 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperceptible Adversarial Attacks on Point Clouds Guided by Point-to-Surface Field
Dec 26, 2024



Adversarial attacks on point clouds are crucial for assessing and improving the adversarial robustness of 3D deep learning models. Traditional solutions strictly limit point displacement during attacks, making it challenging to balance imperceptibility with adversarial effectiveness. In this paper, we attribute the inadequate imperceptibility of adversarial attacks on point clouds to deviations from the underlying surface. To address this, we introduce a novel point-to-surface (P2S) field that adjusts adversarial perturbation directions by dragging points back to their original underlying surface. Specifically, we use a denoising network to learn the gradient field of the logarithmic density function encoding the shape's surface, and apply a distance-aware adjustment to perturbation directions during attacks, thereby enhancing imperceptibility. Extensive experiments show that adversarial attacks guided by our P2S field are more imperceptible, outperforming state-of-the-art methods.
Multi-Dimensional Insights: Benchmarking Real-World Personalization in Large Multimodal Models
Dec 17, 2024



The rapidly developing field of large multimodal models (LMMs) has led to the emergence of diverse models with remarkable capabilities. However, existing benchmarks fail to comprehensively, objectively and accurately evaluate whether LMMs align with the diverse needs of humans in real-world scenarios. To bridge this gap, we propose the Multi-Dimensional Insights (MDI) benchmark, which includes over 500 images covering six common scenarios of human life. Notably, the MDI-Benchmark offers two significant advantages over existing evaluations: (1) Each image is accompanied by two types of questions: simple questions to assess the model's understanding of the image, and complex questions to evaluate the model's ability to analyze and reason beyond basic content. (2) Recognizing that people of different age groups have varying needs and perspectives when faced with the same scenario, our benchmark stratifies questions into three age categories: young people, middle-aged people, and older people. This design allows for a detailed assessment of LMMs' capabilities in meeting the preferences and needs of different age groups. With MDI-Benchmark, the strong model like GPT-4o achieve 79% accuracy on age-related tasks, indicating that existing LMMs still have considerable room for improvement in addressing real-world applications. Looking ahead, we anticipate that the MDI-Benchmark will open new pathways for aligning real-world personalization in LMMs. The MDI-Benchmark data and evaluation code are available at https://mdi-benchmark.github.io/
Isochrony-Controlled Speech-to-Text Translation: A study on translating from Sino-Tibetan to Indo-European Languages
Nov 11, 2024



End-to-end speech translation (ST), which translates source language speech directly into target language text, has garnered significant attention in recent years. Many ST applications require strict length control to ensure that the translation duration matches the length of the source audio, including both speech and pause segments. Previous methods often controlled the number of words or characters generated by the Machine Translation model to approximate the source sentence's length without considering the isochrony of pauses and speech segments, as duration can vary between languages. To address this, we present improvements to the duration alignment component of our sequence-to-sequence ST model. Our method controls translation length by predicting the duration of speech and pauses in conjunction with the translation process. This is achieved by providing timing information to the decoder, ensuring it tracks the remaining duration for speech and pauses while generating the translation. The evaluation on the Zh-En test set of CoVoST 2, demonstrates that the proposed Isochrony-Controlled ST achieves 0.92 speech overlap and 8.9 BLEU, which has only a 1.4 BLEU drop compared to the ST baseline.
Investigating Neural Audio Codecs for Speech Language Model-Based Speech Generation
Sep 06, 2024



Neural audio codec tokens serve as the fundamental building blocks for speech language model (SLM)-based speech generation. However, there is no systematic understanding on how the codec system affects the speech generation performance of the SLM. In this work, we examine codec tokens within SLM framework for speech generation to provide insights for effective codec design. We retrain existing high-performing neural codec models on the same data set and loss functions to compare their performance in a uniform setting. We integrate codec tokens into two SLM systems: masked-based parallel speech generation system and an auto-regressive (AR) plus non-auto-regressive (NAR) model-based system. Our findings indicate that better speech reconstruction in codec systems does not guarantee improved speech generation in SLM. A high-quality codec decoder is crucial for natural speech production in SLM, while speech intelligibility depends more on quantization mechanism.
Exploring Robust Face-Voice Matching in Multilingual Environments
Jul 29, 2024
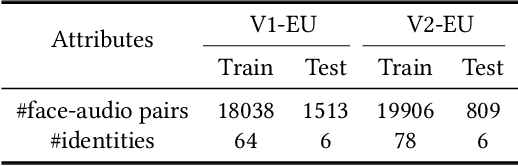
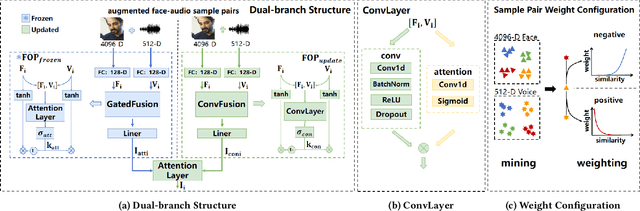

This paper presents Team Xaiofei's innovative approach to exploring Face-Voice Association in Multilingual Environments (FAME) at ACM Multimedia 2024. We focus on the impact of different languages in face-voice matching by building upon Fusion and Orthogonal Projection (FOP), introducing four key components: a dual-branch structure, dynamic sample pair weighting, robust data augmentation, and score polarization strategy. Our dual-branch structure serves as an auxiliary mechanism to better integrate and provide more comprehensive information. We also introduce a dynamic weighting mechanism for various sample pairs to optimize learning. Data augmentation techniques are employed to enhance the model's generalization across diverse conditions. Additionally, score polarization strategy based on age and gender matching confidence clarifies and accentuates the final results. Our methods demonstrate significant effectiveness, achieving an equal error rate (EER) of 20.07 on the V2-EH dataset and 21.76 on the V1-EU dataset.
Laugh Now Cry Later: Controlling Time-Varying Emotional States of Flow-Matching-Based Zero-Shot Text-to-Speech
Jul 17, 2024



