 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne for More: Selecting Generalizable Samples for Generalizable ReID Model
Dec 11, 2020
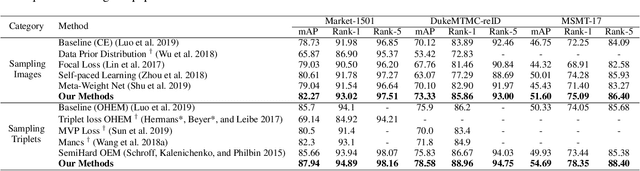
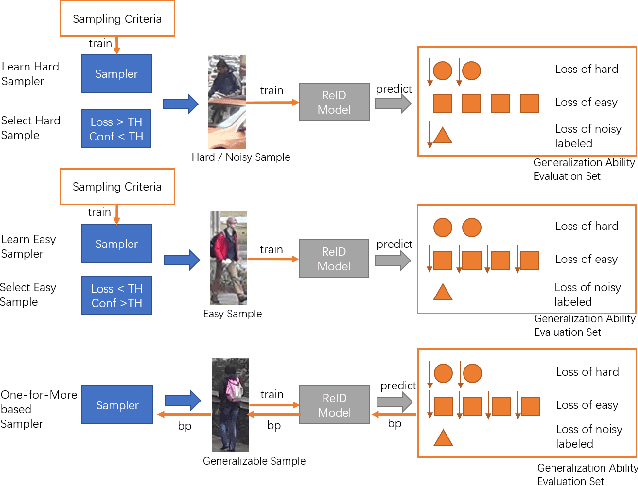
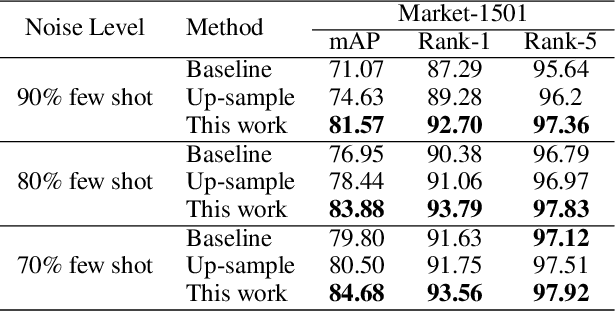
Current training objectives of existing person Re-IDentification (ReID) models only ensure that the loss of the model decreases on selected training batch, with no regards to the performance on samples outside the batch. It will inevitably cause the model to over-fit the data in the dominant position (e.g., head data in imbalanced class, easy samples or noisy samples). %We call the sample that updates the model towards generalizing on more data a generalizable sample. The latest resampling methods address the issue by designing specific criterion to select specific samples that trains the model generalize more on certain type of data (e.g., hard samples, tail data), which is not adaptive to the inconsistent real world ReID data distributions. Therefore, instead of simply presuming on what samples are generalizable, this paper proposes a one-for-more training objective that directly takes the generalization ability of selected samples as a loss function and learn a sampler to automatically select generalizable samples. More importantly, our proposed one-for-more based sampler can be seamlessly integrated into the ReID training framework which is able to simultaneously train ReID models and the sampler in an end-to-end fashion. The experimental results show that our method can effectively improve the ReID model training and boost the performance of ReID models.
