 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph R-CNN: Towards Accurate 3D Object Detection with Semantic-Decorated Local Graph
Aug 07, 2022Two-stage detectors have gained much popularity in 3D object detection. Most two-stage 3D detectors utilize grid points, voxel grids, or sampled keypoints for RoI feature extraction in the second stage. Such methods, however, are inefficient in handling unevenly distributed and sparse outdoor points. This paper solves this problem in three aspects. 1) Dynamic Point Aggregation. We propose the patch search to quickly search points in a local region for each 3D proposal. The dynamic farthest voxel sampling is then applied to evenly sample the points. Especially, the voxel size varies along the distance to accommodate the uneven distribution of points. 2) RoI-graph Pooling. We build local graphs on the sampled points to better model contextual information and mine point relations through iterative message passing. 3) Visual Features Augmentation. We introduce a simple yet effective fusion strategy to compensate for sparse LiDAR points with limited semantic cues. Based on these modules, we construct our Graph R-CNN as the second stage, which can be applied to existing one-stage detectors to consistently improve the detection performance. Extensive experiments show that Graph R-CNN outperforms the state-of-the-art 3D detection models by a large margin on both the KITTI and Waymo Open Dataset. And we rank first place on the KITTI BEV car detection leaderboard. Code will be available at \url{https://github.com/Nightmare-n/GraphRCNN}.
Motion-aware Memory Network for Fast Video Salient Object Detection
Aug 01, 2022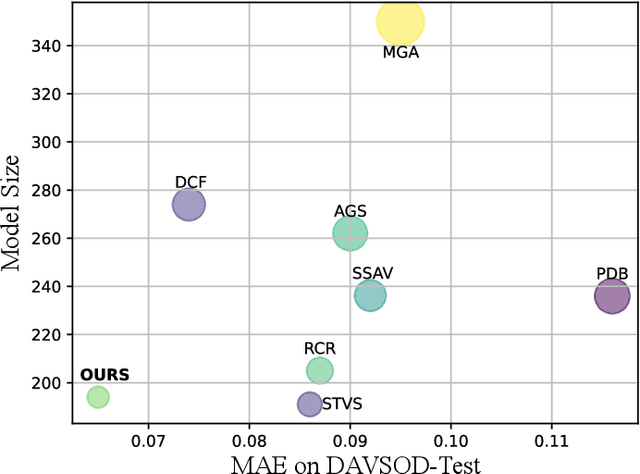

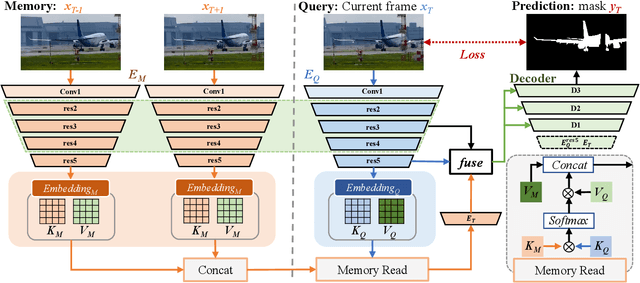
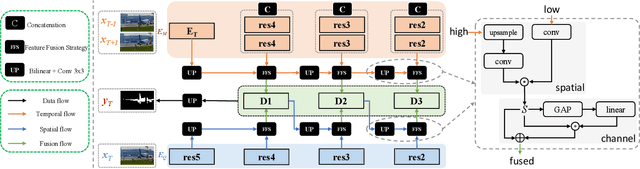
Previous methods based on 3DCNN, convLSTM, or optical flow have achieved great success in video salient object detection (VSOD). However, they still suffer from high computational costs or poor quality of the generated saliency maps. To solve these problems, we design a space-time memory (STM)-based network, which extracts useful temporal information of the current frame from adjacent frames as the temporal branch of VSOD. Furthermore, previous methods only considered single-frame prediction without temporal association. As a result, the model may not focus on the temporal information sufficiently. Thus, we initially introduce object motion prediction between inter-frame into VSOD. Our model follows standard encoder--decoder architecture. In the encoding stage, we generate high-level temporal features by using high-level features from the current and its adjacent frames. This approach is more efficient than the optical flow-based methods. In the decoding stage, we propose an effective fusion strategy for spatial and temporal branches. The semantic information of the high-level features is used to fuse the object details in the low-level features, and then the spatiotemporal features are obtained step by step to reconstruct the saliency maps. Moreover, inspired by the boundary supervision commonly used in image salient object detection (ISOD), we design a motion-aware loss for predicting object boundary motion and simultaneously perform multitask learning for VSOD and object motion prediction, which can further facilitate the model to extract spatiotemporal features accurately and maintain the object integrity. Extensive experiments on several datasets demonstrated the effectiveness of our method and can achieve state-of-the-art metrics on some datasets. The proposed model does not require optical flow or other preprocessing, and can reach a speed of nearly 100 FPS during inference.
