 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Perceiving Video-Language Pre-training
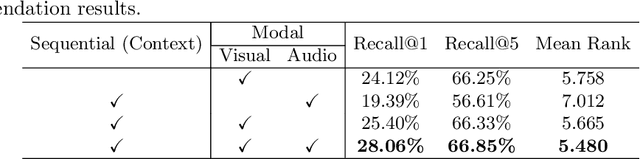
Jan 18, 2023Video-Language Pre-training models have recently significantly improved various multi-modal downstream tasks. Previous dominant works mainly adopt contrastive learning to achieve global feature alignment across modalities. However, the local associations between videos and texts are not modeled, restricting the pre-training models' generality, especially for tasks requiring the temporal video boundary for certain query texts. This work introduces a novel text-video localization pre-text task to enable fine-grained temporal and semantic alignment such that the trained model can accurately perceive temporal boundaries in videos given the text description. Specifically, text-video localization consists of moment retrieval, which predicts start and end boundaries in videos given the text description, and text localization which matches the subset of texts with the video features. To produce temporal boundaries, frame features in several videos are manually merged into a long video sequence that interacts with a text sequence. With the localization task, our method connects the fine-grained frame representations with the word representations and implicitly distinguishes representations of different instances in the single modality. Notably, comprehensive experimental results show that our method significantly improves the state-of-the-art performance on various benchmarks, covering text-to-video retrieval, video question answering, video captioning, temporal action localization and temporal moment retrieval. The code will be released soon.
CMAE-V: Contrastive Masked Autoencoders for Video Action Recognition
Jan 15, 2023


Contrastive Masked Autoencoder (CMAE), as a new self-supervised framework, has shown its potential of learning expressive feature representations in visual image recognition. This work shows that CMAE also trivially generalizes well on video action recognition without modifying the architecture and the loss criterion. By directly replacing the original pixel shift with the temporal shift, our CMAE for visual action recognition, CMAE-V for short, can generate stronger feature representations than its counterpart based on pure masked autoencoders. Notably, CMAE-V, with a hybrid architecture, can achieve 82.2% and 71.6% top-1 accuracy on the Kinetics-400 and Something-something V2 datasets, respectively. We hope this report could provide some informative inspiration for future works.
Revisiting Training-free NAS Metrics: An Efficient Training-based Method
Nov 16, 2022Recent neural architecture search (NAS) works proposed training-free metrics to rank networks which largely reduced the search cost in NAS. In this paper, we revisit these training-free metrics and find that: (1) the number of parameters (\#Param), which is the most straightforward training-free metric, is overlooked in previous works but is surprisingly effective, (2) recent training-free metrics largely rely on the \#Param information to rank networks. Our experiments show that the performance of recent training-free metrics drops dramatically when the \#Param information is not available. Motivated by these observations, we argue that metrics less correlated with the \#Param are desired to provide additional information for NAS. We propose a light-weight training-based metric which has a weak correlation with the \#Param while achieving better performance than training-free metrics at a lower search cost. Specifically, on DARTS search space, our method completes searching directly on ImageNet in only 2.6 GPU hours and achieves a top-1/top-5 error rate of 24.1\%/7.1\%, which is competitive among state-of-the-art NAS methods. Codes are available at \url{https://github.com/taoyang1122/Revisit_TrainingFree_NAS}
NoiSER: Noise is All You Need for Enhancing Low-Light Images Without Task-Related Data
Nov 09, 2022



This paper is about an extraordinary phenomenon. Suppose we don't use any low-light images as training data, can we enhance a low-light image by deep learning? Obviously, current methods cannot do this, since deep neural networks require to train their scads of parameters using copious amounts of training data, especially task-related data. In this paper, we show that in the context of fundamental deep learning, it is possible to enhance a low-light image without any task-related training data. Technically, we propose a new, magical, effective and efficient method, termed \underline{Noi}se \underline{SE}lf-\underline{R}egression (NoiSER), which learns a gray-world mapping from Gaussian distribution for low-light image enhancement (LLIE). Specifically, a self-regression model is built as a carrier to learn a gray-world mapping during training, which is performed by simply iteratively feeding random noise. During inference, a low-light image is directly fed into the learned mapping to yield a normal-light one. Extensive experiments show that our NoiSER is highly competitive to current task-related data based LLIE models in terms of quantitative and visual results, while outperforming them in terms of the number of parameters, training time and inference speed. With only about 1K parameters, NoiSER realizes about 1 minute for training and 1.2 ms for inference with 600$\times$400 resolution on RTX 2080 Ti. Besides, NoiSER has an inborn automated exposure suppression capability and can automatically adjust too bright or too dark, without additional manipulations.
