 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-attending Free-form Regions and Detections with Multi-modal Multiplicative Feature Embedding for Visual Question Answering
Dec 12, 2017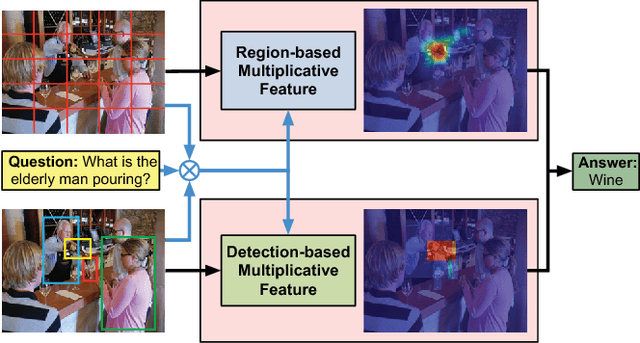
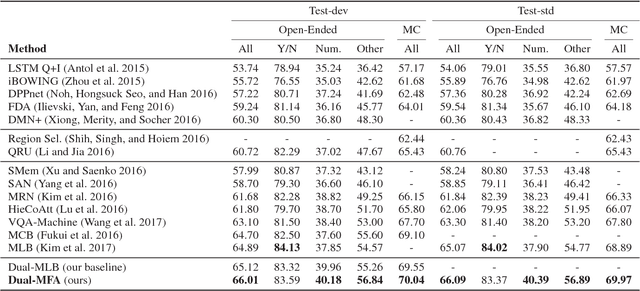
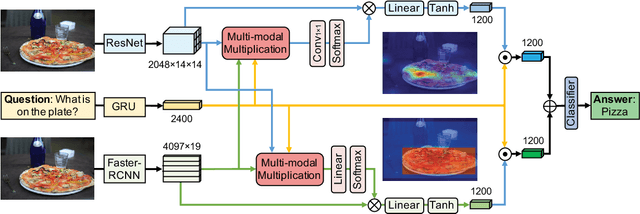
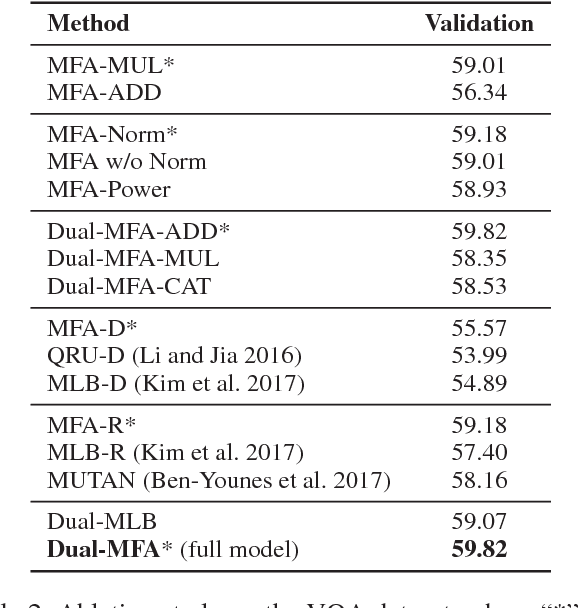
Recently, the Visual Question Answering (VQA) task has gained increasing attention in artificial intelligence. Existing VQA methods mainly adopt the visual attention mechanism to associate the input question with corresponding image regions for effective question answering. The free-form region based and the detection-based visual attention mechanisms are mostly investigated, with the former ones attending free-form image regions and the latter ones attending pre-specified detection-box regions. We argue that the two attention mechanisms are able to provide complementary information and should be effectively integrated to better solve the VQA problem. In this paper, we propose a novel deep neural network for VQA that integrates both attention mechanisms. Our proposed framework effectively fuses features from free-form image regions, detection boxes, and question representations via a multi-modal multiplicative feature embedding scheme to jointly attend question-related free-form image regions and detection boxes for more accurate question answering. The proposed method is extensively evaluated on two publicly available datasets, COCO-QA and VQA, and outperforms state-of-the-art approaches. Source code is available at https://github.com/lupantech/dual-mfa-vqa.