Towards Efficient Adversarial Training on Vision Transformers
Jul 21, 2022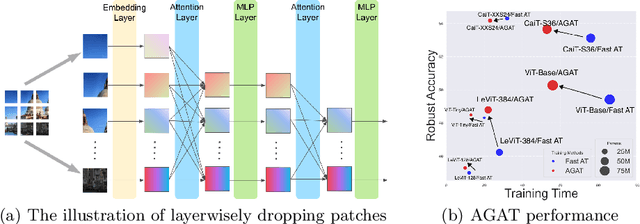
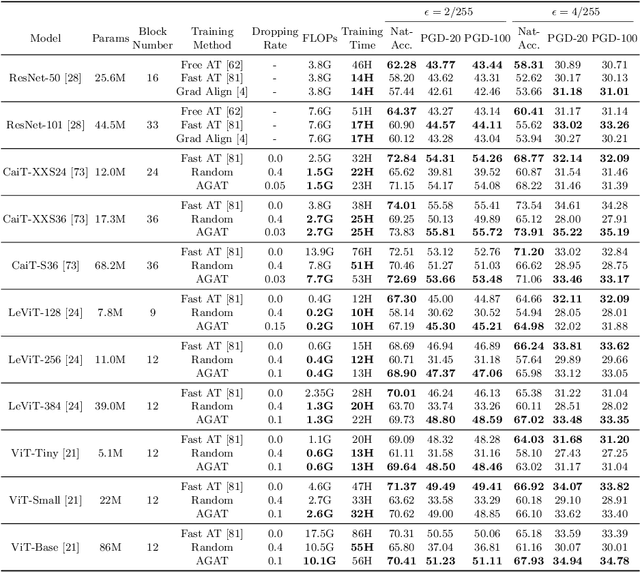
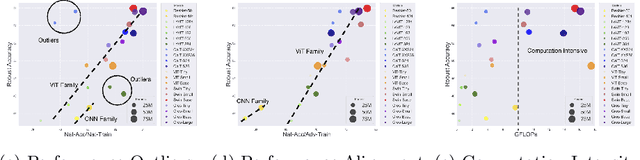
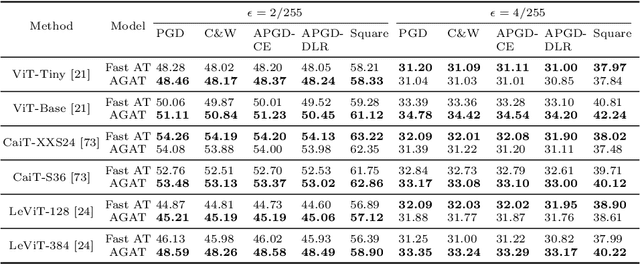
Vision Transformer (ViT), as a powerful alternative to Convolutional Neural Network (CNN), has received much attention. Recent work showed that ViTs are also vulnerable to adversarial examples like CNNs. To build robust ViTs, an intuitive way is to apply adversarial training since it has been shown as one of the most effective ways to accomplish robust CNNs. However, one major limitation of adversarial training is its heavy computational cost. The self-attention mechanism adopted by ViTs is a computationally intense operation whose expense increases quadratically with the number of input patches, making adversarial training on ViTs even more time-consuming. In this work, we first comprehensively study fast adversarial training on a variety of vision transformers and illustrate the relationship between the efficiency and robustness. Then, to expediate adversarial training on ViTs, we propose an efficient Attention Guided Adversarial Training mechanism. Specifically, relying on the specialty of self-attention, we actively remove certain patch embeddings of each layer with an attention-guided dropping strategy during adversarial training. The slimmed self-attention modules accelerate the adversarial training on ViTs significantly. With only 65\% of the fast adversarial training time, we match the state-of-the-art results on the challenging ImageNet benchmark.