OSIC: A New One-Stage Image Captioner Coined
Nov 04, 2022Mainstream image caption models are usually two-stage captioners, i.e., calculating object features by pre-trained detector, and feeding them into a language model to generate text descriptions. However, such an operation will cause a task-based information gap to decrease the performance, since the object features in detection task are suboptimal representation and cannot provide all necessary information for subsequent text generation. Besides, object features are usually represented by the last layer features that lose the local details of input images. In this paper, we propose a novel One-Stage Image Captioner (OSIC) with dynamic multi-sight learning, which directly transforms input image into descriptive sentences in one stage. As a result, the task-based information gap can be greatly reduced. To obtain rich features, we use the Swin Transformer to calculate multi-level features, and then feed them into a novel dynamic multi-sight embedding module to exploit both global structure and local texture of input images. To enhance the global modeling of encoder for caption, we propose a new dual-dimensional refining module to non-locally model the interaction of the embedded features. Finally, OSIC can obtain rich and useful information to improve the image caption task. Extensive comparisons on benchmark MS-COCO dataset verified the superior performance of our method.
Global Prototype Encoding for Incremental Video Highlights Detection
Sep 14, 2022

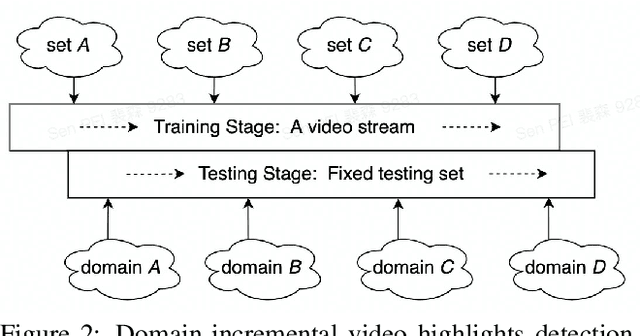
Video highlights detection has been long researched as a topic in computer vision tasks, digging the user-appealing clips out given unexposed raw video inputs. However, in most case, the mainstream methods in this line of research are built on the closed world assumption, where a fixed number of highlight categories is defined properly in advance and need all training data to be available at the same time, and as a result, leads to poor scalability with respect to both the highlight categories and the size of the dataset. To tackle the problem mentioned above, we propose a video highlights detector that is able to learn incrementally, namely \textbf{G}lobal \textbf{P}rototype \textbf{E}ncoding (GPE), capturing newly defined video highlights in the extended dataset via their corresponding prototypes. Alongside, we present a well annotated and costly dataset termed \emph{ByteFood}, including more than 5.1k gourmet videos belongs to four different domains which are \emph{cooking}, \emph{eating}, \emph{food material}, and \emph{presentation} respectively. To the best of our knowledge, this is the first time the incremental learning settings are introduced to video highlights detection, which in turn relieves the burden of training video inputs and promotes the scalability of conventional neural networks in proportion to both the size of the dataset and the quantity of domains. Moreover, the proposed GPE surpasses current incremental learning methods on \emph{ByteFood}, reporting an improvement of 1.57\% mAP at least. The code and dataset will be made available sooner.
