 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRPO: Perception-Reinforced Policy Optimization via Token-Level Dynamic Advantage Reshaping
Jun 07, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become an effective paradigm for improving the reasoning capability of Large Vision-Language Models (LVLMs). However, existing RLVR methods primarily rely on trajectory-level outcome rewards, which assign identical learning signals across all generated tokens. This coarse-grained credit assignment is fundamentally mismatched to multimodal reasoning, where only a sparse subset of tokens is causally grounded in visual evidence. Consequently, these pivotal perceptual tokens receive weak supervision and are often overwhelmed by language priors or reasoning-template tokens. To address this limitation, we propose Perception-Reinforced Policy Optimization (PRPO), a token-level reinforcement learning framework that explicitly identifies and reinforces pivotal perceptual tokens within long-horizon multimodal reasoning trajectories. PRPO introduces Robust Visual Dependency (RVD), a principled metric that identifies tokens whose predictions are both visually grounded and perturbation-stable, filtering out brittle or noisy visual tokens. Based on RVD, we further propose Perceptual Advantage Reshaping (PAR), a token-level credit assignment technique that amplifies perceptually informative tokens while preserving stable gradients for non-perceptual tokens. Extensive experiments on seven multimodal reasoning benchmarks demonstrate that PRPO consistently outperforms strong LVLM baselines across both 3B and 7B model scales, achieving average gains of 23.3% and 21.1%, respectively. PRPO achieves state-of-the-art performance with improved training efficiency and stronger cross-task generalization. Our findings highlight the importance of fine-grained credit assignment for scalable multimodal reinforcement learning.
ABot-OCR Technical Report
May 27, 2026We introduce ABot-OCR, an end-to-end vision-language model that transcribes a page image directly into clean Markdown in a single forward pass. By doing so, our approach completely eliminates the need for brittle modular orchestration. To maximize parsing fidelity, we develop a dedicated data engine to provide large-scale, structurally consistent supervision. Furthermore, we propose Decoupled Heterogeneous Document Optimization, a structure-constrained reinforcement learning method that sharpens textual accuracy and strictly enforces markup well-formedness beyond supervised fine-tuning alone. Extensive evaluations demonstrate the superior performance of our framework. On the OmniDocBench v1.5 and v1.6 benchmarks, ABot-OCR achieves state-of-the-art scores of 92.81 and 93.30 among all end-to-end systems, substantially narrowing the performance gap relative to strong pipeline baselines. Finally, comprehensive multilingual text recognition across ten diverse languages further confirms the robust generalizability of ABot-OCR.
PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System
Jun 07, 2022

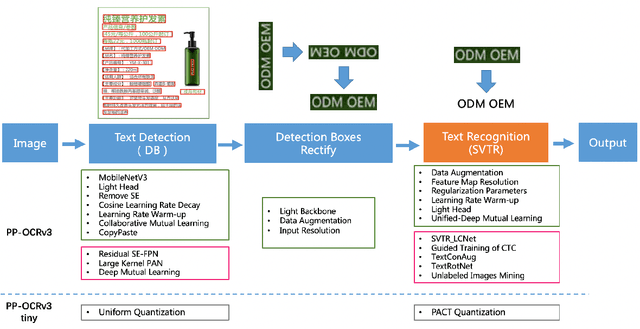
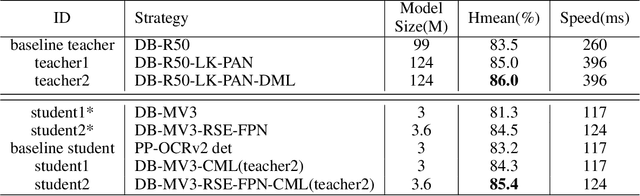
Optical character recognition (OCR) technology has been widely used in various scenes, as shown in Figure 1. Designing a practical OCR system is still a meaningful but challenging task. In previous work, considering the efficiency and accuracy, we proposed a practical ultra lightweight OCR system (PP-OCR), and an optimized version PP-OCRv2. In order to further improve the performance of PP-OCRv2, a more robust OCR system PP-OCRv3 is proposed in this paper. PP-OCRv3 upgrades the text detection model and text recognition model in 9 aspects based on PP-OCRv2. For text detector, we introduce a PAN module with large receptive field named LK-PAN, a FPN module with residual attention mechanism named RSE-FPN, and DML distillation strategy. For text recognizer, the base model is replaced from CRNN to SVTR, and we introduce lightweight text recognition network SVTR LCNet, guided training of CTC by attention, data augmentation strategy TextConAug, better pre-trained model by self-supervised TextRotNet, UDML, and UIM to accelerate the model and improve the effect. Experiments on real data show that the hmean of PP-OCRv3 is 5% higher than PP-OCRv2 under comparable inference speed. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.
