 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLPAct: A Benchmark for Compositional Generalization on Multimodal Human Activities
Oct 11, 2022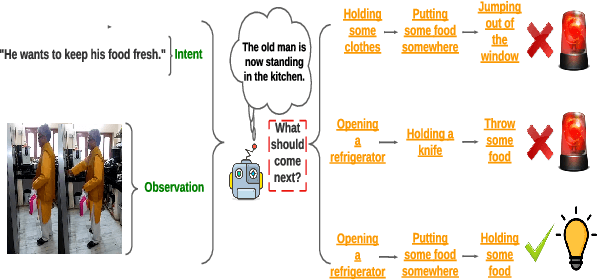
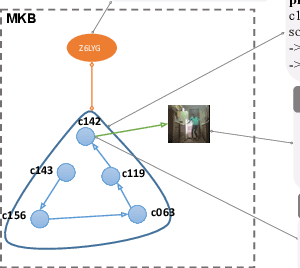

We introduce ViLPAct, a novel vision-language benchmark for human activity planning. It is designed for a task where embodied AI agents can reason and forecast future actions of humans based on video clips about their initial activities and intents in text. The dataset consists of 2.9k videos from \charades extended with intents via crowdsourcing, a multi-choice question test set, and four strong baselines. One of the baselines implements a neurosymbolic approach based on a multi-modal knowledge base (MKB), while the other ones are deep generative models adapted from recent state-of-the-art (SOTA) methods. According to our extensive experiments, the key challenges are compositional generalization and effective use of information from both modalities.
Prompt-driven efficient Open-set Semi-supervised Learning
Sep 28, 2022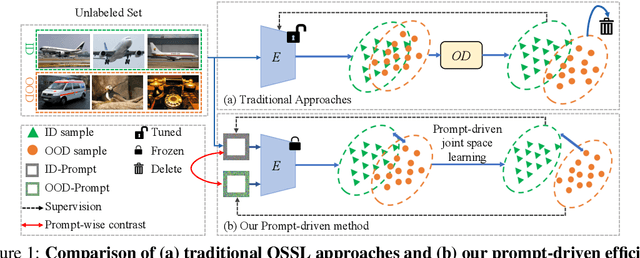
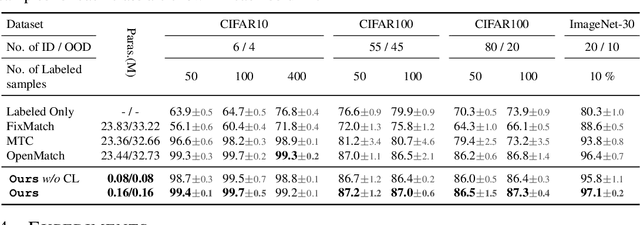
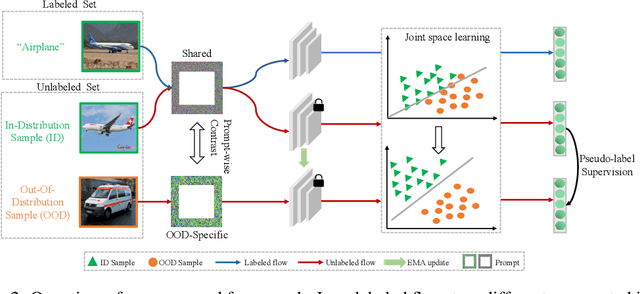
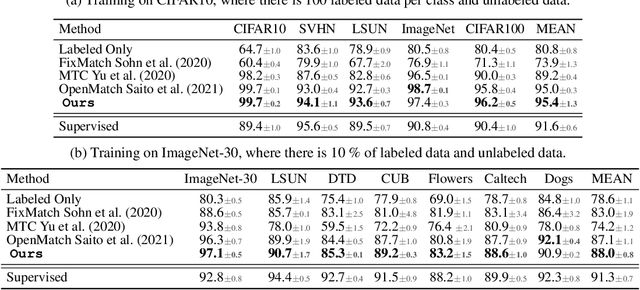
Open-set semi-supervised learning (OSSL) has attracted growing interest, which investigates a more practical scenario where out-of-distribution (OOD) samples are only contained in unlabeled data. Existing OSSL methods like OpenMatch learn an OOD detector to identify outliers, which often update all modal parameters (i.e., full fine-tuning) to propagate class information from labeled data to unlabeled ones. Currently, prompt learning has been developed to bridge gaps between pre-training and fine-tuning, which shows higher computational efficiency in several downstream tasks. In this paper, we propose a prompt-driven efficient OSSL framework, called OpenPrompt, which can propagate class information from labeled to unlabeled data with only a small number of trainable parameters. We propose a prompt-driven joint space learning mechanism to detect OOD data by maximizing the distribution gap between ID and OOD samples in unlabeled data, thereby our method enables the outliers to be detected in a new way. The experimental results on three public datasets show that OpenPrompt outperforms state-of-the-art methods with less than 1% of trainable parameters. More importantly, OpenPrompt achieves a 4% improvement in terms of AUROC on outlier detection over a fully supervised model on CIFAR10.