Rethinking Feature Discrimination and Polymerization for Large-scale Recognition
Oct 29, 2017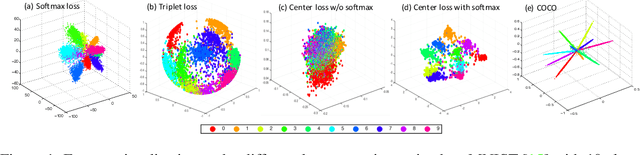
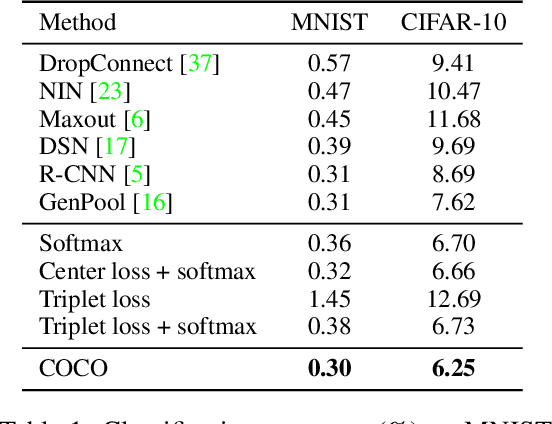
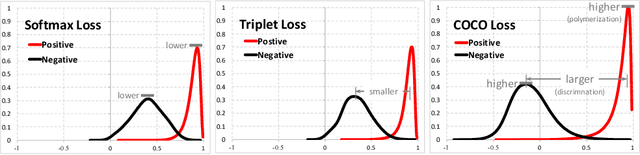

Feature matters. How to train a deep network to acquire discriminative features across categories and polymerized features within classes has always been at the core of many computer vision tasks, specially for large-scale recognition systems where test identities are unseen during training and the number of classes could be at million scale. In this paper, we address this problem based on the simple intuition that the cosine distance of features in high-dimensional space should be close enough within one class and far away across categories. To this end, we proposed the congenerous cosine (COCO) algorithm to simultaneously optimize the cosine similarity among data. It inherits the softmax property to make inter-class features discriminative as well as shares the idea of class centroid in metric learning. Unlike previous work where the center is a temporal, statistical variable within one mini-batch during training, the formulated centroid is responsible for clustering inner-class features to enforce them polymerized around the network truncus. COCO is bundled with discriminative training and learned end-to-end with stable convergence. Experiments on five benchmarks have been extensively conducted to verify the effectiveness of our approach on both small-scale classification task and large-scale human recognition problem.
Spontaneous Symmetry Breaking in Neural Networks
Oct 17, 2017We propose a framework to understand the unprecedented performance and robustness of deep neural networks using field theory. Correlations between the weights within the same layer can be described by symmetries in that layer, and networks generalize better if such symmetries are broken to reduce the redundancies of the weights. Using a two parameter field theory, we find that the network can break such symmetries itself towards the end of training in a process commonly known in physics as spontaneous symmetry breaking. This corresponds to a network generalizing itself without any user input layers to break the symmetry, but by communication with adjacent layers. In the layer decoupling limit applicable to residual networks (He et al., 2015), we show that the remnant symmetries that survive the non-linear layers are spontaneously broken. The Lagrangian for the non-linear and weight layers together has striking similarities with the one in quantum field theory of a scalar. Using results from quantum field theory we show that our framework is able to explain many experimentally observed phenomena,such as training on random labels with zero error (Zhang et al., 2017), the information bottleneck, the phase transition out of it and gradient variance explosion (Shwartz-Ziv & Tishby, 2017), shattered gradients (Balduzzi et al., 2017), and many more.
HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
Sep 28, 2017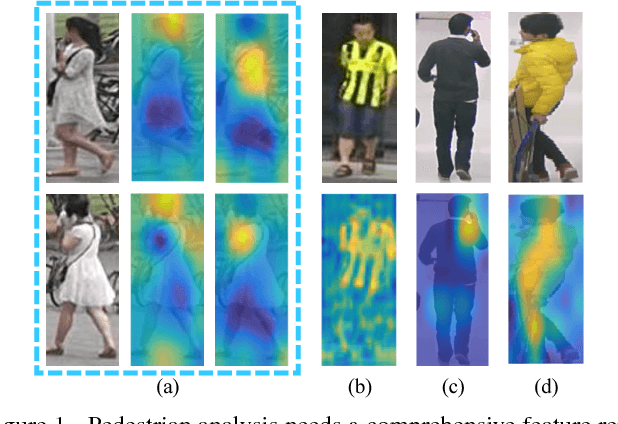
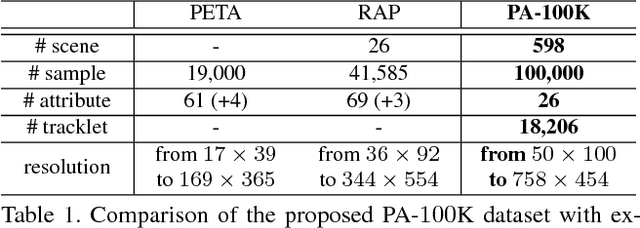
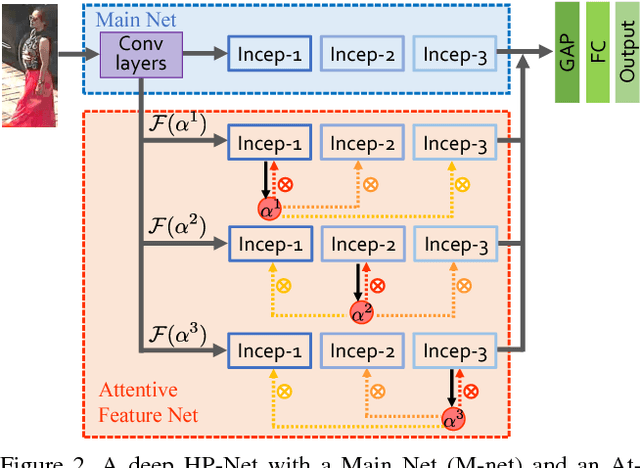

Pedestrian analysis plays a vital role in intelligent video surveillance and is a key component for security-centric computer vision systems. Despite that the convolutional neural networks are remarkable in learning discriminative features from images, the learning of comprehensive features of pedestrians for fine-grained tasks remains an open problem. In this study, we propose a new attention-based deep neural network, named as HydraPlus-Net (HP-net), that multi-directionally feeds the multi-level attention maps to different feature layers. The attentive deep features learned from the proposed HP-net bring unique advantages: (1) the model is capable of capturing multiple attentions from low-level to semantic-level, and (2) it explores the multi-scale selectiveness of attentive features to enrich the final feature representations for a pedestrian image. We demonstrate the effectiveness and generality of the proposed HP-net for pedestrian analysis on two tasks, i.e. pedestrian attribute recognition and person re-identification. Intensive experimental results have been provided to prove that the HP-net outperforms the state-of-the-art methods on various datasets.
Visual Question Generation as Dual Task of Visual Question Answering
Sep 21, 2017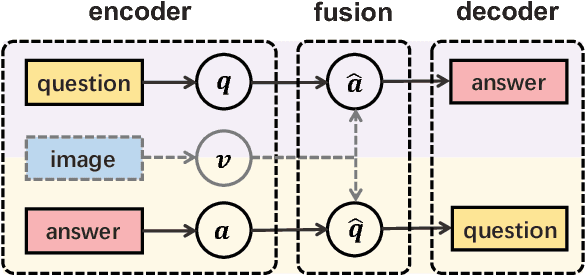
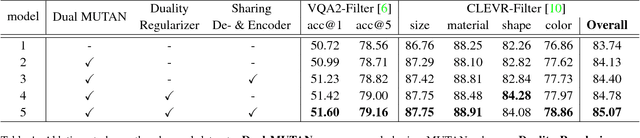
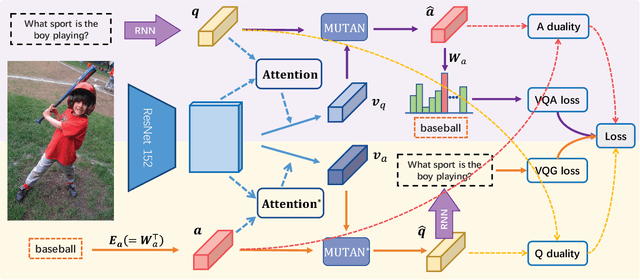
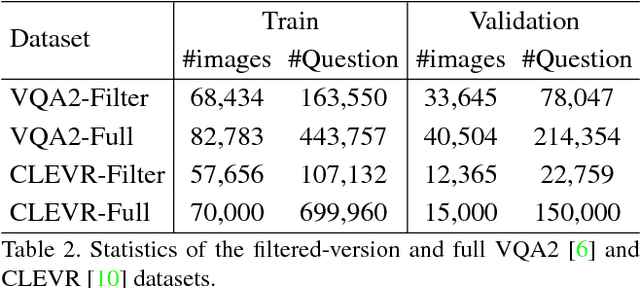
Recently visual question answering (VQA) and visual question generation (VQG) are two trending topics in the computer vision, which have been explored separately. In this work, we propose an end-to-end unified framework, the Invertible Question Answering Network (iQAN), to leverage the complementary relations between questions and answers in images by jointly training the model on