Anomaly Detection via Self-organizing Map
Jul 21, 2021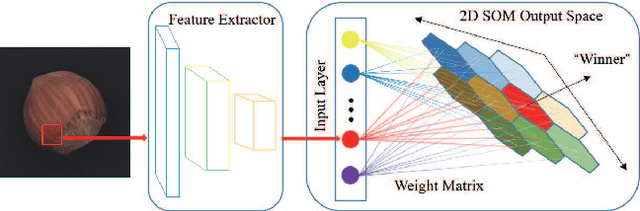
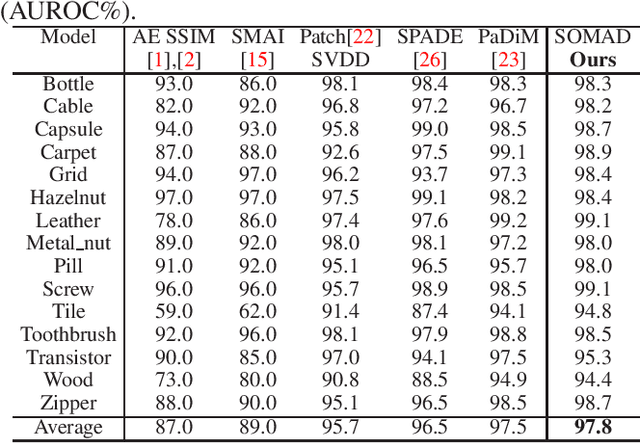
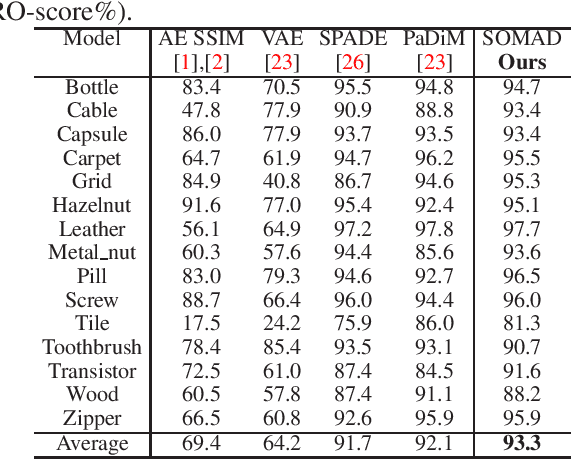
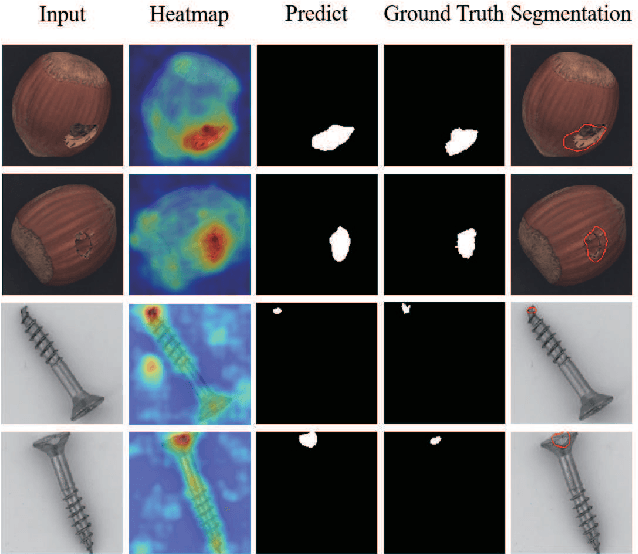
Anomaly detection plays a key role in industrial manufacturing for product quality control. Traditional methods for anomaly detection are rule-based with limited generalization ability. Recent methods based on supervised deep learning are more powerful but require large-scale annotated datasets for training. In practice, abnormal products are rare thus it is very difficult to train a deep model in a fully supervised way. In this paper, we propose a novel unsupervised anomaly detection approach based on Self-organizing Map (SOM). Our method, Self-organizing Map for Anomaly Detection (SOMAD) maintains normal characteristics by using topological memory based on multi-scale features. SOMAD achieves state-of the-art performance on unsupervised anomaly detection and localization on the MVTec dataset.