People change their tones of voice, often accompanied by nonverbal vocalizations (NVs) such as laughter and cries, to convey rich emotions. However, most text-to-speech (TTS) systems lack the capability to generate speech with rich emotions, including NVs. This paper introduces EmoCtrl-TTS, an emotion-controllable zero-shot TTS that can generate highly emotional speech with NVs for any speaker. EmoCtrl-TTS leverages arousal and valence values, as well as laughter embeddings, to condition the flow-matching-based zero-shot TTS. To achieve high-quality emotional speech generation, EmoCtrl-TTS is trained using more than 27,000 hours of expressive data curated based on pseudo-labeling. Comprehensive evaluations demonstrate that EmoCtrl-TTS excels in mimicking the emotions of audio prompts in speech-to-speech translation scenarios. We also show that EmoCtrl-TTS can capture emotion changes, express strong emotions, and generate various NVs in zero-shot TTS. See https://aka.ms/emoctrl-tts for demo samples.
Global-Local Collaborative Inference with LLM for Lidar-Based Open-Vocabulary Detection
Jul 12, 2024Open-Vocabulary Detection (OVD) is the task of detecting all interesting objects in a given scene without predefined object classes. Extensive work has been done to deal with the OVD for 2D RGB images, but the exploration of 3D OVD is still limited. Intuitively, lidar point clouds provide 3D information, both object level and scene level, to generate trustful detection results. However, previous lidar-based OVD methods only focus on the usage of object-level features, ignoring the essence of scene-level information. In this paper, we propose a Global-Local Collaborative Scheme (GLIS) for the lidar-based OVD task, which contains a local branch to generate object-level detection result and a global branch to obtain scene-level global feature. With the global-local information, a Large Language Model (LLM) is applied for chain-of-thought inference, and the detection result can be refined accordingly. We further propose Reflected Pseudo Labels Generation (RPLG) to generate high-quality pseudo labels for supervision and Background-Aware Object Localization (BAOL) to select precise object proposals. Extensive experiments on ScanNetV2 and SUN RGB-D demonstrate the superiority of our methods. Code is released at https://github.com/GradiusTwinbee/GLIS.
E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
Jun 26, 2024



This paper introduces Embarrassingly Easy Text-to-Speech (E2 TTS), a fully non-autoregressive zero-shot text-to-speech system that offers human-level naturalness and state-of-the-art speaker similarity and intelligibility. In the E2 TTS framework, the text input is converted into a character sequence with filler tokens. The flow-matching-based mel spectrogram generator is then trained based on the audio infilling task. Unlike many previous works, it does not require additional components (e.g., duration model, grapheme-to-phoneme) or complex techniques (e.g., monotonic alignment search). Despite its simplicity, E2 TTS achieves state-of-the-art zero-shot TTS capabilities that are comparable to or surpass previous works, including Voicebox and NaturalSpeech 3. The simplicity of E2 TTS also allows for flexibility in the input representation. We propose several variants of E2 TTS to improve usability during inference. See https://aka.ms/e2tts/ for demo samples.
TacoLM: GaTed Attention Equipped Codec Language Model are Efficient Zero-Shot Text to Speech Synthesizers
Jun 22, 2024Neural codec language model (LM) has demonstrated strong capability in zero-shot text-to-speech (TTS) synthesis. However, the codec LM often suffers from limitations in inference speed and stability, due to its auto-regressive nature and implicit alignment between text and audio. In this work, to handle these challenges, we introduce a new variant of neural codec LM, namely TacoLM. Specifically, TacoLM introduces a gated attention mechanism to improve the training and inference efficiency and reduce the model size. Meanwhile, an additional gated cross-attention layer is included for each decoder layer, which improves the efficiency and content accuracy of the synthesized speech. In the evaluation of the Librispeech corpus, the proposed TacoLM achieves a better word error rate, speaker similarity, and mean opinion score, with 90% fewer parameters and 5.2 times speed up, compared with VALL-E. Demo and code is available at https://ereboas.github.io/TacoLM/.
Knowledge-driven Subspace Fusion and Gradient Coordination for Multi-modal Learning
Jun 20, 2024



Multi-modal learning plays a crucial role in cancer diagnosis and prognosis. Current deep learning based multi-modal approaches are often limited by their abilities to model the complex correlations between genomics and histology data, addressing the intrinsic complexity of tumour ecosystem where both tumour and microenvironment contribute to malignancy. We propose a biologically interpretative and robust multi-modal learning framework to efficiently integrate histology images and genomics by decomposing the feature subspace of histology images and genomics, reflecting distinct tumour and microenvironment features. To enhance cross-modal interactions, we design a knowledge-driven subspace fusion scheme, consisting of a cross-modal deformable attention module and a gene-guided consistency strategy. Additionally, in pursuit of dynamically optimizing the subspace knowledge, we further propose a novel gradient coordination learning strategy. Extensive experiments demonstrate the effectiveness of the proposed method, outperforming state-of-the-art techniques in three downstream tasks of glioma diagnosis, tumour grading, and survival analysis. Our code is available at https://github.com/helenypzhang/Subspace-Multimodal-Learning.