Pruning Filter in Filter
Oct 18, 2020
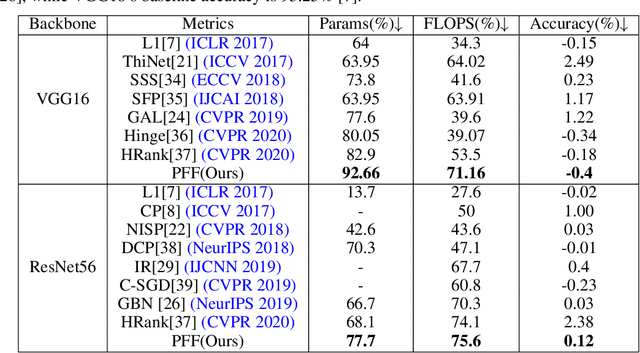
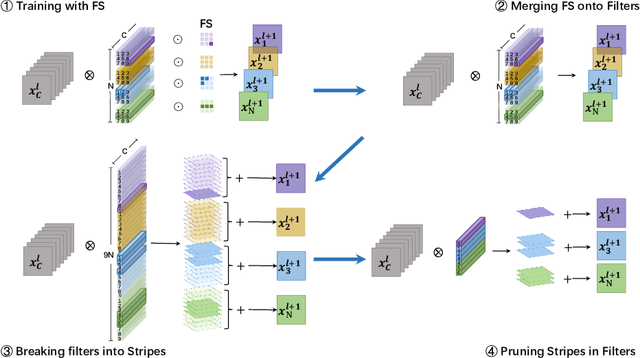
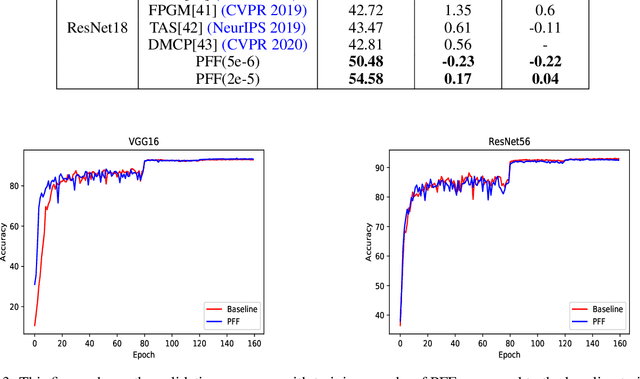
Pruning has become a very powerful and effective technique to compress and accelerate modern neural networks. Existing pruning methods can be grouped into two categories: filter pruning (FP) and weight pruning (WP). FP wins at hardware compatibility but loses at the compression ratio compared with WP. To converge the strength of both methods, we propose to prune the filter in the filter. Specifically, we treat a filter $F \in \mathbb{R}^{C\times K\times K}$ as $K \times K$ stripes, \emph{i.e.}, $1\times 1$ filters $\in \mathbb{R}^{C}$, then by pruning the stripes instead of the whole filter, we can achieve finer granularity than traditional FP while being hardware friendly. We term our method as SWP (\emph{Stripe-Wise Pruning}). SWP is implemented by introducing a novel learnable matrix called Filter Skeleton, whose values reflect the shape of each filter. As some recent work has shown that the pruned architecture is more crucial than the inherited important weights, we argue that the architecture of a single filter, \emph{i.e.}, the shape, also matters. Through extensive experiments, we demonstrate that SWP is more effective compared to the previous FP-based methods and achieves the state-of-art pruning ratio on CIFAR-10 and ImageNet datasets without obvious accuracy drop. Code is available at https://github.com/fxmeng/Pruning-Filter-in-Filter
Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion
Sep 12, 2020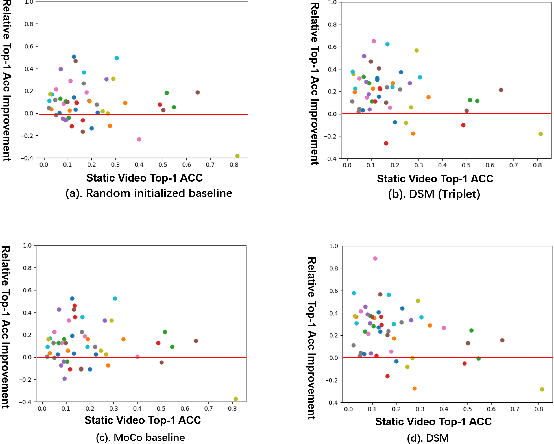

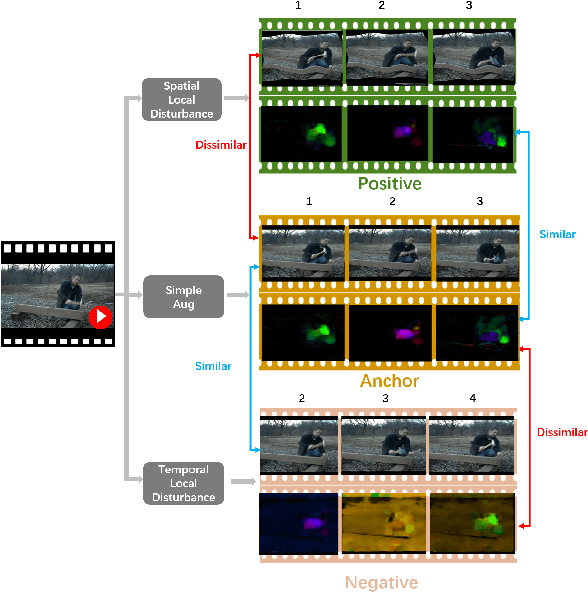
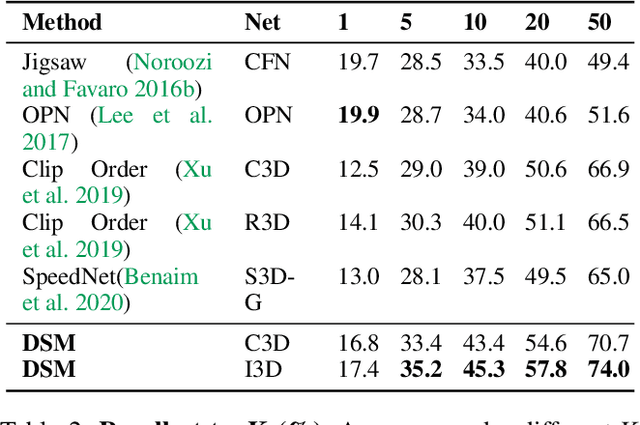
One significant factor we expect the video representation learning to capture, especially in contrast with the image representation learning, is the object motion. However, we found that in the current mainstream video datasets, some action categories are highly related with the scene where the action happens, making the model tend to degrade to a solution where only the scene information is encoded. For example, a trained model may predict a video as playing football simply because it sees the field, neglecting that the subject is dancing as a cheerleader on the field. This is against our original intention towards the video representation learning and may