VQA and VQG tasks. Corresponding parameter sharing scheme and regular terms are proposed as constraints to explicitly leverage Q,A's dependencies to guide the training process. After training, iQAN can take either question or answer as input, then output the counterpart. Evaluated on the large-scale visual question answering datasets CLEVR and VQA2, our iQAN improves the VQA accuracy over the baselines. We also show the dual learning framework of iQAN can be generalized to other VQA architectures and consistently improve the results over both the VQA and VQG tasks.
Scene Graph Generation from Objects, Phrases and Region Captions
Sep 15, 2017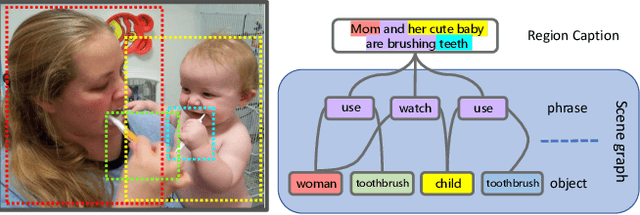
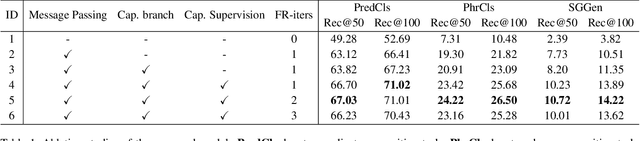
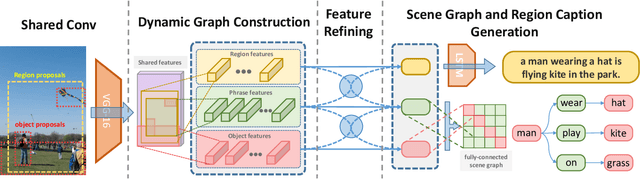
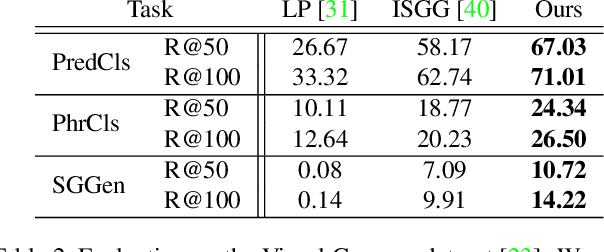
Object detection, scene graph generation and region captioning, which are three scene understanding tasks at different semantic levels, are tied together: scene graphs are generated on top of objects detected in an image with their pairwise relationship predicted, while region captioning gives a language description of the objects, their attributes, relations, and other context information. In this work, to leverage the mutual connections across semantic levels, we propose a novel neural network model, termed as Multi-level Scene Description Network (denoted as MSDN), to solve the three vision tasks jointly in an end-to-end manner. Objects, phrases, and caption regions are first aligned with a dynamic graph based on their spatial and semantic connections. Then a feature refining structure is used to pass messages across the three levels of semantic tasks through the graph. We benchmark the learned model on three tasks, and show the joint learning across three tasks with our proposed method can bring mutual improvements over previous models. Particularly, on the scene graph generation task, our proposed method outperforms the state-of-art method with more than 3% margin.