An Efficient Spatio-Temporal Pyramid Transformer for Action Detection
Jul 21, 2022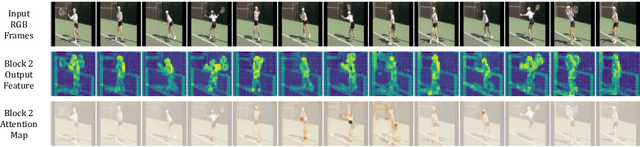

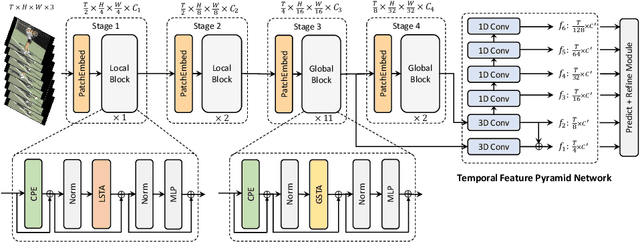
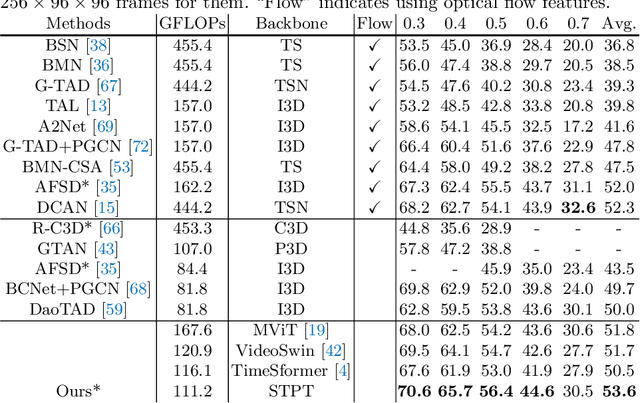
The task of action detection aims at deducing both the action category and localization of the start and end moment for each action instance in a long, untrimmed video. While vision Transformers have driven the recent advances in video understanding, it is non-trivial to design an efficient architecture for action detection due to the prohibitively expensive self-attentions over a long sequence of video clips. To this end, we present an efficient hierarchical Spatio-Temporal Pyramid Transformer (STPT) for action detection, building upon the fact that the early self-attention layers in Transformers still focus on local patterns. Specifically, we propose to use local window attention to encode rich local spatio-temporal representations in the early stages while applying global attention modules to capture long-term space-time dependencies in the later stages. In this way, our STPT can encode both locality and dependency with largely reduced redundancy, delivering a promising trade-off between accuracy and efficiency. For example, with only RGB input, the proposed STPT achieves 53.6% mAP on THUMOS14, surpassing I3D+AFSD RGB model by over 10% and performing favorably against state-of-the-art AFSD that uses additional flow features with 31% fewer GFLOPs, which serves as an effective and efficient end-to-end Transformer-based framework for action detection.
