 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort and Long Range Relation Based Spatio-Temporal Transformer for Micro-Expression Recognition
Dec 14, 2021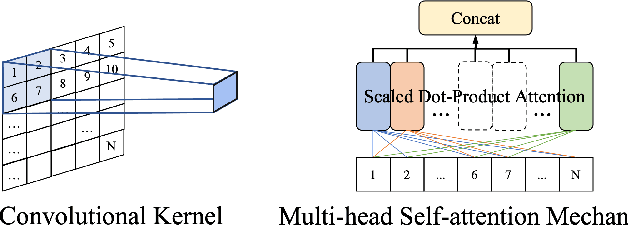
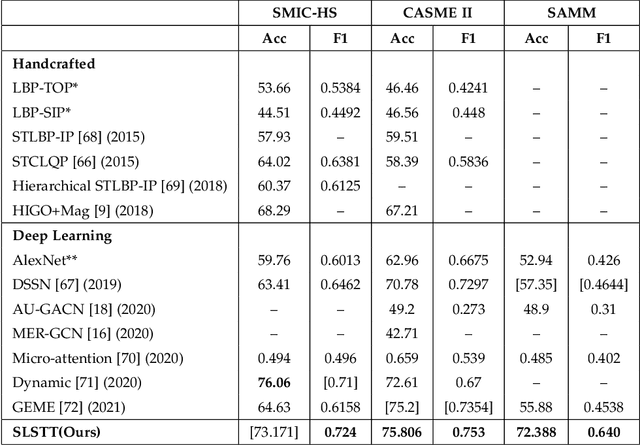
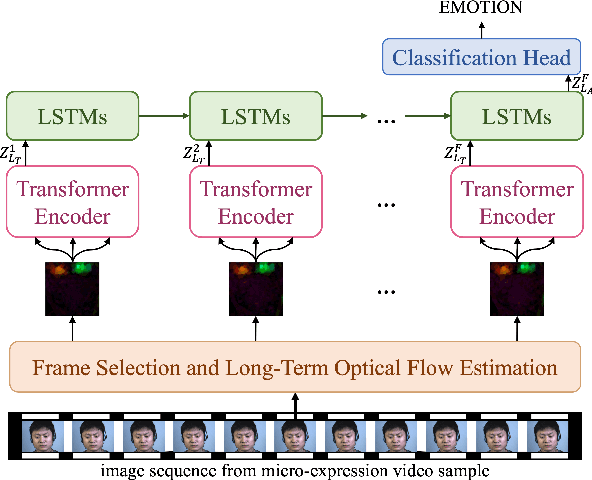
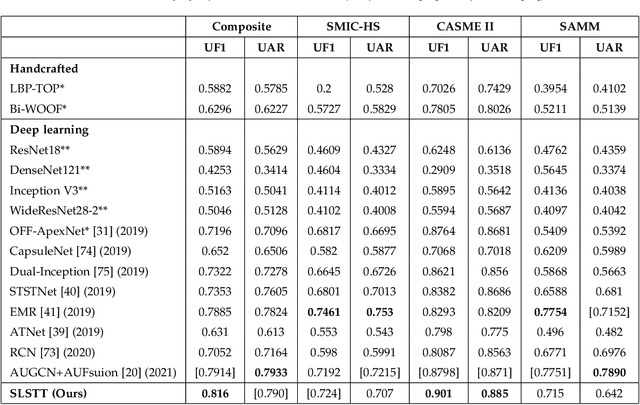
Being spontaneous, micro-expressions are useful in the inference of a person's true emotions even if an attempt is made to conceal them. Due to their short duration and low intensity, the recognition of micro-expressions is a difficult task in affective computing. The early work based on handcrafted spatio-temporal features which showed some promise, has recently been superseded by different deep learning approaches which now compete for the state of the art performance. Nevertheless, the problem of capturing both local and global spatio-temporal patterns remains challenging. To this end, herein we propose a novel spatio-temporal transformer architecture -- to the best of our knowledge, the first purely transformer based approach (i.e. void of any convolutional network use) for micro-expression recognition. The architecture comprises a spatial encoder which learns spatial patterns, a temporal aggregator for temporal dimension analysis, and a classification head. A comprehensive evaluation on three widely used spontaneous micro-expression data sets, namely SMIC-HS, CASME II and SAMM, shows that the proposed approach consistently outperforms the state of the art, and is the first framework in the published literature on micro-expression recognition to achieve the unweighted F1-score greater than 0.9 on any of the aforementioned data sets.