Neural Collapse Inspired Attraction-Repulsion-Balanced Loss for Imbalanced Learning
Apr 27, 2022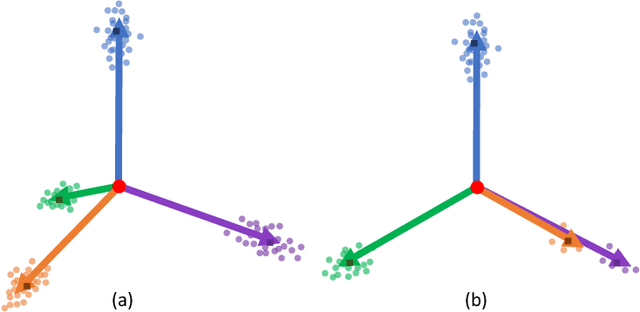
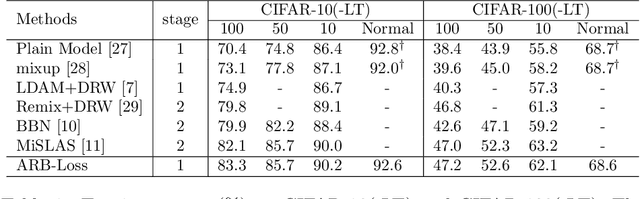
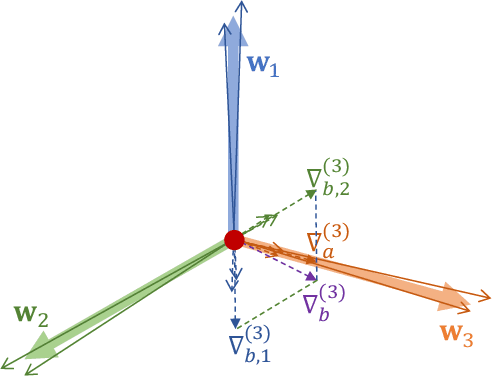
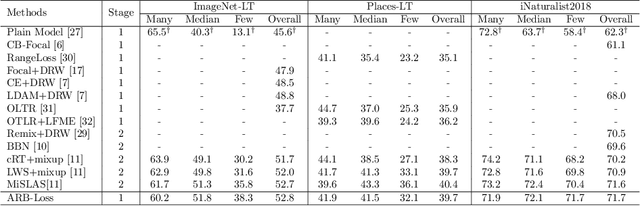
Class imbalance distribution widely exists in real-world engineering. However, the mainstream optimization algorithms that seek to minimize error will trap the deep learning model in sub-optimums when facing extreme class imbalance. It seriously harms the classification precision, especially on the minor classes. The essential reason is that the gradients of the classifier weights are imbalanced among the components from different classes. In this paper, we propose Attraction-Repulsion-Balanced Loss (ARB-Loss) to balance the different components of the gradients. We perform experiments on the large-scale classification and segmentation datasets and our ARB-Loss can achieve state-of-the-art performance via only one-stage training instead of 2-stage learning like nowadays SOTA works.