bring scene bias on different dataset that can not be ignored. In order to tackle this problem, we propose to decouple the scene and the motion (DSM) with two simple operations, so that the model attention towards the motion information is better paid. Specifically, we construct a positive clip and a negative clip for each video. Compared to the original video, the positive/negative is motion-untouched/broken but scene-broken/untouched by Spatial Local Disturbance and Temporal Local Disturbance. Our objective is to pull the positive closer while pushing the negative farther to the original clip in the latent space. In this way, the impact of the scene is weakened while the temporal sensitivity of the network is further enhanced. We conduct experiments on two tasks with various backbones and different pre-training datasets, and find that our method surpass the SOTA methods with a remarkable 8.1% and 8.8% improvement towards action recognition task on the UCF101 and HMDB51 datasets respectively using the same backbone.
Devil's in the Detail: Graph-based Key-point Alignment and Embedding for Person Re-ID
Sep 11, 2020

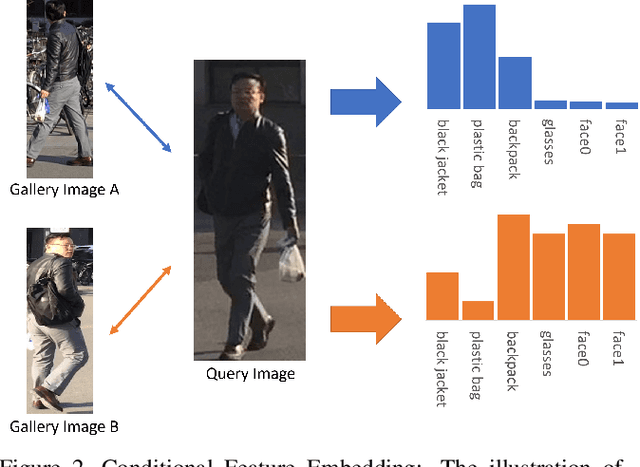
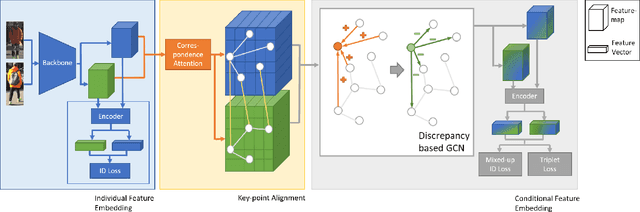
Although Person Re-Identification has made impressive progress, difficult cases like occlusion, change of view-point and similar clothing still bring great challenges. Besides overall visual features, matching and comparing detailed local information is also essential for tackling these challenges. This paper proposes two key recognition patterns to better utilize the local information of pedestrian images. From the spatial perspective, the model should be able to select and align key-points from the image pairs for comparison (i.e. key-points alignment). From the perspective of feature channels, the feature of a query image should be dynamically adjusted based on the gallery image it needs to match (i.e. conditional feature embedding). Most of the existing methods are unable to satisfy both key-point alignment and conditional feature embedding. By introducing novel techniques including correspondence attention module and discrepancy-based GCN, we propose an end-to-end ReID method that integrates both patterns into a unified framework, called Siamese-GCN. The experiments show that Siamese-GCN achieves state-of-the-art performance on three public datasets.