Object Counting: You Only Need to Look at One
Dec 11, 2021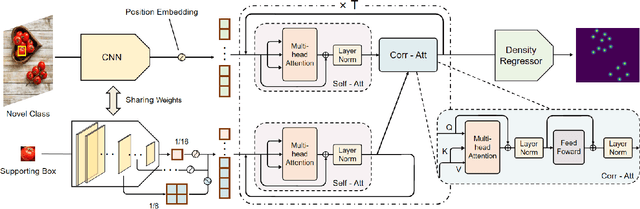
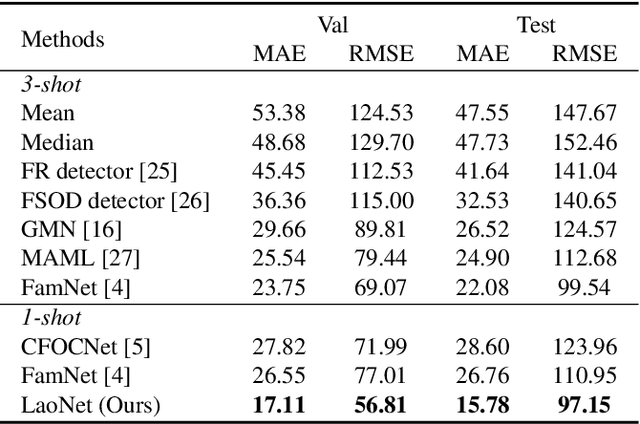


This paper aims to tackle the challenging task of one-shot object counting. Given an image containing novel, previously unseen category objects, the goal of the task is to count all instances in the desired category with only one supporting bounding box example. To this end, we propose a counting model by which you only need to Look At One instance (LaoNet). First, a feature correlation module combines the Self-Attention and Correlative-Attention modules to learn both inner-relations and inter-relations. It enables the network to be robust to the inconsistency of rotations and sizes among different instances. Second, a Scale Aggregation mechanism is designed to help extract features with different scale information. Compared with existing few-shot counting methods, LaoNet achieves state-of-the-art results while learning with a high convergence speed. The code will be available soon.
3D Visual Tracking Framework with Deep Learning for Asteroid Exploration
Nov 21, 2021

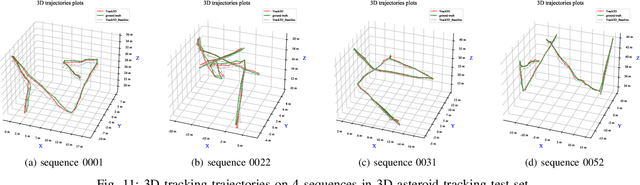
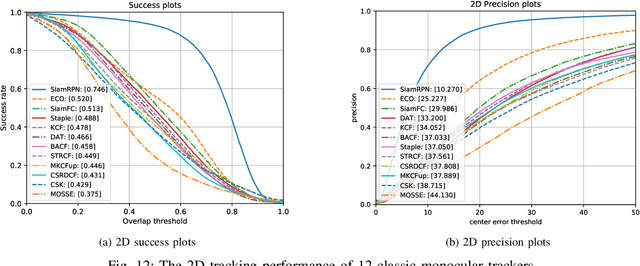
3D visual tracking is significant to deep space exploration programs, which can guarantee spacecraft to flexibly approach the target. In this paper, we focus on the studied accurate and real-time method for 3D tracking. Considering the fact that there are almost no public dataset for this topic, A new large-scale 3D asteroid tracking dataset is presented, including binocular video sequences, depth maps, and point clouds of diverse asteroids with various shapes and textures. Benefitting from the power and convenience of simulation platform, all the 2D and 3D annotations are automatically generated. Meanwhile, we propose a deep-learning based 3D tracking framework, named as Track3D, which involves 2D monocular tracker and a novel light-weight amodal axis-aligned bounding-box network, A3BoxNet. The evaluation results demonstrate that Track3D achieves state-of-the-art 3D tracking performance in both accuracy and precision, comparing to a baseline algorithm. Moreover, our framework has great generalization ability to 2D monocular tracking performance.