CLRNet: Cross Layer Refinement Network for Lane Detection
Mar 19, 2022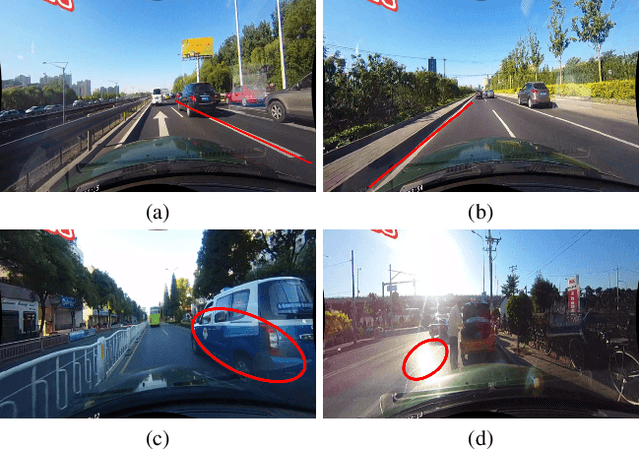
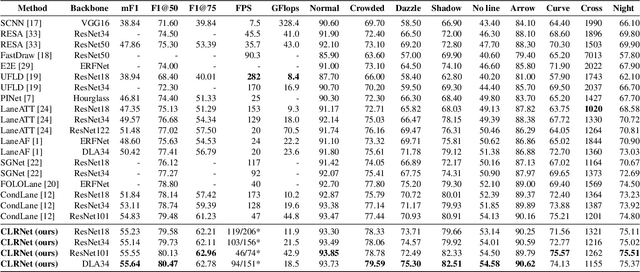
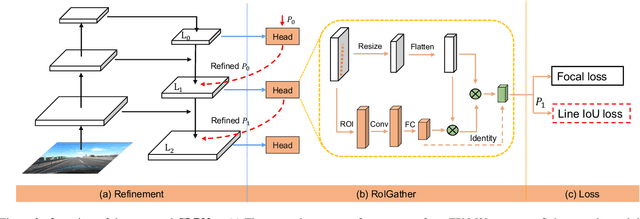
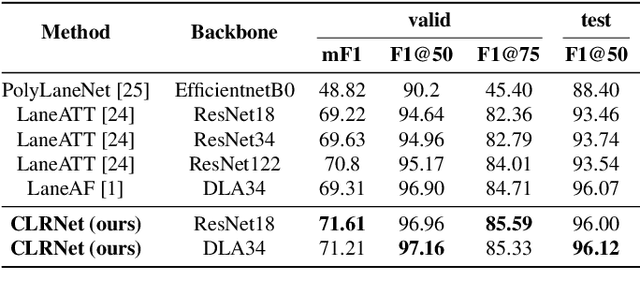
Lane is critical in the vision navigation system of the intelligent vehicle. Naturally, lane is a traffic sign with high-level semantics, whereas it owns the specific local pattern which needs detailed low-level features to localize accurately. Using different feature levels is of great importance for accurate lane detection, but it is still under-explored. In this work, we present Cross Layer Refinement Network (CLRNet) aiming at fully utilizing both high-level and low-level features in lane detection. In particular, it first detects lanes with high-level semantic features then performs refinement based on low-level features. In this way, we can exploit more contextual information to detect lanes while leveraging local detailed lane features to improve localization accuracy. We present ROIGather to gather global context, which further enhances the feature representation of lanes. In addition to our novel network design, we introduce Line IoU loss which regresses the lane line as a whole unit to improve the localization accuracy. Experiments demonstrate that the proposed method greatly outperforms the state-of-the-art lane detection approaches.
WeakM3D: Towards Weakly Supervised Monocular 3D Object Detection
Mar 16, 2022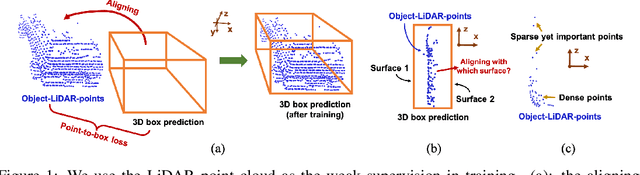
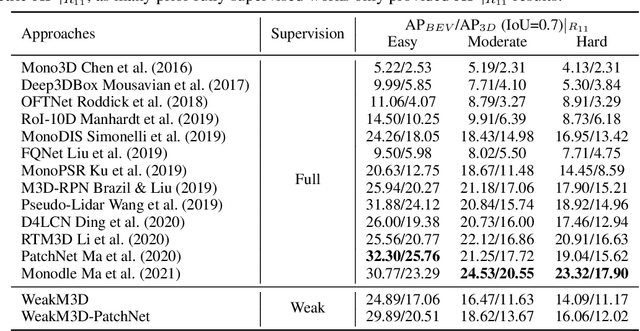
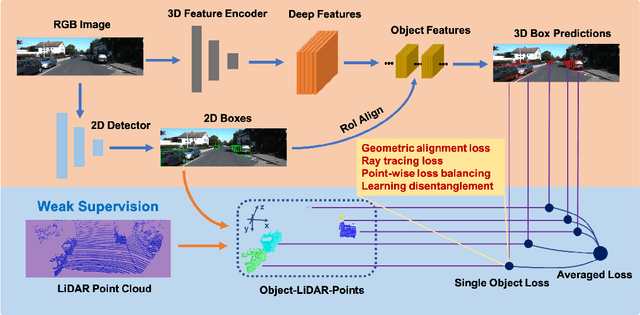
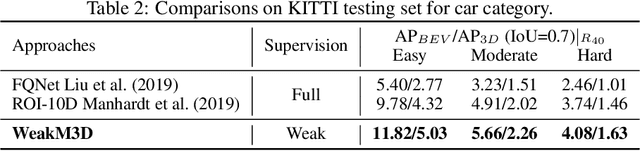
Monocular 3D object detection is one of the most challenging tasks in 3D scene understanding. Due to the ill-posed nature of monocular imagery, existing monocular 3D detection methods highly rely on training with the manually annotated 3D box labels on the LiDAR point clouds. This annotation process is very laborious