Generalizable Memory-driven Transformer for Multivariate Long Sequence Time-series Forecasting
Jul 16, 2022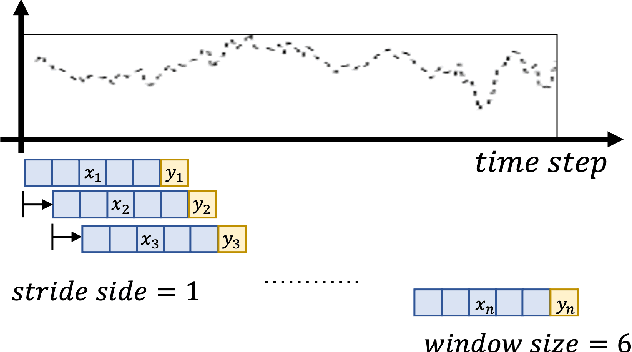
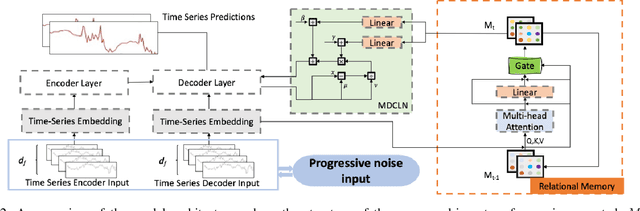
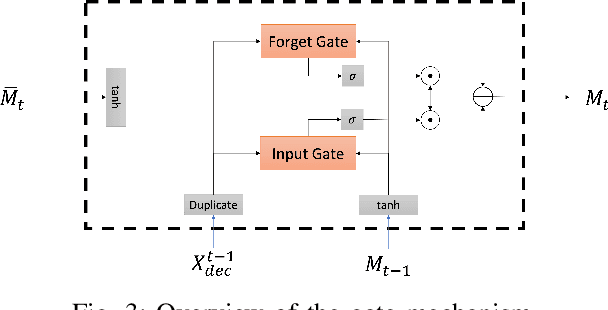
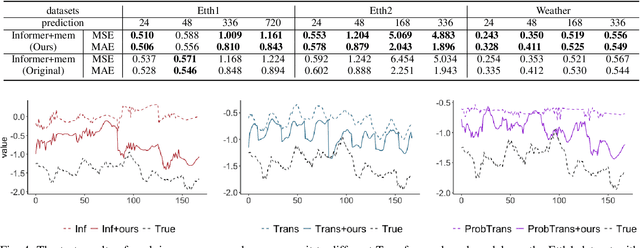
Multivariate long sequence time-series forecasting (M-LSTF) is a practical but challenging problem. Unlike traditional timer-series forecasting tasks, M-LSTF tasks are more challenging from two aspects: 1) M-LSTF models need to learn time-series patterns both within and between multiple time features; 2) Under the rolling forecasting setting, the similarity between two consecutive training samples increases with the increasing prediction length, which makes models more prone to overfitting. In this paper, we propose a generalizable memory-driven Transformer to target M-LSTF problems. Specifically, we first propose a global-level memory component to drive the forecasting procedure by integrating multiple time-series features. In addition, we adopt a progressive fashion to train our model to increase its generalizability, in which we gradually introduce Bernoulli noises to training samples. Extensive experiments have been performed on five different datasets across multiple fields. Experimental results demonstrate that our approach can be seamlessly plugged into varying Transformer-based models to improve their performances up to roughly 30%. Particularly, this is the first work to specifically focus on the M-LSTF tasks to the best of our knowledge.