Do Not Disturb Me: Person Re-identification Under the Interference of Other Pedestrians
Aug 16, 2020
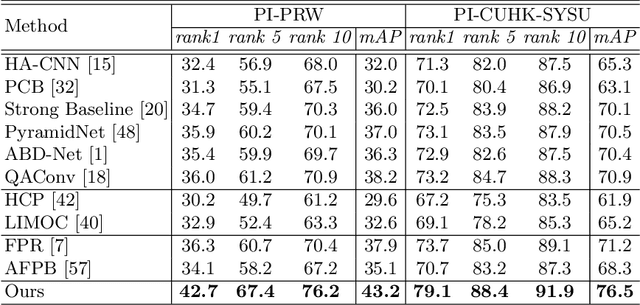
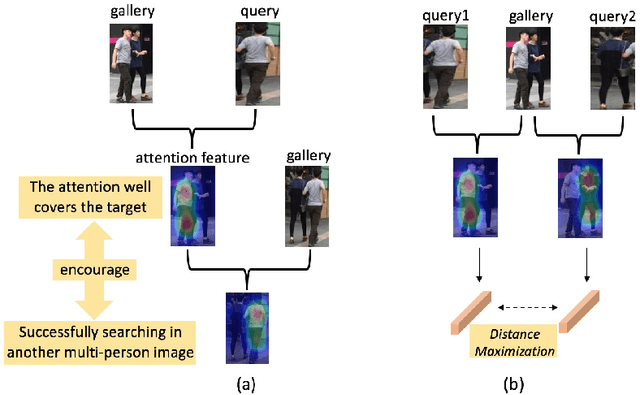
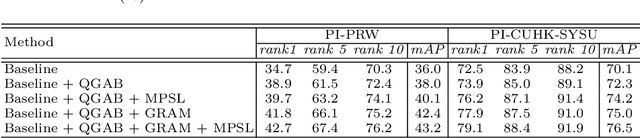
In the conventional person Re-ID setting, it is widely assumed that cropped person images are for each individual. However, in a crowded scene, off-shelf-detectors may generate bounding boxes involving multiple people, where the large proportion of background pedestrians or human occlusion exists. The representation extracted from such cropped images, which contain both the target and the interference pedestrians, might include distractive information. This will lead to wrong retrieval results. To address this problem, this paper presents a novel deep network termed Pedestrian-Interference Suppression Network (PISNet). PISNet leverages a Query-Guided Attention Block (QGAB) to enhance the feature of the target in the gallery, under the guidance of the query. Furthermore, the involving Guidance Reversed Attention Module and the Multi-Person Separation Loss promote QGAB to suppress the interference of other pedestrians. Our method is evaluated on two new pedestrian-interference datasets and the results show that the proposed method performs favorably against existing Re-ID methods.