Discovery-and-Selection: Towards Optimal Multiple Instance Learning for Weakly Supervised Object Detection
Oct 18, 2021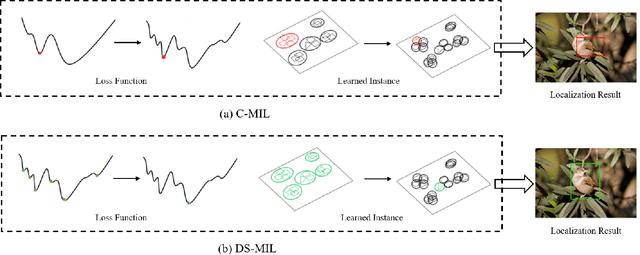
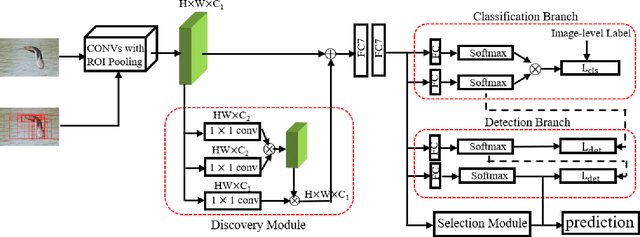
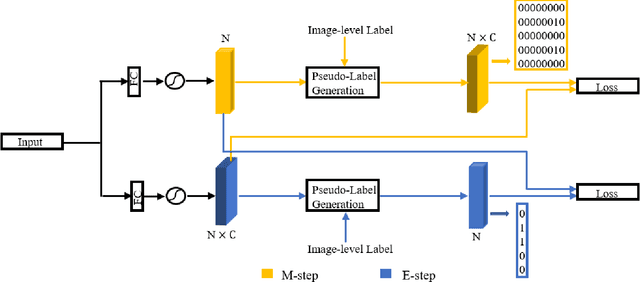

Weakly supervised object detection (WSOD) is a challenging task that requires simultaneously learn object classifiers and estimate object locations under the supervision of image category labels. A major line of WSOD methods roots in multiple instance learning which regards images as bags of instance and selects positive instances from each bag to learn the detector. However, a grand challenge emerges when the detector inclines to converge to discriminative parts of objects rather than the whole objects. In this paper, under the hypothesis that optimal solutions are included in local minima, we propose a discoveryand-selection approach fused with multiple instance learning (DS-MIL), which finds rich local minima and select optimal solutions from multiple local minima. To implement DS-MIL, an attention module is designed so that more context information can be captured by feature maps and more valuable proposals can be collected during training. With proposal candidates, a re-rank module is designed to select informative instances for object detector training. Experimental results on commonly used benchmarks show that our proposed DS-MIL approach can consistently improve the baselines, reporting state-of-the-art performance.