Domain Adaptive Nuclei Instance Segmentation and Classification via Category-aware Feature Alignment and Pseudo-labelling
Jul 04, 2022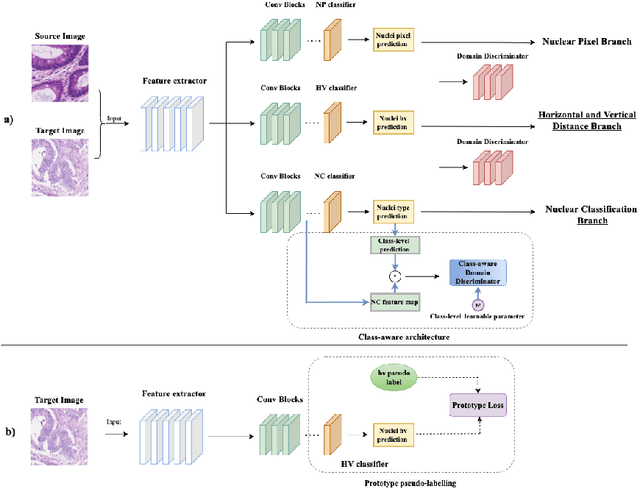
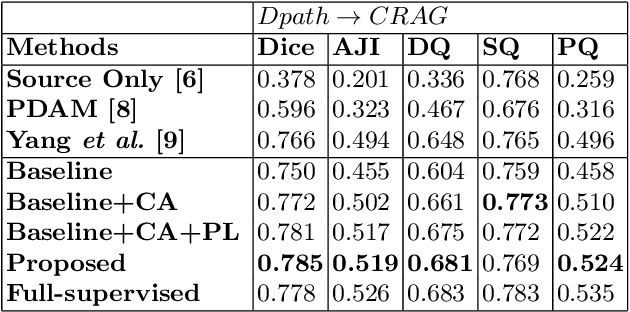
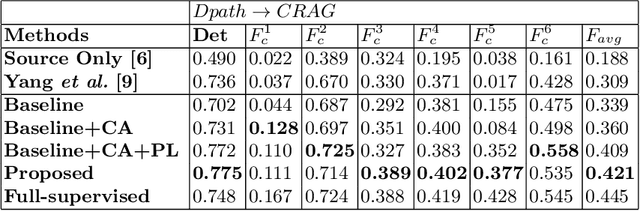
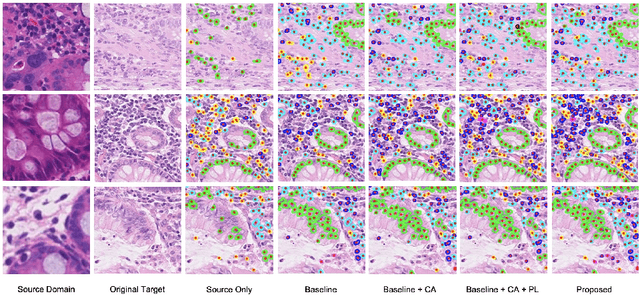
Unsupervised domain adaptation (UDA) methods have been broadly utilized to improve the models' adaptation ability in general computer vision. However, different from the natural images, there exist huge semantic gaps for the nuclei from different categories in histopathology images. It is still under-explored how could we build generalized UDA models for precise segmentation or classification of nuclei instances across different datasets. In this work, we propose a novel deep neural network, namely Category-Aware feature alignment and Pseudo-Labelling Network (CAPL-Net) for UDA nuclei instance segmentation and classification. Specifically, we first propose a category-level feature alignment module with dynamic learnable trade-off weights. Second, we propose to facilitate the model performance on the target data via self-supervised training with pseudo labels based on nuclei-level prototype features. Comprehensive experiments on cross-domain nuclei instance segmentation and classification tasks demonstrate that our approach outperforms state-of-the-art UDA methods with a remarkable margin.