NOH-NMS: Improving Pedestrian Detection by Nearby Objects Hallucination
Jul 27, 2020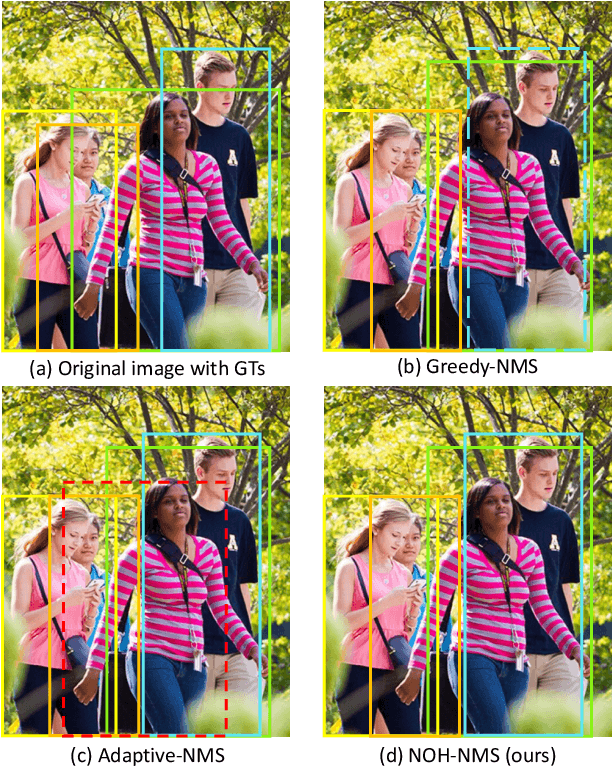
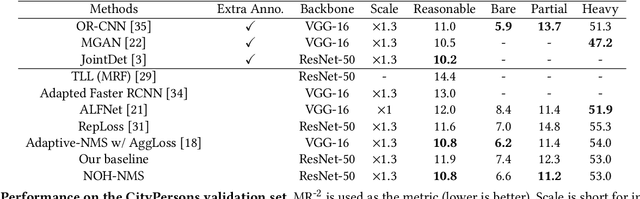

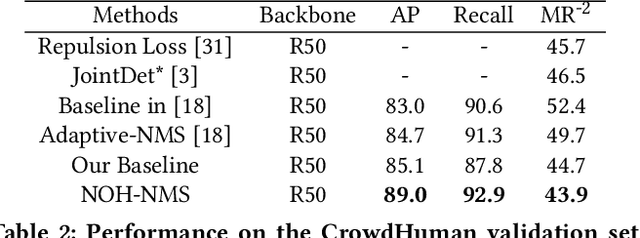
Greedy-NMS inherently raises a dilemma, where a lower NMS threshold will potentially lead to a lower recall rate and a higher threshold introduces more false positives. This problem is more severe in pedestrian detection because the instance density varies more intensively. However, previous works on NMS don't consider or vaguely consider the factor of the existent of nearby pedestrians. Thus, we propose Nearby Objects Hallucinator (NOH), which pinpoints the objects nearby each proposal with a Gaussian distribution, together with NOH-NMS, which dynamically eases the suppression for the space that might contain other objects with a high likelihood. Compared to Greedy-NMS, our method, as the state-of-the-art, improves by $3.9\%$ AP, $5.1\%$ Recall, and $0.8\%$ $\text{MR}^{-2}$ on CrowdHuman to $89.0\%$ AP and $92.9\%$ Recall, and $43.9\%$ $\text{MR}^{-2}$ respectively.