Anomaly Detection via Self-organizing Map
Jul 21, 2021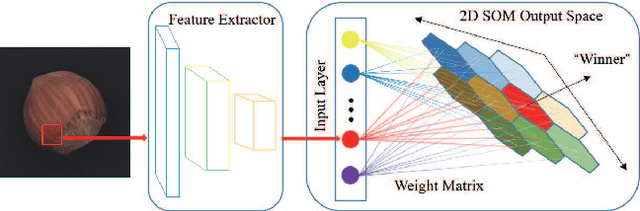
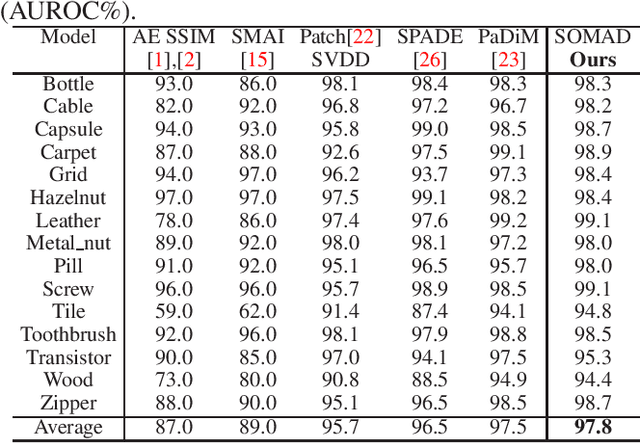
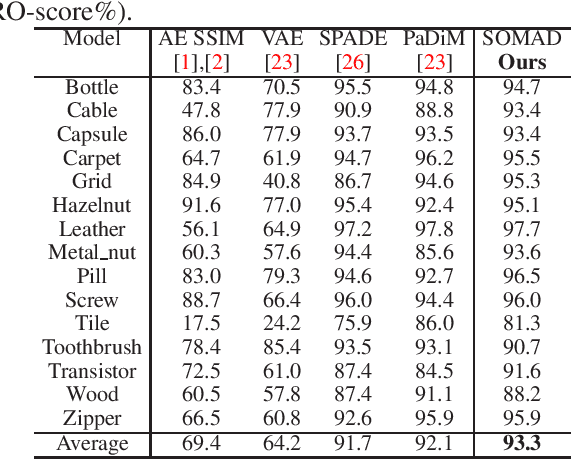
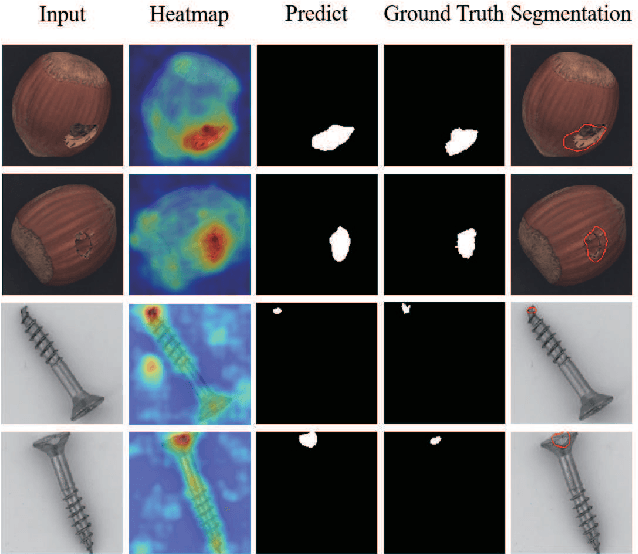
Anomaly detection plays a key role in industrial manufacturing for product quality control. Traditional methods for anomaly detection are rule-based with limited generalization ability. Recent methods based on supervised deep learning are more powerful but require large-scale annotated datasets for training. In practice, abnormal products are rare thus it is very difficult to train a deep model in a fully supervised way. In this paper, we propose a novel unsupervised anomaly detection approach based on Self-organizing Map (SOM). Our method, Self-organizing Map for Anomaly Detection (SOMAD) maintains normal characteristics by using topological memory based on multi-scale features. SOMAD achieves state-of the-art performance on unsupervised anomaly detection and localization on the MVTec dataset.