Contrastive Masked Autoencoders are Stronger Vision Learners
Jul 27, 2022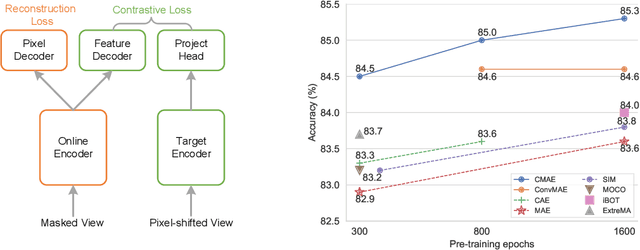

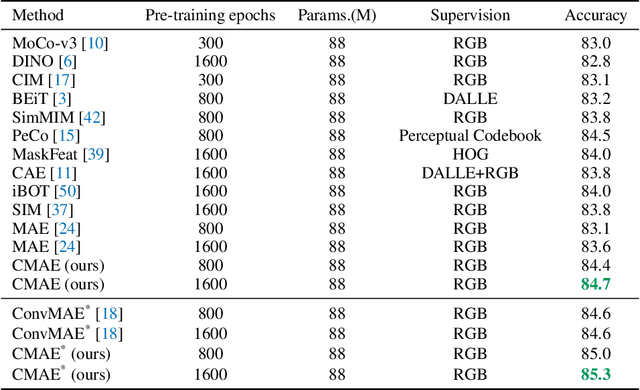
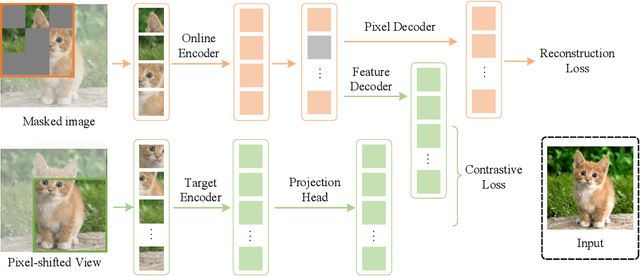
Masked image modeling (MIM) has achieved promising results on various vision tasks. However, the limited discriminability of learned representation manifests there is still plenty to go for making a stronger vision learner. Towards this goal, we propose Contrastive Masked Autoencoders (CMAE), a new self-supervised pre-training method for learning more comprehensive and capable vision representations. By elaboratively unifying contrastive learning (CL) and masked image model (MIM) through novel designs, CMAE leverages their respective advantages and learns representations with both strong instance discriminability and local perceptibility. Specifically, CMAE consists of two branches where the online branch is an asymmetric encoder-decoder and the target branch is a momentum updated encoder. During training, the online encoder reconstructs original images from latent representations of masked images to learn holistic features. The target encoder, fed with the full images, enhances the feature discriminability via contrastive learning with its online counterpart. To make CL compatible with MIM, CMAE introduces two new components, i.e. pixel shift for generating plausible positive views and feature decoder for complementing features of contrastive pairs. Thanks to these novel designs, CMAE effectively improves the representation quality and transfer performance over its MIM counterpart. CMAE achieves the state-of-the-art performance on highly competitive benchmarks of image classification, semantic segmentation and object detection. Notably, CMAE-Base achieves $85.3\%$ top-1 accuracy on ImageNet and $52.5\%$ mIoU on ADE20k, surpassing previous best results by $0.7\%$ and $1.8\%$ respectively. Codes will be made publicly available.