and expensive. To dispense with the reliance on 3D box labels, in this paper we explore the weakly supervised monocular 3D detection. Specifically, we first detect 2D boxes on the image. Then, we adopt the generated 2D boxes to select corresponding RoI LiDAR points as the weak supervision. Eventually, we adopt a network to predict 3D boxes which can tightly align with associated RoI LiDAR points. This network is learned by minimizing our newly-proposed 3D alignment loss between the 3D box estimates and the corresponding RoI LiDAR points. We will illustrate the potential challenges of the above learning problem and resolve these challenges by introducing several effective designs into our method. Codes will be available at https://github.com/SPengLiang/WeakM3D.
VLAD-VSA: Cross-Domain Face Presentation Attack Detection with Vocabulary Separation and Adaptation
Feb 21, 2022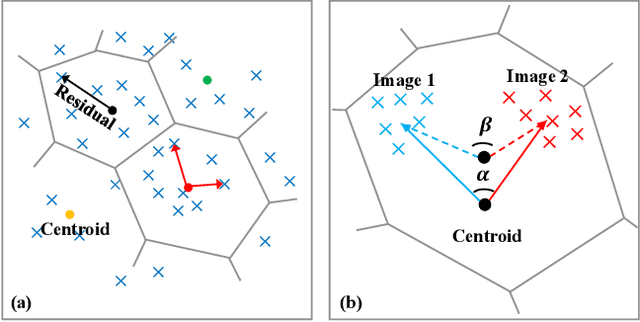
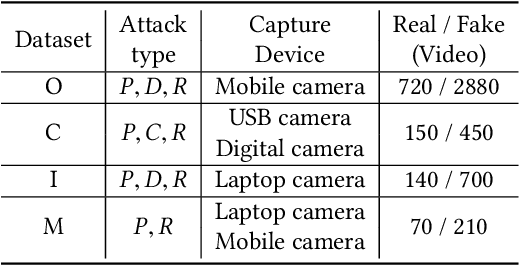
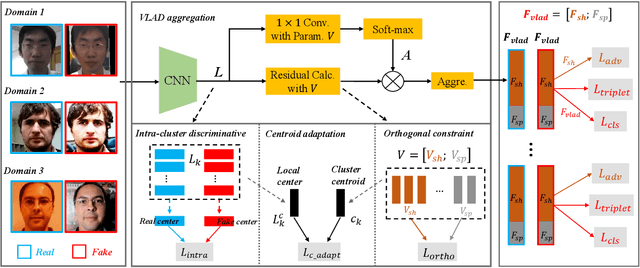
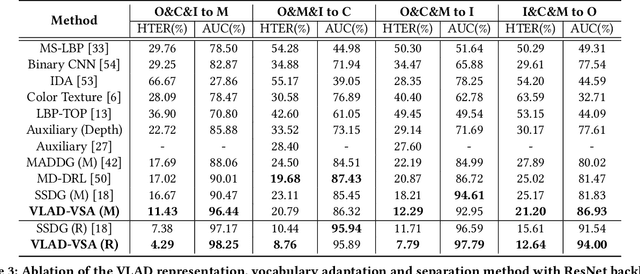
For face presentation attack detection (PAD), most of the spoofing cues are subtle, local image patterns (e.g., local image distortion, 3D mask edge and cut photo edges). The representations of existing PAD works with simple global pooling method, however, lose the local feature discriminability. In this paper, the VLAD aggregation method is adopted to quantize local features with visual vocabulary locally partitioning the feature space, and hence preserve the local discriminability. We further propose the vocabulary separation and adaptation method to modify VLAD for cross-domain PADtask. The proposed vocabulary separation method divides vocabulary into domain-shared and domain-specific visual words to cope with the diversity of live and attack faces under the cross-domain scenario. The proposed vocabulary adaptation method imitates the maximization step of the k-means algorithm in the end-to-end