Optimization assisted MCMC
Sep 09, 2017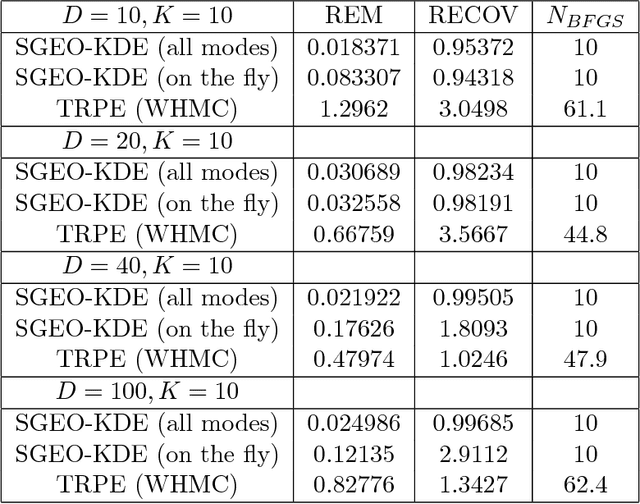
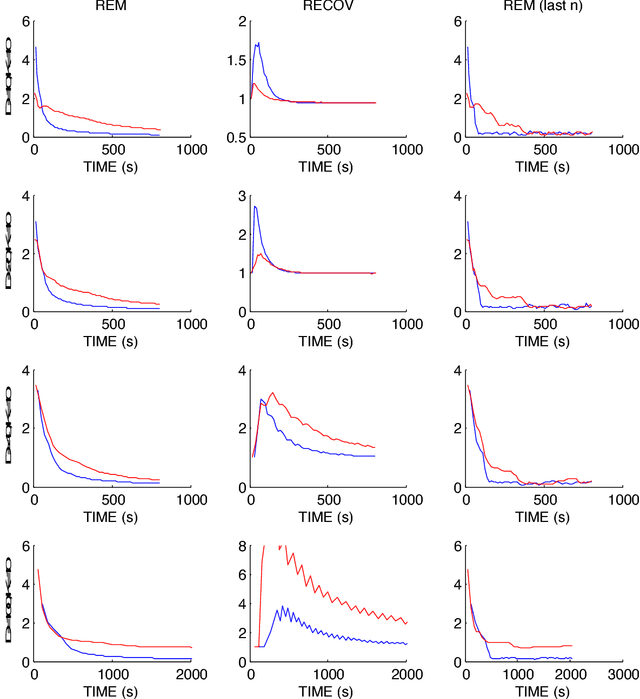
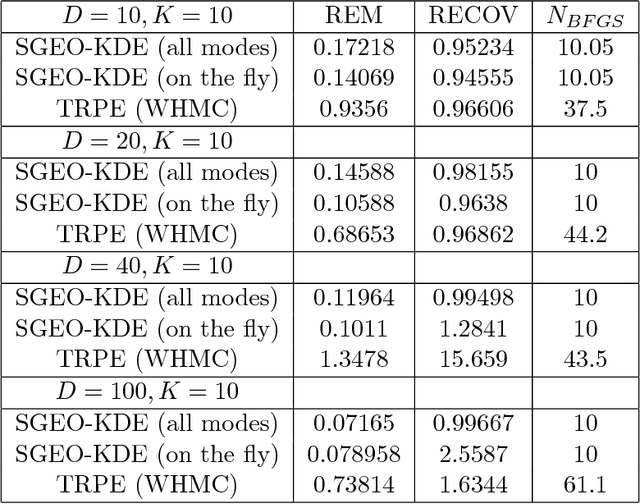
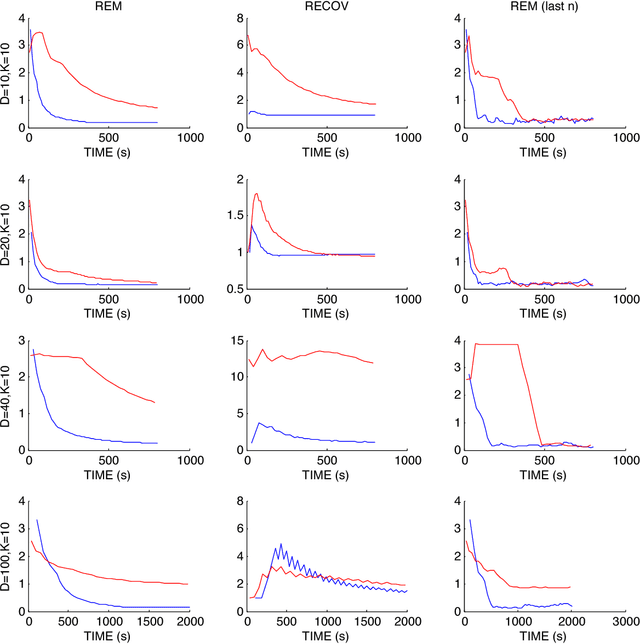
Markov Chain Monte Carlo (MCMC) sampling methods are widely used but often encounter either slow convergence or biased sampling when applied to multimodal high dimensional distributions. In this paper, we present a general framework of improving classical MCMC samplers by employing a global optimization method. The global optimization method first reduces a high dimensional search to an one dimensional geodesic to find a starting point close to a local mode. The search is accelerated and completed by using a local search method such as BFGS. We modify the target distribution by extracting a local Gaussian distribution aound the found mode. The process is repeated to find all the modes during sampling on the fly. We integrate the optimization algorithm into the Wormhole Hamiltonian Monte Carlo (WHMC) method. Experimental results show that, when applied to high dimensional, multimodal Gaussian mixture models and the network sensor localization problem, the proposed method achieves much faster convergence, with relative error from the mean improved by about an order of magnitude than WHMC in some cases.
Online Multi-Object Tracking Using CNN-based Single Object Tracker with Spatial-Temporal Attention Mechanism