AutoTransition: Learning to Recommend Video Transition Effects
Jul 27, 2022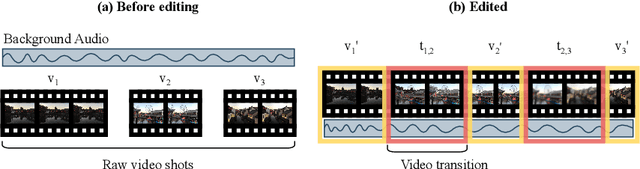
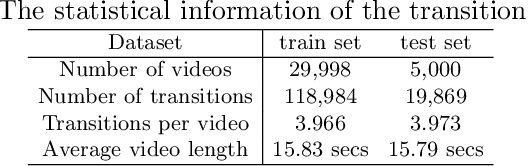
Video transition effects are widely used in video editing to connect shots for creating cohesive and visually appealing videos. However, it is challenging for non-professionals to choose best transitions due to the lack of cinematographic knowledge and design skills. In this paper, we present the premier work on performing automatic video transitions recommendation (VTR): given a sequence of raw video shots and companion audio, recommend video transitions for each pair of neighboring shots. To solve this task, we collect a large-scale video transition dataset using publicly available video templates on editing softwares. Then we formulate VTR as a multi-modal retrieval problem from vision/audio to video transitions and propose a novel multi-modal matching framework which consists of two parts. First we learn the embedding of video transitions through a video transition classification task. Then we propose a model to learn the matching correspondence from vision/audio inputs to video transitions. Specifically, the proposed model employs a multi-modal transformer to fuse vision and audio information, as well as capture the context cues in sequential transition outputs. Through both quantitative and qualitative experiments, we clearly demonstrate the effectiveness of our method. Notably, in the comprehensive user study, our method receives comparable scores compared with professional editors while improving the video editing efficiency by \textbf{300\scalebox{1.25}{$\times$}}. We hope our work serves to inspire other researchers to work on this new task. The dataset and codes are public at \url{https://github.com/acherstyx/AutoTransition}.
Video Salient Object Detection via Contrastive Features and Attention Modules
Nov 03, 2021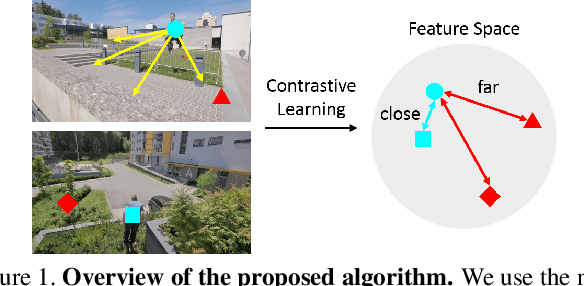
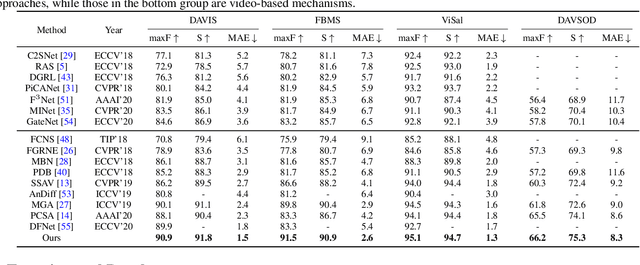
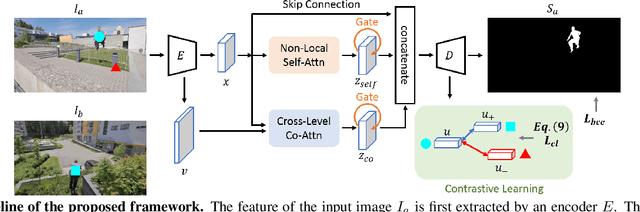
Video salient object detection aims to find the most visually distinctive objects in a video. To explore the temporal dependencies, existing methods usually resort to recurrent neural networks or optical flow. However, these approaches require high computational cost, and tend to accumulate inaccuracies over time. In this paper, we propose a network with attention modules to learn contrastive features for video salient object detection without the high computational temporal modeling techniques. We develop a non-local self-attention scheme to capture the global information in the video frame. A co-attention formulation is utilized to combine the low-level and high-level features. We further apply the contrastive learning to improve the feature representations, where foreground region pairs from the same video are pulled together, and foreground-background region pairs are pushed away in the latent space. The intra-frame contrastive loss helps separate the foreground and background features, and the inter-frame contrastive loss improves the temporal consistency. We conduct extensive experiments on several benchmark datasets for video salient object detection and unsupervised video object segmentation, and show that the proposed method requires less computation, and performs favorably against the state-of-the-art approaches.