Cross-modal Clinical Graph Transformer for Ophthalmic Report Generation
Jun 04, 2022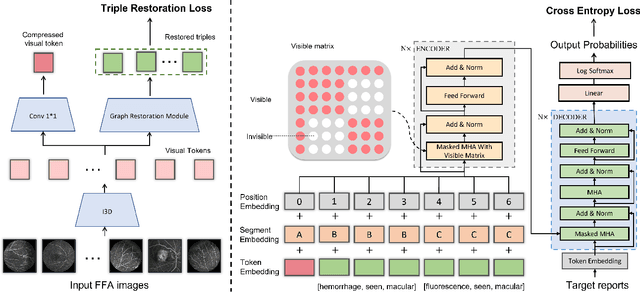

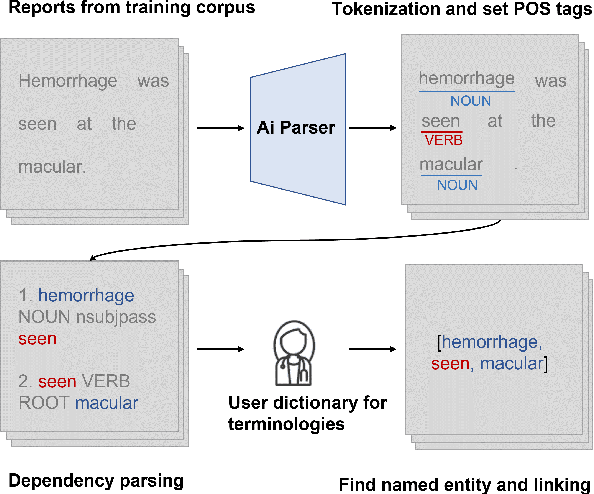
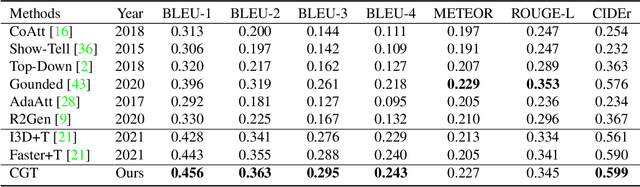
Automatic generation of ophthalmic reports using data-driven neural networks has great potential in clinical practice. When writing a report, ophthalmologists make inferences with prior clinical knowledge. This knowledge has been neglected in prior medical report generation methods. To endow models with the capability of incorporating expert knowledge, we propose a Cross-modal clinical Graph Transformer (CGT) for ophthalmic report generation (ORG), in which clinical relation triples are injected into the visual features as prior knowledge to drive the decoding procedure. However, two major common Knowledge Noise (KN) issues may affect models' effectiveness. 1) Existing general biomedical knowledge bases such as the UMLS may not align meaningfully to the specific context and language of the report, limiting their utility for knowledge injection. 2) Incorporating too much knowledge may divert the visual features from their correct meaning. To overcome these limitations, we design an automatic information extraction scheme based on natural language processing to obtain clinical entities and relations directly from in-domain training reports. Given a set of ophthalmic images, our CGT first restores a sub-graph from the clinical graph and injects the restored triples into visual features. Then visible matrix is employed during the encoding procedure to limit the impact of knowledge. Finally, reports are predicted by the encoded cross-modal features via a Transformer decoder. Extensive experiments on the large-scale FFA-IR benchmark demonstrate that the proposed CGT is able to outperform previous benchmark methods and achieve state-of-the-art performances.