training, which guarantees the visual words be close to the center of assigned local features and thus brings robust similarity measurement. We give illustrations and extensive experiments to demonstrate the effectiveness of VLAD with the proposed vocabulary separation and adaptation method on standard cross-domain PAD benchmarks. The codes are available at https://github.com/Liubinggunzu/VLAD-VSA.
SimulSLT: End-to-End Simultaneous Sign Language Translation
Dec 08, 2021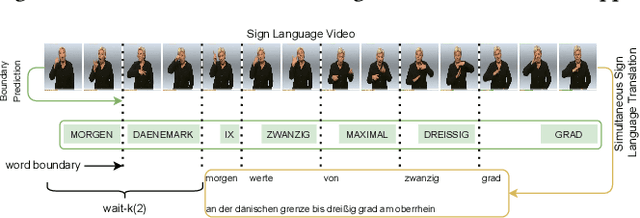
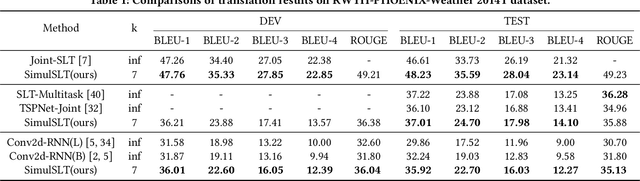
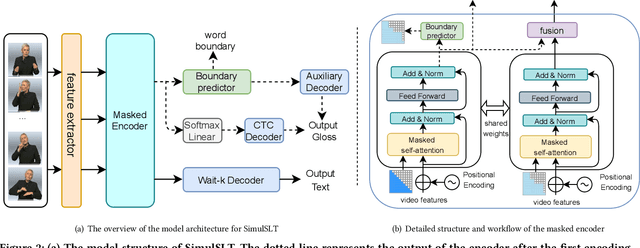
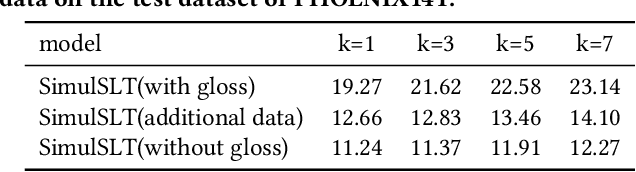
Sign language translation as a kind of technology with profound social significance has attracted growing researchers' interest in recent years. However, the existing sign language translation methods need to read all the videos before starting the translation, which leads to a high inference latency and also limits their application in real-life scenarios. To solve this problem, we propose SimulSLT, the first end-to-end simultaneous sign language translation model, which can translate sign language videos into target text concurrently. SimulSLT is composed of a text decoder, a boundary predictor, and a masked encoder. We 1) use the wait-k strategy for simultaneous translation. 2) design a novel boundary predictor based on the integrate-and-fire module to output the gloss boundary, which is used to model the correspondence between the sign language video and the gloss. 3) propose an innovative re-encode method to help the model obtain more abundant contextual information, which allows the existing video features to interact fully. The experimental results conducted on the RWTH-PHOENIX-Weather 2014T dataset show that SimulSLT achieves BLEU scores that exceed the latest end-to-end non-simultaneous sign language translation model while maintaining low latency, which proves the effectiveness of our method.