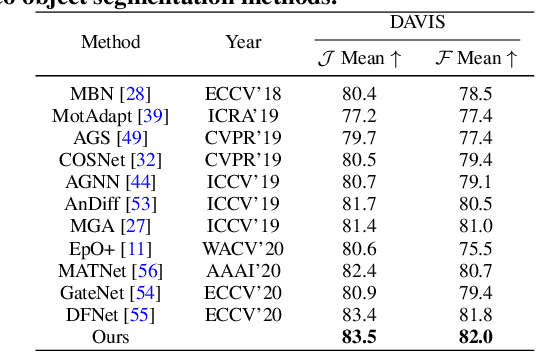
Conflict-Averse Gradient Descent for Multi-task Learning
Oct 26, 2021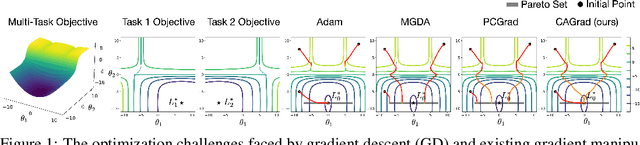
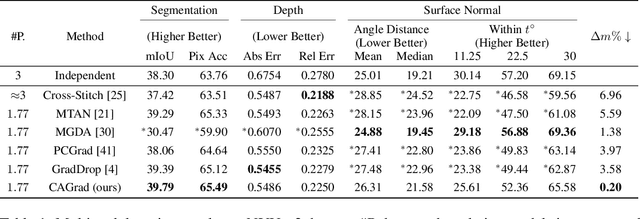
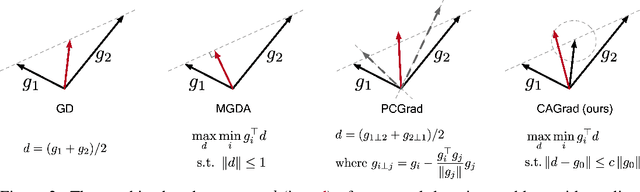
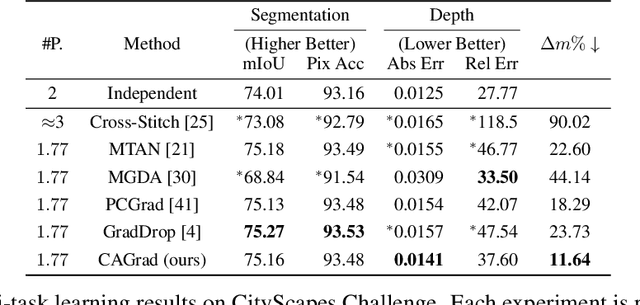
The goal of multi-task learning is to enable more efficient learning than single task learning by sharing model structures for a diverse set of tasks. A standard multi-task learning objective is to minimize the average loss across all tasks. While straightforward, using this objective often results in much worse final performance for each task than learning them independently. A major challenge in optimizing a multi-task model is the conflicting gradients, where gradients of different task objectives are not well aligned so that following the average gradient direction can be detrimental to specific tasks' performance. Previous work has proposed several heuristics to manipulate the task gradients for mitigating this problem. But most of them lack convergence guarantee and/or could converge to any Pareto-stationary point. In this paper, we introduce Conflict-Averse Gradient descent (CAGrad) which minimizes the average loss function, while leveraging the worst local improvement of individual tasks to regularize the algorithm trajectory. CAGrad balances the objectives automatically and still provably converges to a minimum over the average loss. It includes the regular gradient descent (GD) and the multiple gradient descent algorithm (MGDA) in the multi-objective optimization (MOO) literature as special cases. On a series of challenging multi-task supervised learning and reinforcement learning tasks, CAGrad achieves improved performance over prior state-of-the-art multi-objective gradient manipulation methods.