Knowledge Distillation via the Target-aware Transformer
May 22, 2022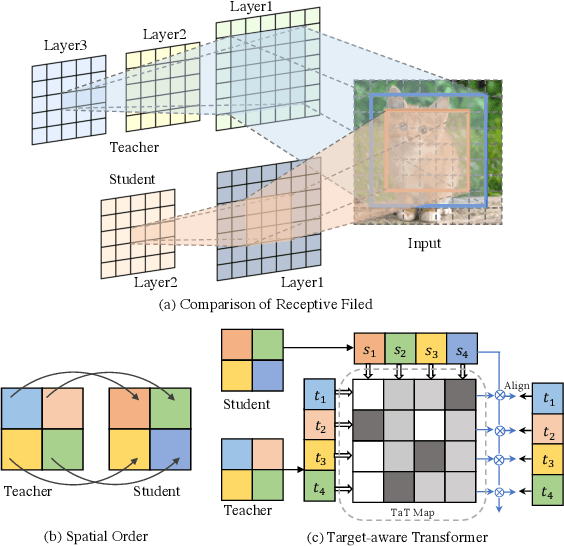
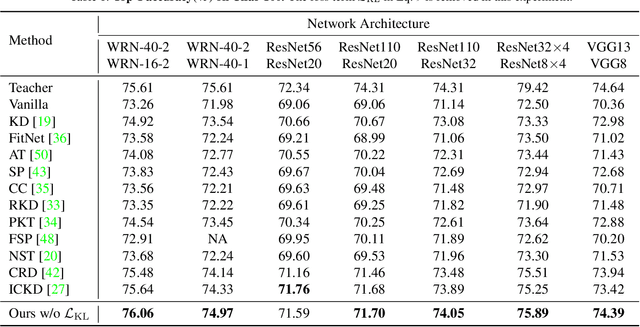
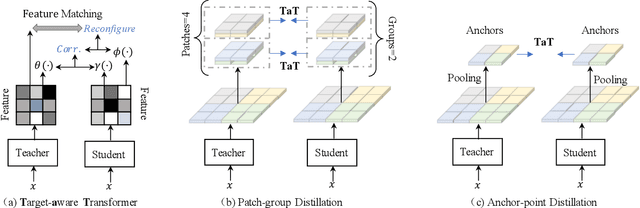

Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code will be released soon.
Towards Explanation for Unsupervised Graph-Level Representation Learning
May 20, 2022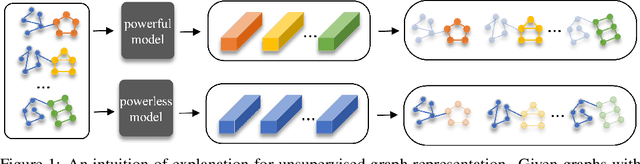

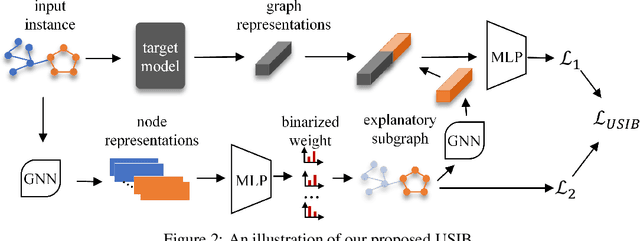
Due to the superior performance of Graph Neural Networks (GNNs) in various domains, there is an increasing interest in the GNN explanation problem "\emph{which fraction of the input graph is the most crucial to decide the model's decision?}" Existing explanation methods focus on the supervised settings, \eg, node classification and graph classification, while the explanation for unsupervised graph-level representation learning is still unexplored. The opaqueness of the graph representations may lead to unexpected risks when deployed for high-stake decision-making scenarios. In this paper, we advance the Information Bottleneck principle (IB) to tackle the proposed explanation problem for unsupervised graph representations, which leads to a novel principle, \textit{Unsupervised Subgraph Information Bottleneck} (USIB). We also theoretically analyze the connection between graph representations and explanatory subgraphs on the label space, which reveals that the expressiveness and robustness of representations benefit the fidelity of explanatory subgraphs. Experimental results on both synthetic and real-world datasets demonstrate the superiority of our developed explainer and the validity of our theoretical analysis.
