstruction method with 3D Gaussian Splatting (3DGS), namely 3DGSR, that allows for accurate 3D reconstruction with intricate details while inheriting the high efficiency and rendering quality of 3DGS. The key insight is incorporating an implicit signed distance field (SDF) within 3D Gaussians to enable them to be aligned and jointly optimized. First, we introduce a differentiable SDF-to-opacity transformation function that converts SDF values into corresponding Gaussians' opacities. This function connects the SDF and 3D Gaussians, allowing for unified optimization and enforcing surface constraints on the 3D Gaussians. During learning, optimizing the 3D Gaussians provides supervisory signals for SDF learning, enabling the reconstruction of intricate details. However, this only provides sparse supervisory signals to the SDF at locations occupied by Gaussians, which is insufficient for learning a continuous SDF. Then, to address this limitation, we incorporate volumetric rendering and align the rendered geometric attributes (depth, normal) with those derived from 3D Gaussians. This consistency regularization introduces supervisory signals to locations not covered by discrete 3D Gaussians, effectively eliminating redundant surfaces outside the Gaussian sampling range. Our extensive experimental results demonstrate that our 3DGSR method enables high-quality 3D surface reconstruction while preserving the efficiency and rendering quality of 3DGS. Besides, our method competes favorably with leading surface reconstruction techniques while offering a more efficient learning process and much better rendering qualities. The code will be available at https://github.com/CVMI-Lab/3DGSR.
DO3D: Self-supervised Learning of Decomposed Object-aware 3D Motion and Depth from Monocular Videos
Mar 09, 2024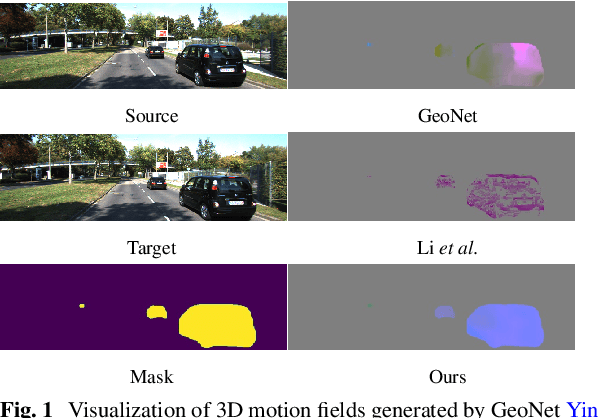
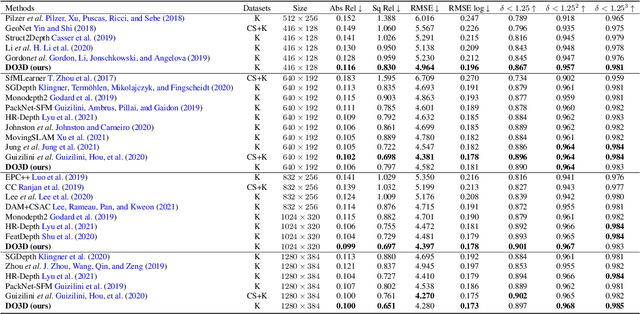
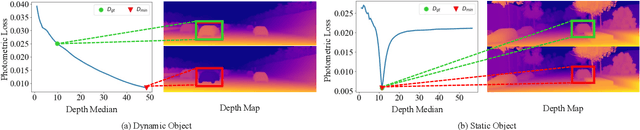

Although considerable advancements have been attained in self-supervised depth estimation from monocular videos, most existing methods often treat all objects in a video as static entities, which however violates the dynamic nature of real-world scenes and fails to model the geometry and motion of moving objects. In this paper, we propose a self-supervised method to jointly learn 3D motion and depth from monocular videos. Our system contains a depth estimation module to predict depth, and a new decomposed object-wise 3D motion (DO3D) estimation module to predict ego-motion and 3D object motion. Depth and motion networks work collaboratively to faithfully model the geometry and dynamics of real-world scenes, which, in turn, benefits both depth and 3D motion estimation. Their predictions are further combined to synthesize a novel video frame for self-supervised training. As a core component of our framework, DO3D is a new motion disentanglement module that learns to predict camera ego-motion and instance-aware 3D object motion separately. To alleviate the difficulties in estimating non-rigid 3D object motions, they are decomposed to object-wise 6-DoF global transformations and a pixel-wise local 3D motion deformation field. Qualitative and quantitative experiments are conducted on three benchmark datasets, including KITTI, Cityscapes, and VKITTI2, where our model delivers superior performance in all evaluated settings. For the depth estimation task, our model outperforms all compared research works in the high-resolution setting, attaining an absolute relative depth error (abs rel) of 0.099 on the KITTI benchmark. Besides, our optical flow estimation results (an overall EPE of 7.09 on KITTI) also surpass state-of-the-art methods and largely improve the estimation of dynamic regions, demonstrating the effectiveness of our motion model. Our code will be available.