Transfer Deep Reinforcement Learning-enabled Energy Management Strategy for Hybrid Tracked Vehicle
Jul 16, 2020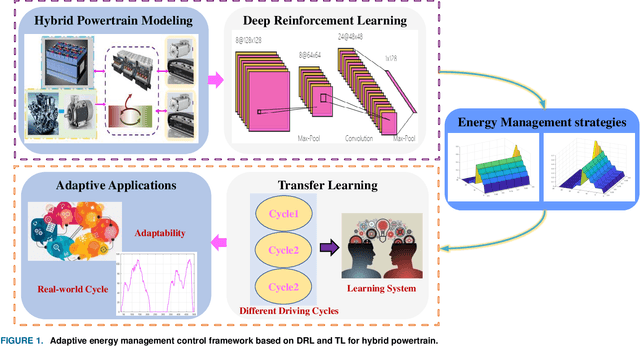
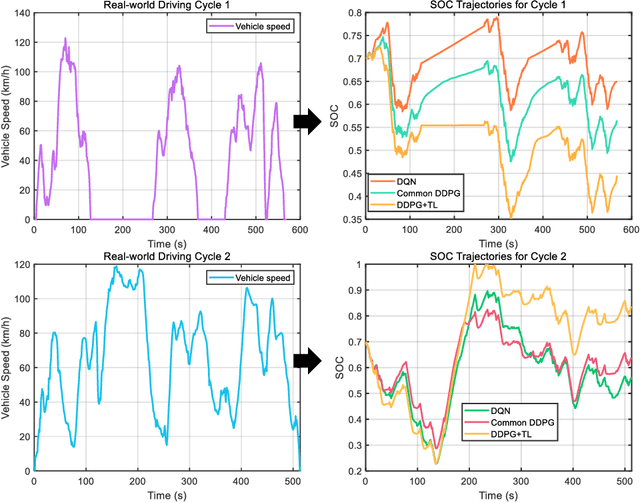
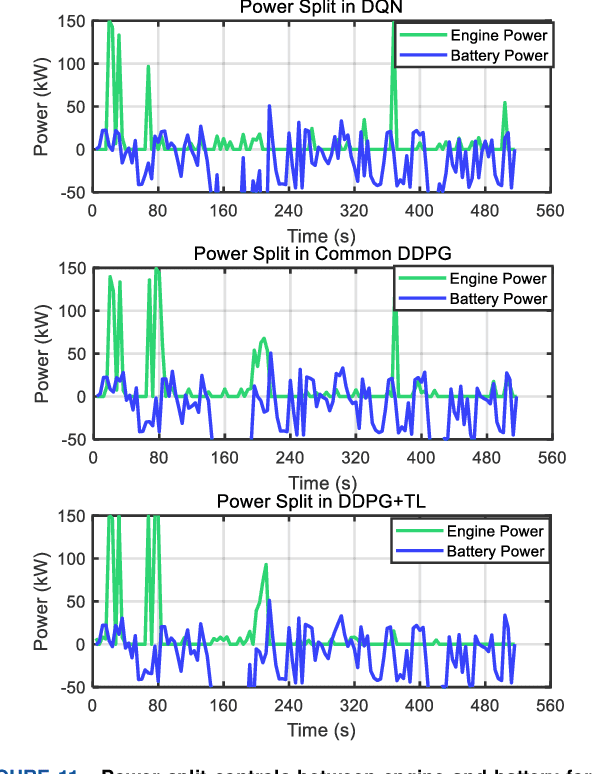
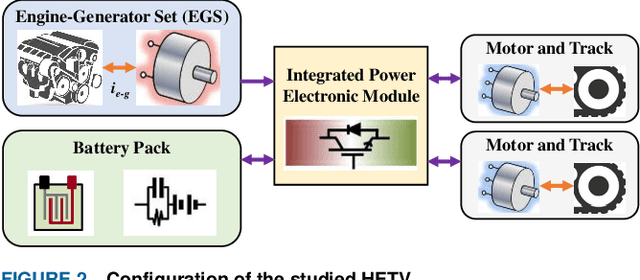
This paper proposes an adaptive energy management strategy for hybrid electric vehicles by combining deep reinforcement learning (DRL) and transfer learning (TL). This work aims to address the defect of DRL in tedious training time. First, an optimization control modeling of a hybrid tracked vehicle is built, wherein the elaborate powertrain components are introduced. Then, a bi-level control framework is constructed to derive the energy management strategies (EMSs). The upper-level is applying the particular deep deterministic policy gradient (DDPG) algorithms for EMS training at different speed intervals. The lower-level is employing the TL method to transform the pre-trained neural networks for a novel driving cycle. Finally, a series of experiments are executed to prove the effectiveness of the presented control framework. The optimality and adaptability of the formulated EMS are illuminated. The founded DRL and TL-enabled control policy is capable of enhancing energy efficiency and improving system performance.