PRE-NAS: Predictor-assisted Evolutionary Neural Architecture Search
Apr 27, 2022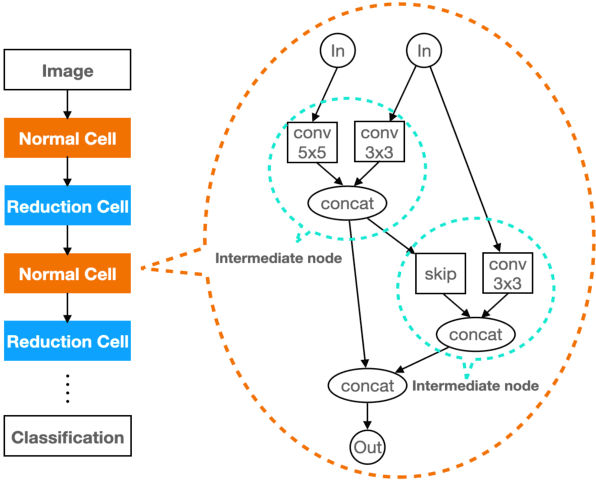
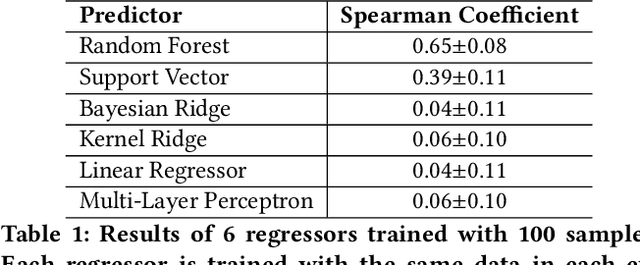
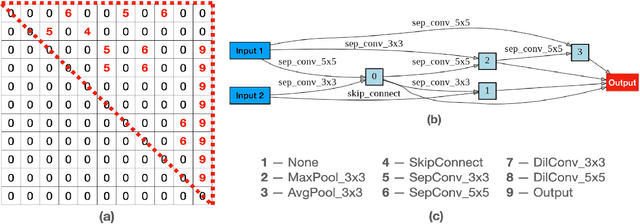
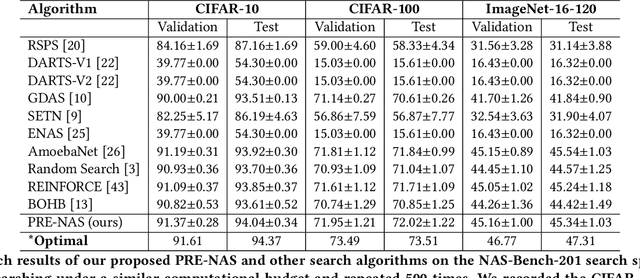
Neural architecture search (NAS) aims to automate architecture engineering in neural networks. This often requires a high computational overhead to evaluate a number of candidate networks from the set of all possible networks in the search space during the search. Prediction of the networks' performance can alleviate this high computational overhead by mitigating the need for evaluating every candidate network. Developing such a predictor typically requires a large number of evaluated architectures which may be difficult to obtain. We address this challenge by proposing a novel evolutionary-based NAS strategy, Predictor-assisted E-NAS (PRE-NAS), which can perform well even with an extremely small number of evaluated architectures. PRE-NAS leverages new evolutionary search strategies and integrates high-fidelity weight inheritance over generations. Unlike one-shot strategies, which may suffer from bias in the evaluation due to weight sharing, offspring candidates in PRE-NAS are topologically homogeneous, which circumvents bias and leads to more accurate predictions. Extensive experiments on NAS-Bench-201 and DARTS search spaces show that PRE-NAS can outperform state-of-the-art NAS methods. With only a single GPU searching for 0.6 days, competitive architecture can be found by PRE-NAS which achieves 2.40% and 24% test error rates on CIFAR-10 and ImageNet respectively.