Direct Measure Matching for Crowd Counting
Jul 04, 2021
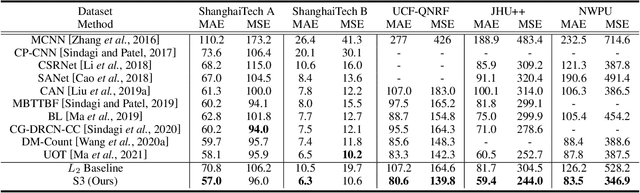
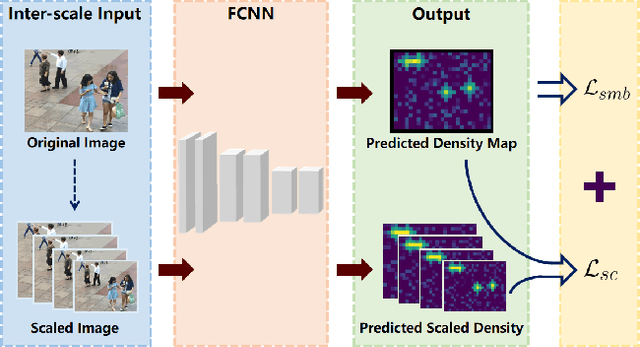

Traditional crowd counting approaches usually use Gaussian assumption to generate pseudo density ground truth, which suffers from problems like inaccurate estimation of the Gaussian kernel sizes. In this paper, we propose a new measure-based counting approach to regress the predicted density maps to the scattered point-annotated ground truth directly. First, crowd counting is formulated as a measure matching problem. Second, we derive a semi-balanced form of Sinkhorn divergence, based on which a Sinkhorn counting loss is designed for measure matching. Third, we propose a self-supervised mechanism by devising a Sinkhorn scale consistency loss to resist scale changes. Finally, an efficient optimization method is provided to minimize the overall loss function. Extensive experiments on four challenging crowd counting datasets namely ShanghaiTech, UCF-QNRF, JHU++, and NWPU have validated the proposed method.
Know Your Surroundings: Panoramic Multi-Object Tracking by Multimodality Collaboration
May 31, 2021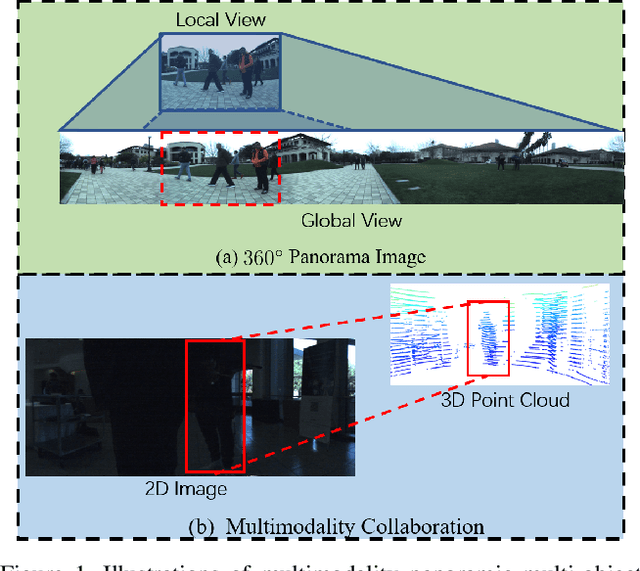
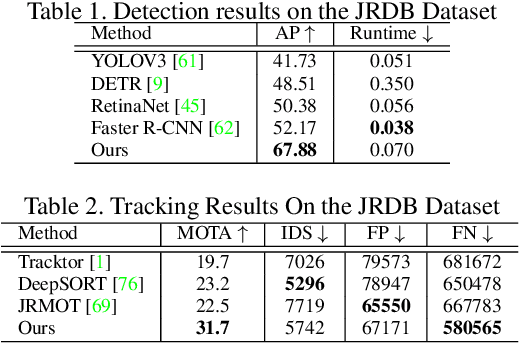


In this paper, we focus on the multi-object tracking (MOT) problem of automatic driving and robot navigation. Most existing MOT methods track multiple objects using a singular RGB camera, which are prone to camera field-of-view and suffer tracking failures in complex scenarios due to background clutters and poor light conditions. To meet these challenges, we propose a MultiModality PAnoramic multi-object Tracking framework (MMPAT), which takes both 2D panorama images and 3D point clouds as input and then infers target trajectories using the multimodality data. The proposed method contains four major modules, a panorama image detection module, a multimodality data fusion module, a data association module and a trajectory inference model. We evaluate the proposed method on the JRDB dataset, where the MMPAT achieves the top performance in both the detection and tracking tasks and significantly outperforms state-of-the-art methods by a large margin (15.7 and 8.5 improvement in terms of AP and MOTA, respectively).
