 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpontaneous Symmetry Breaking in Neural Networks
Oct 17, 2017We propose a framework to understand the unprecedented performance and robustness of deep neural networks using field theory. Correlations between the weights within the same layer can be described by symmetries in that layer, and networks generalize better if such symmetries are broken to reduce the redundancies of the weights. Using a two parameter field theory, we find that the network can break such symmetries itself towards the end of training in a process commonly known in physics as spontaneous symmetry breaking. This corresponds to a network generalizing itself without any user input layers to break the symmetry, but by communication with adjacent layers. In the layer decoupling limit applicable to residual networks (He et al., 2015), we show that the remnant symmetries that survive the non-linear layers are spontaneously broken. The Lagrangian for the non-linear and weight layers together has striking similarities with the one in quantum field theory of a scalar. Using results from quantum field theory we show that our framework is able to explain many experimentally observed phenomena,such as training on random labels with zero error (Zhang et al., 2017), the information bottleneck, the phase transition out of it and gradient variance explosion (Shwartz-Ziv & Tishby, 2017), shattered gradients (Balduzzi et al., 2017), and many more.
Optimization assisted MCMC
Sep 09, 2017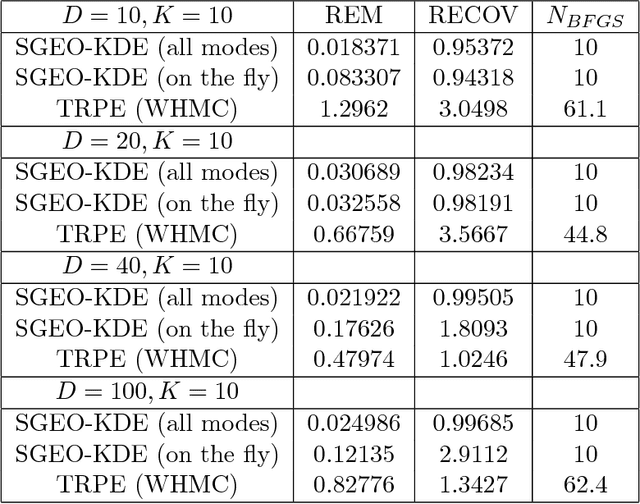
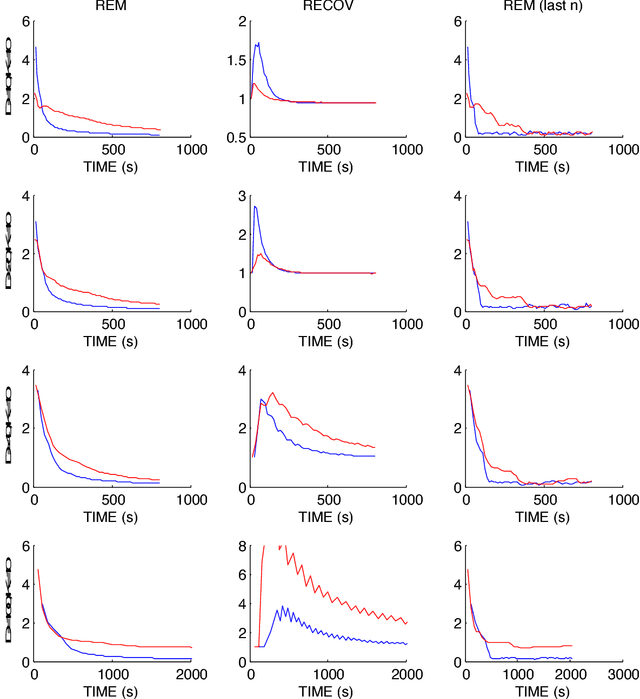
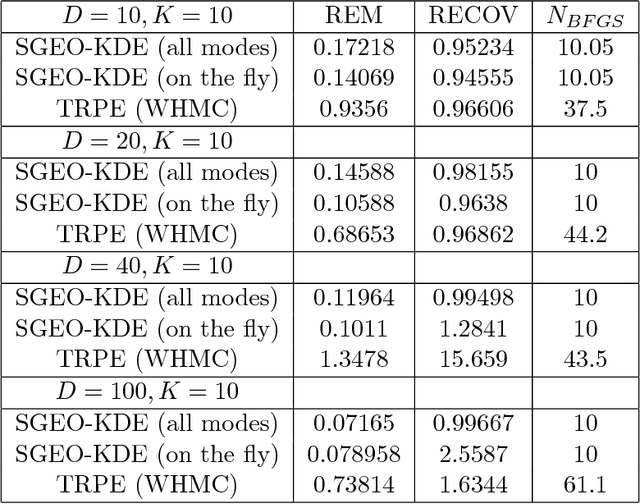
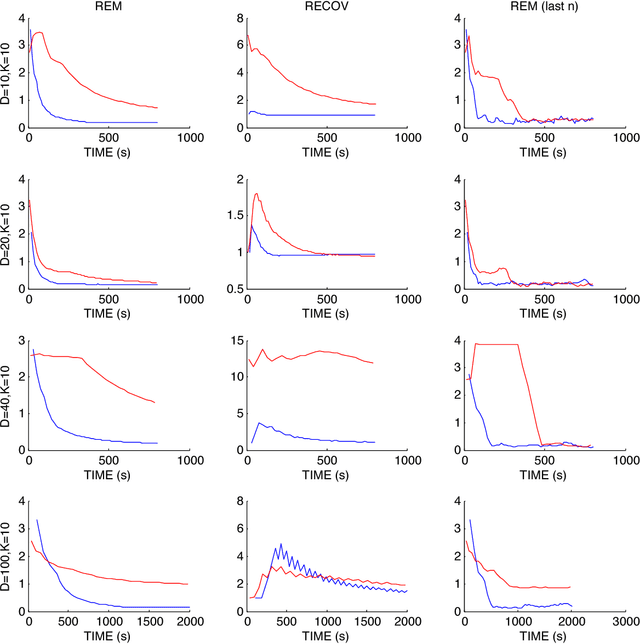
Markov Chain Monte Carlo (MCMC) sampling methods are widely used but often encounter either slow convergence or biased sampling when applied to multimodal high dimensional distributions. In this paper, we present a general framework of improving classical MCMC samplers by employing a global optimization method. The global optimization method first reduces a high dimensional search to an one dimensional geodesic to find a starting point close to a local mode. The search is accelerated and completed by using a local search method such as BFGS. We modify the target distribution by extracting a local Gaussian distribution aound the found mode. The process is repeated to find all the modes during sampling on the fly. We integrate the optimization algorithm into the Wormhole Hamiltonian Monte Carlo (WHMC) method. Experimental results show that, when applied to high dimensional, multimodal Gaussian mixture models and the network sensor localization problem, the proposed method achieves much faster convergence, with relative error from the mean improved by about an order of magnitude than WHMC in some cases.