Dynamic Refinement Network for Oriented and Densely Packed Object Detection
Jun 10, 2020
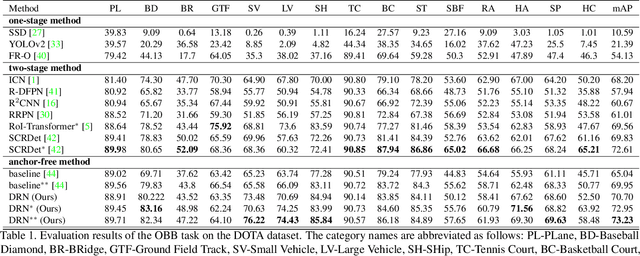
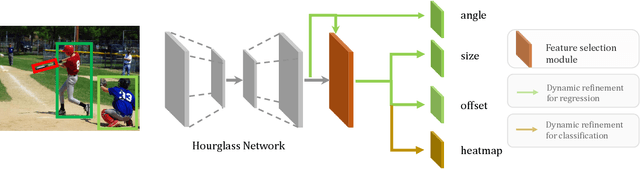

Object detection has achieved remarkable progress in the past decade. However, the detection of oriented and densely packed objects remains challenging because of following inherent reasons: (1) receptive fields of neurons are all axis-aligned and of the same shape, whereas objects are usually of diverse shapes and align along various directions; (2) detection models are typically trained with generic knowledge and may not generalize well to handle specific objects at test time; (3) the limited dataset hinders the development on this task. To resolve the first two issues, we present a dynamic refinement network that consists of two novel components, i.e., a feature selection module (FSM) and a dynamic refinement head (DRH). Our FSM enables neurons to adjust receptive fields in accordance with the shapes and orientations of target objects, whereas the DRH empowers our model to refine the prediction dynamically in an object-aware manner. To address the limited availability of related benchmarks, we collect an extensive and fully annotated dataset, namely, SKU110K-R, which is relabeled with oriented bounding boxes based on SKU110K. We perform quantitative evaluations on several publicly available benchmarks including DOTA, HRSC2016, SKU110K, and our own SKU110K-R dataset. Experimental results show that our method achieves consistent and substantial gains compared with baseline approaches. The code and dataset are available at https://github.com/Anymake/DRN_CVPR2020.
DGD: Densifying the Knowledge of Neural Networks with Filter Grafting and Knowledge Distillation
Apr 26, 2020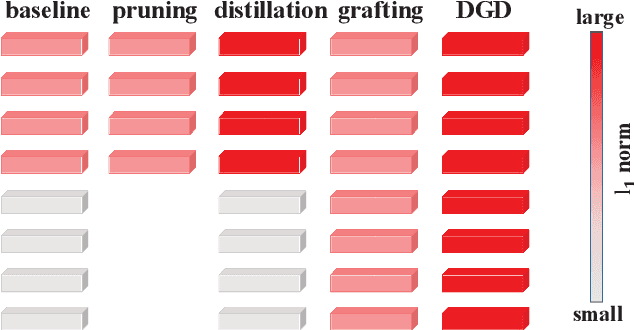
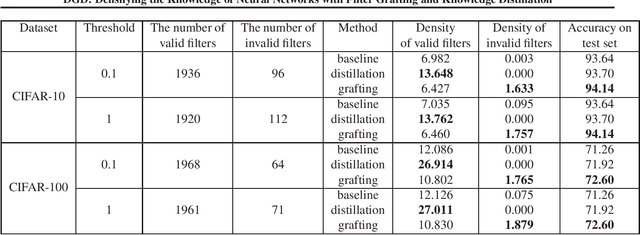
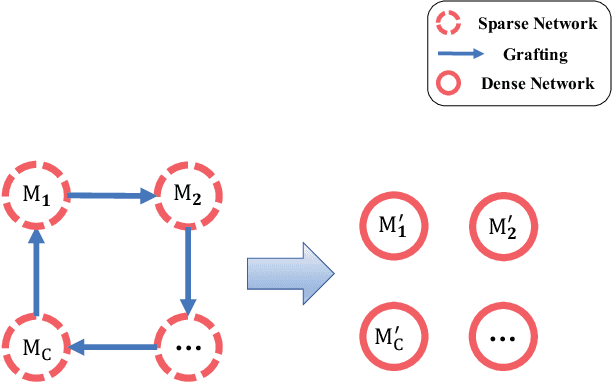
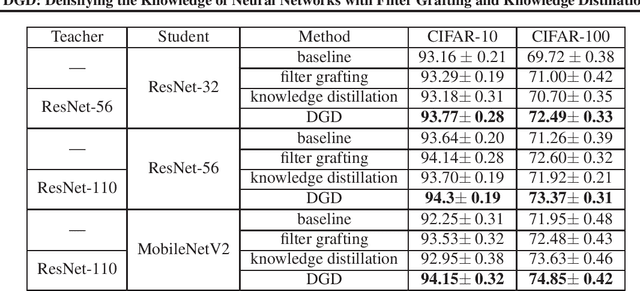