Image-to-image Translation via Hierarchical Style Disentanglement
Mar 02, 2021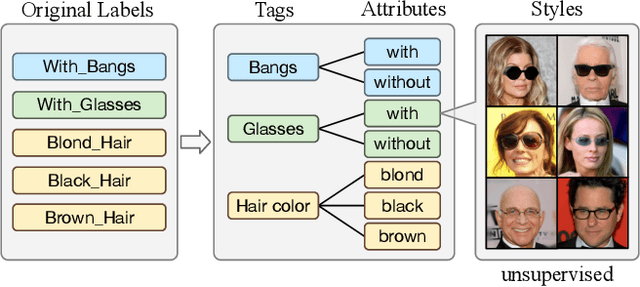


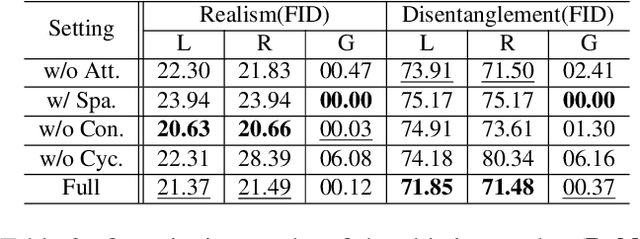
Recently, image-to-image translation has made significant progress in achieving both multi-label (\ie, translation conditioned on different labels) and multi-style (\ie, generation with diverse styles) tasks. However, due to the unexplored independence and exclusiveness in the labels, existing endeavors are defeated by involving uncontrolled manipulations to the translation results. In this paper, we propose Hierarchical Style Disentanglement (HiSD) to address this issue. Specifically, we organize the labels into a hierarchical tree structure, in which independent tags, exclusive attributes, and disentangled styles are allocated from top to bottom. Correspondingly, a new translation process is designed to adapt the above structure, in which the styles are identified for controllable translations. Both qualitative and quantitative results on the CelebA-HQ dataset verify the ability of the proposed HiSD. We hope our method will serve as a solid baseline and provide fresh insights with the hierarchically organized annotations for future research in image-to-image translation. The code has been released at https://github.com/imlixinyang/HiSD.
Learning Task-oriented Disentangled Representations for Unsupervised Domain Adaptation
Jul 27, 2020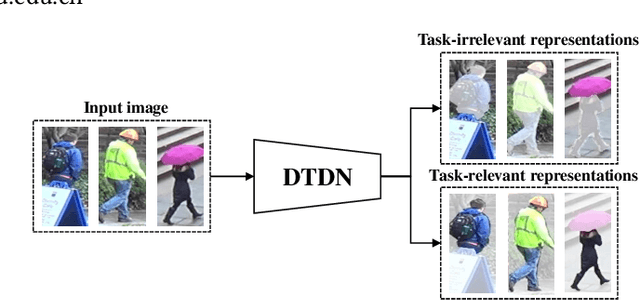
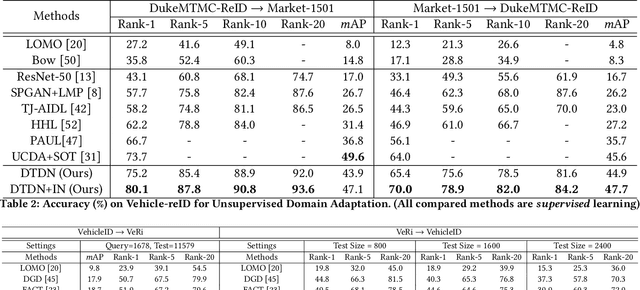
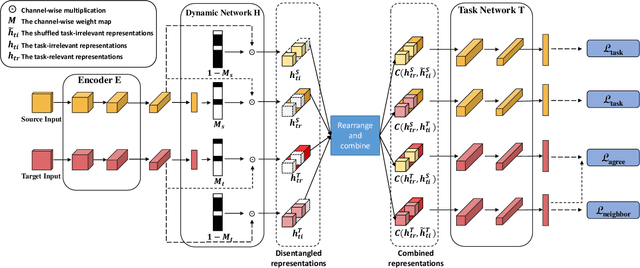
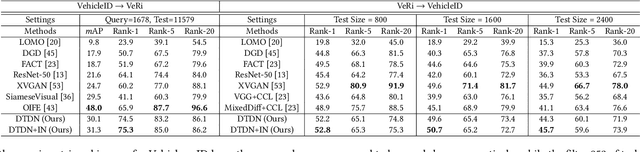
Unsupervised domain adaptation (UDA) aims to address the domain-shift problem between a labeled source domain and an unlabeled target domain. Many efforts have been made to address the mismatch between the distributions of training and testing data, but unfortunately, they ignore the task-oriented information across domains and are inflexible to perform well in complicated open-set scenarios. Many efforts have been made to eliminate the mismatch between the distributions of training and testing data by learning domain-invariant representations. However, the learned representations are usually not task-oriented, i.e., being class-discriminative and domain-transferable simultaneously. This drawback limits the flexibility of UDA in complicated open-set tasks where no labels are shared between domains. In this paper, we break the concept of task-orientation into task-relevance and task-irrelevance, and