Aug 14, 2017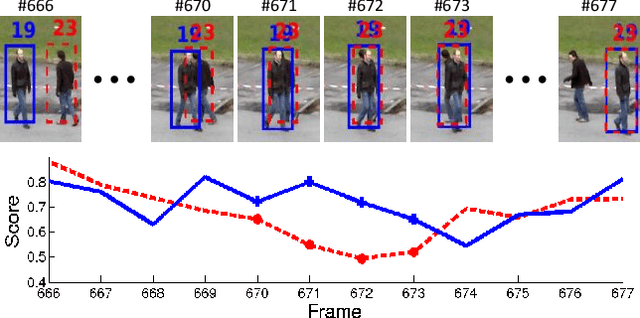
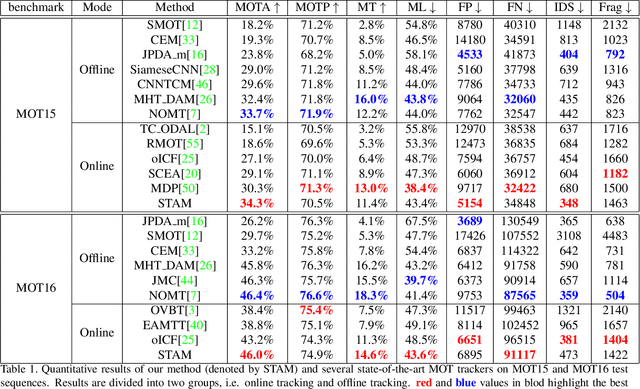
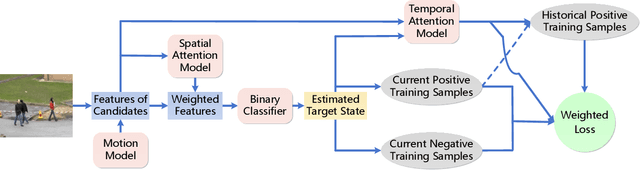
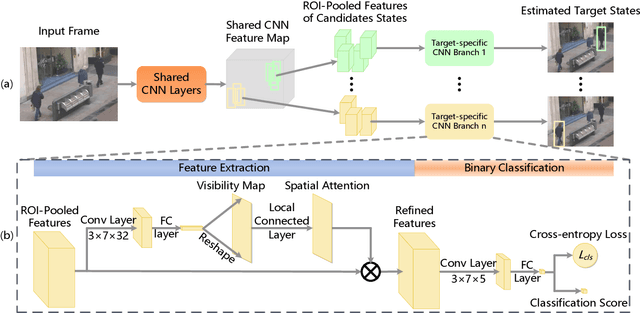
In this paper, we propose a CNN-based framework for online MOT. This framework utilizes the merits of single object trackers in adapting appearance models and searching for target in the next frame. Simply applying single object tracker for MOT will encounter the problem in computational efficiency and drifted results caused by occlusion. Our framework achieves computational efficiency by sharing features and using ROI-Pooling to obtain individual features for each target. Some online learned target-specific CNN layers are used for adapting the appearance model for each target. In the framework, we introduce spatial-temporal attention mechanism (STAM) to handle the drift caused by occlusion and interaction among targets. The visibility map of the target is learned and used for inferring the spatial attention map. The spatial attention map is then applied to weight the features. Besides, the occlusion status can be estimated from the visibility map, which controls the online updating process via weighted loss on training samples with different occlusion statuses in different frames. It can be considered as temporal attention mechanism. The proposed algorithm achieves 34.3% and 46.0% in MOTA on challenging MOT15 and MOT16 benchmark dataset respectively.