Beyond Fixation: Dynamic Window Visual Transformer
Apr 08, 2022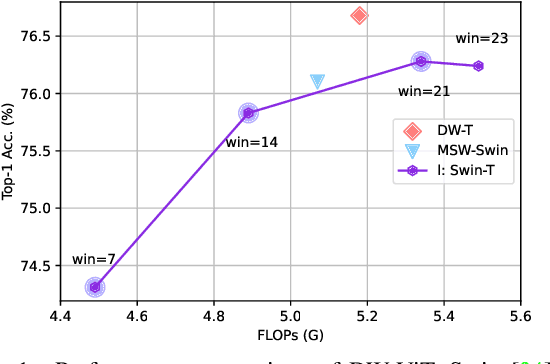
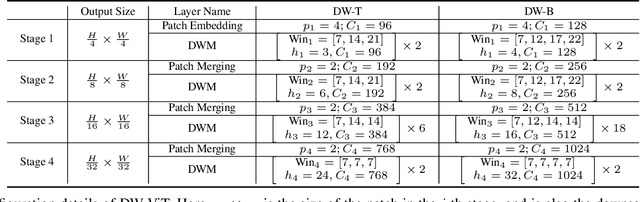
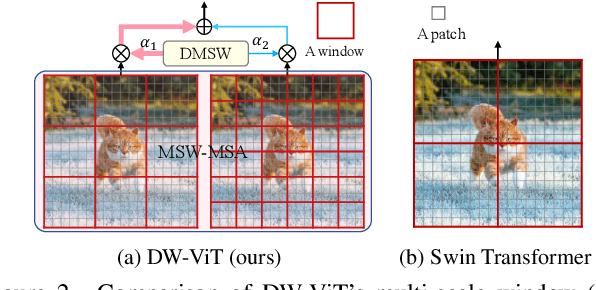
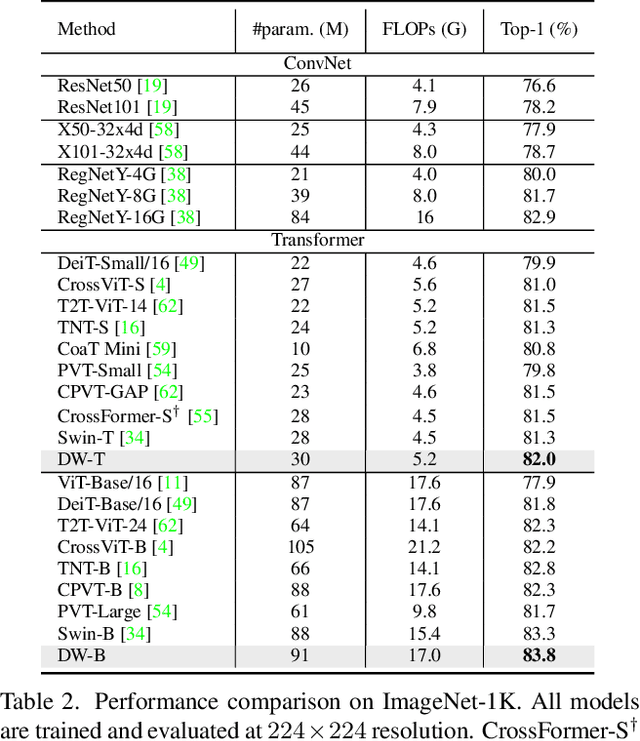
Recently, a surge of interest in visual transformers is to reduce the computational cost by limiting the calculation of self-attention to a local window. Most current work uses a fixed single-scale window for modeling by default, ignoring the impact of window size on model performance. However, this may limit the modeling potential of these window-based models for multi-scale information. In this paper, we propose a novel method, named Dynamic Window Vision Transformer (DW-ViT). The dynamic window strategy proposed by DW-ViT goes beyond the model that employs a fixed single window setting. To the best of our knowledge, we are the first to use dynamic multi-scale windows to explore the upper limit of the effect of window settings on model performance. In DW-ViT, multi-scale information is obtained by assigning windows of different sizes to different head groups of window multi-head self-attention. Then, the information is dynamically fused by assigning different weights to the multi-scale window branches. We conducted a detailed performance evaluation on three datasets, ImageNet-1K, ADE20K, and COCO. Compared with related state-of-the-art (SoTA) methods, DW-ViT obtains the best performance. Specifically, compared with the current SoTA Swin Transformers \cite{liu2021swin}, DW-ViT has achieved consistent and substantial improvements on all three datasets with similar parameters and computational costs. In addition, DW-ViT exhibits good scalability and can be easily inserted into any window-based visual transformers.