propose a dynamic task-oriented disentangling network (DTDN) to learn disentangled representations in an end-to-end fashion for UDA. The dynamic disentangling network effectively disentangles data representations into two components: the task-relevant ones embedding critical information associated with the task across domains, and the task-irrelevant ones with the remaining non-transferable or disturbing information. These two components are regularized by a group of task-specific objective functions across domains. Such regularization explicitly encourages disentangling and avoids the use of generative models or decoders. Experiments in complicated, open-set scenarios (retrieval tasks) and empirical benchmarks (classification tasks) demonstrate that the proposed method captures rich disentangled information and achieves superior performance.
Micro-expression spotting: A new benchmark
Jul 24, 2020
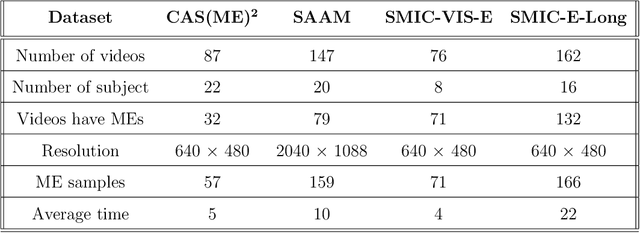

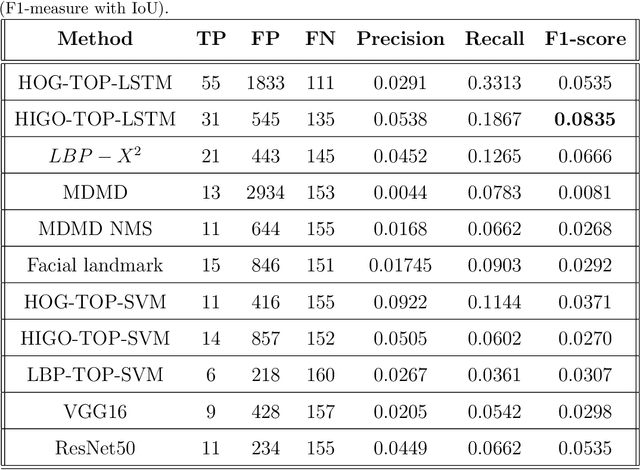
Micro-expressions (MEs) are brief and involuntary facial expressions that occur when people are trying to hide their true feelings or conceal their emotions. Based on psychology research, MEs play an important role in understanding genuine emotions, which leads to many potential applications. Therefore, ME analysis has been becoming an attractive topic for various research areas, such as psychology, law enforcement, and psychotherapy. In the computer vision field, the study of MEs can be divided into two main tasks: spotting and recognition, which are to identify positions of MEs in videos and determine the emotion category of detected MEs, respectively. Recently, although much research has been done, the construction of a fully automatic system for analyzing MEs is still far away from practice. This is because of two main reasons: most of the research in MEs only focuses on the recognition part while abandons the spotting task; current public datasets for ME spotting are not challenging enough to support developing a robust spotting algorithm. Our contributions in this paper are three folds: (1) We introduce an extension of the SMIC-E database, namely SMIC-E-Long database, which is a new challenging benchmark for ME spotting. (2) We suggest a new evaluation protocol that standardizes the comparison of various ME spotting techniques. (3) Extensive experiments with handcrafted and deep learning-based approaches on the SMIC-E-Long database are performed for baseline evaluation.