With a fixed model structure, knowledge distillation and filter grafting are two effective ways to boost single model accuracy. However, the working mechanism and the differences between distillation and grafting have not been fully unveiled. In this paper, we evaluate the effect of distillation and grafting in the filter level, and find that the impacts of the two techniques are surprisingly complementary: distillation mostly enhances the knowledge of valid filters while grafting mostly reactivates invalid filters. This observation guides us to design a unified training framework called DGD, where distillation and grafting are naturally combined to increase the knowledge density inside the filters given a fixed model structure. Through extensive experiments, we show that the knowledge densified network in DGD shares both advantages of distillation and grafting, lifting the model accuracy to a higher level.
Asymmetric Co-Teaching for Unsupervised Cross Domain Person Re-Identification
Dec 03, 2019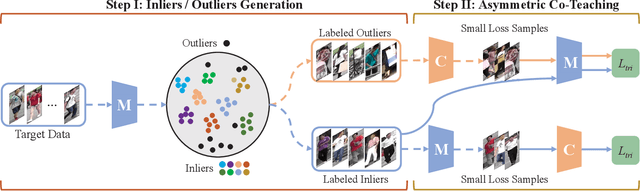
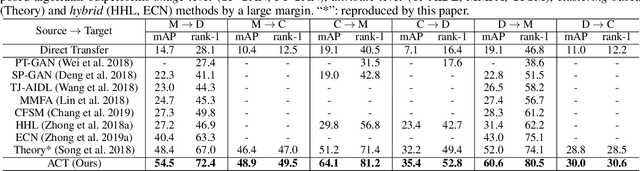
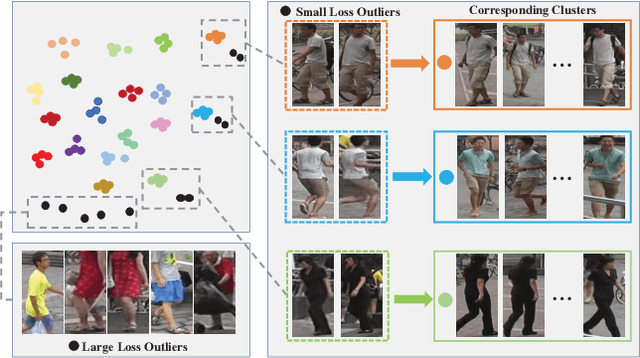

Person re-identification (re-ID), is a challenging task due to the high variance within identity samples and imaging conditions. Although recent advances in deep learning have achieved remarkable accuracy in settled scenes, i.e., source domain, few works can generalize well on the unseen target domain. One popular solution is assigning unlabeled target images with pseudo labels by clustering, and then retraining the model. However, clustering methods tend to introduce noisy labels and discard low confidence samples as outliers, which may hinder the retraining process and thus limit the generalization ability. In this study, we argue that by explicitly adding a sample filtering procedure after the clustering, the mined examples can be much more efficiently used. To this end, we design an asymmetric co-teaching framework, which resists noisy labels by cooperating two models to select data with possibly clean labels for each other. Meanwhile, one of the models receives samples as pure as possible, while the other takes in samples as diverse as possible. This procedure encourages that the selected training samples can be both clean and miscellaneous, and that the two models can promote each other iteratively. Extensive experiments show that the proposed framework can consistently benefit most clustering-based methods, and boost the state-of-the-art adaptation accuracy. Our code is available at https://github.com/FlyingRoastDuck/ACT_AAAI20.