Learning Deep Neural Networks for Vehicle Re-ID with Visual-spatio-temporal Path Proposals
Aug 13, 2017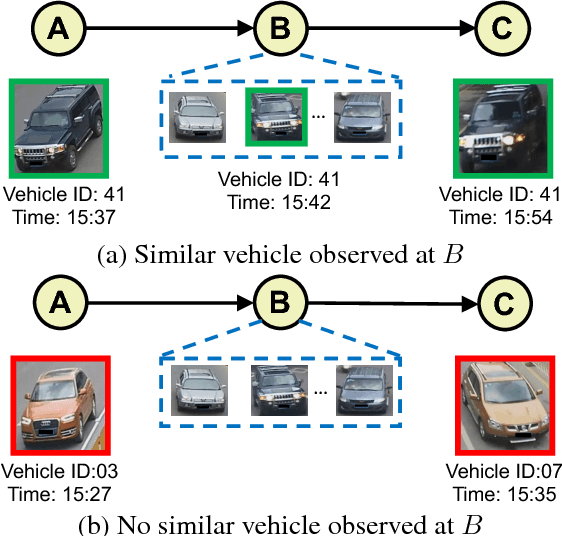
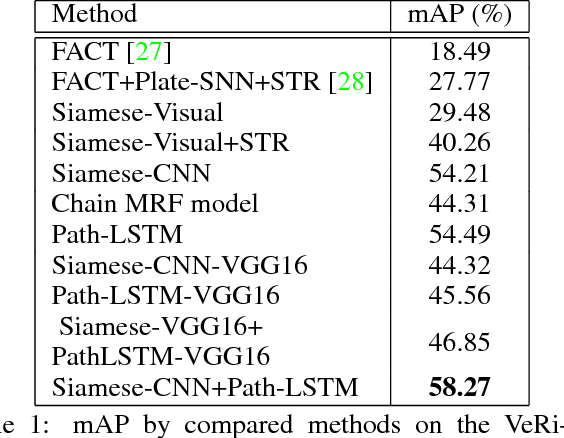
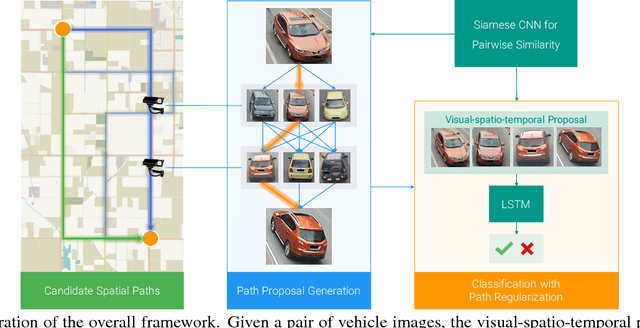
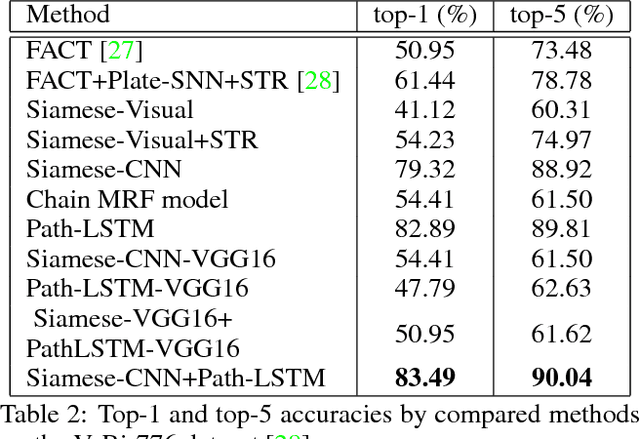
Vehicle re-identification is an important problem and has many applications in video surveillance and intelligent transportation. It gains increasing attention because of the recent advances of person re-identification techniques. However, unlike person re-identification, the visual differences between pairs of vehicle images are usually subtle and even challenging for humans to distinguish. Incorporating additional spatio-temporal information is vital for solving the challenging re-identification task. Existing vehicle re-identification methods ignored or used over-simplified models for the spatio-temporal relations between vehicle images. In this paper, we propose a two-stage framework that incorporates complex spatio-temporal information for effectively regularizing the re-identification results. Given a pair of vehicle images with their spatio-temporal information, a candidate visual-spatio-temporal path is first generated by a chain MRF model with a deeply learned potential function, where each visual-spatio-temporal state corresponds to an actual vehicle image with its spatio-temporal information. A Siamese-CNN+Path-LSTM model takes the candidate path as well as the pairwise queries to generate their similarity score. Extensive experiments and analysis show the effectiveness of our proposed method and individual components.
Unconstrained Fashion Landmark Detection via Hierarchical Recurrent Transformer Networks
Aug 07, 2017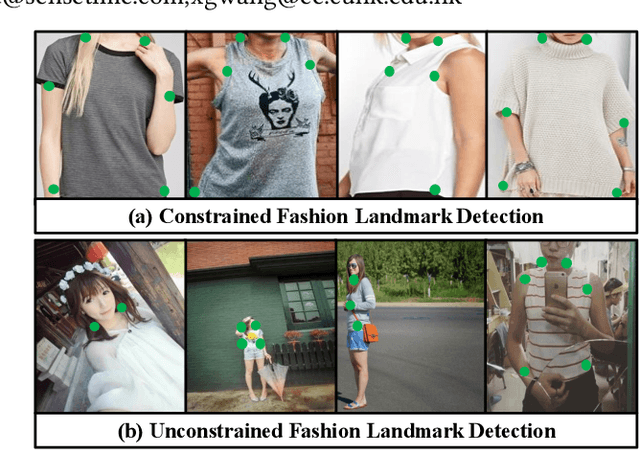

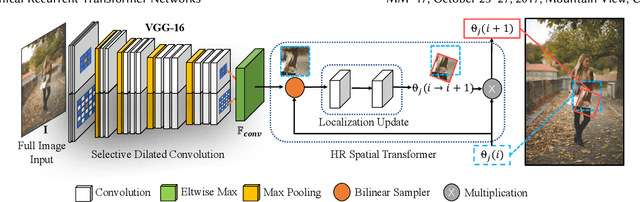

Fashion landmarks are functional key points defined on clothes, such as corners of neckline, hemline, and cuff. They have been recently introduced as an effective visual representation for fashion image understanding. However, detecting fashion landmarks are challenging due to background clutters, human poses, and scales. To remove the above variations, previous works usually assumed bounding boxes of clothes are provided in training and test as additional annotations, which are expensive to obtain and inapplicable in practice. This work addresses unconstrained fashion landmark detection, where clothing bounding boxes are not provided in both training and test. To this end, we present a novel Deep LAndmark Network (DLAN), where bounding boxes and landmarks are jointly estimated and trained iteratively in an end-to-end manner. DLAN contains two dedicated modules, including a Selective Dilated Convolution for handling scale discrepancies, and a Hierarchical Recurrent Spatial Transformer for handling background clutters. To evaluate DLAN, we present a large-scale fashion landmark dataset, namely Unconstrained Landmark Database (ULD), consisting of 30K images. Statistics show that ULD is more challenging than existing datasets in terms of image scales, background clutters, and human poses. Extensive experiments demonstrate the effectiveness of DLAN over the state-of-the-art methods. DLAN also exhibits excellent generalization across different clothing categories and modalities, making it extremely suitable for real-world fashion analysis.