Why Do We Click: Visual Impression-aware News Recommendation
Sep 26, 2021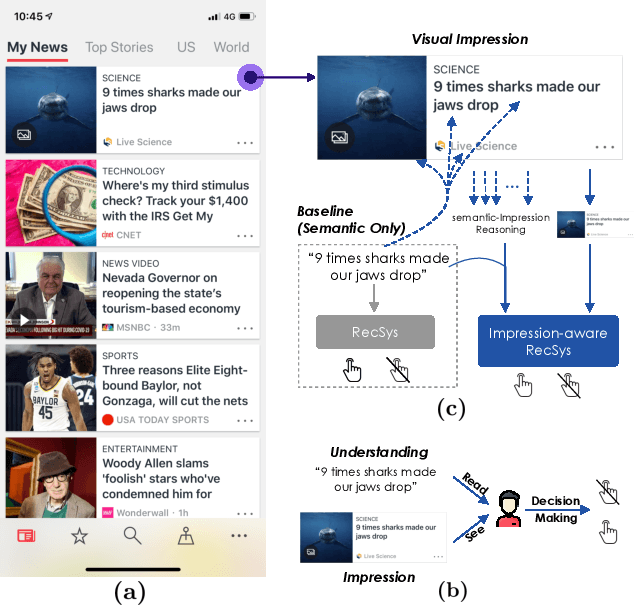
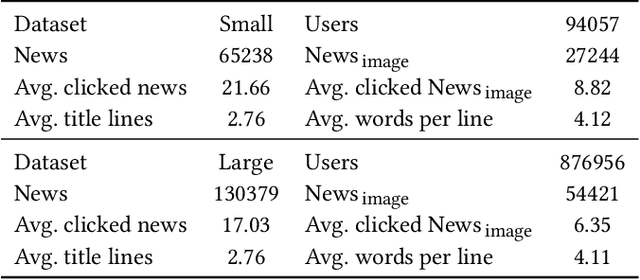
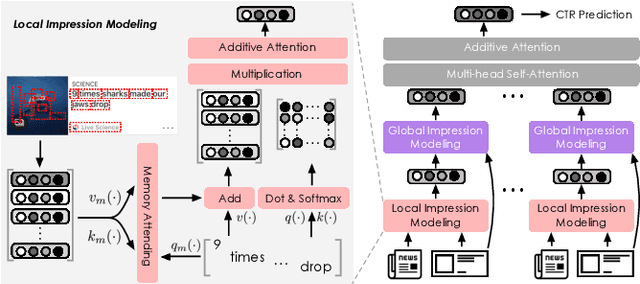
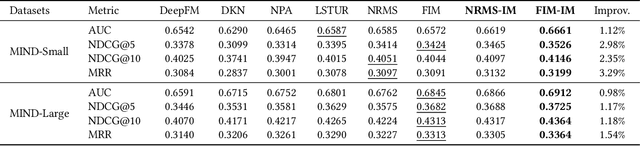
There is a soaring interest in the news recommendation research scenario due to the information overload. To accurately capture users' interests, we propose to model multi-modal features, in addition to the news titles that are widely used in existing works, for news recommendation. Besides, existing research pays little attention to the click decision-making process in designing multi-modal modeling modules. In this work, inspired by the fact that users make their click decisions mostly based on the visual impression they perceive when browsing news, we propose to capture such visual impression information with visual-semantic modeling for news recommendation. Specifically, we devise the local impression modeling module to simultaneously attend to decomposed details in the impression when understanding the semantic meaning of news title, which could explicitly get close to the process of users reading news. In addition, we inspect the impression from a global view and take structural information, such as the arrangement of different fields and spatial position of different words on the impression, into the modeling of multiple modalities. To accommodate the research of visual impression-aware news recommendation, we extend the text-dominated news recommendation dataset MIND by adding snapshot impression images and will release it to nourish the research field. Extensive comparisons with the state-of-the-art news recommenders along with the in-depth analyses demonstrate the effectiveness of the proposed method and the promising capability of modeling visual impressions for the content-based recommenders.
SimulLR: Simultaneous Lip Reading Transducer with Attention-Guided Adaptive Memory
Aug 31, 2021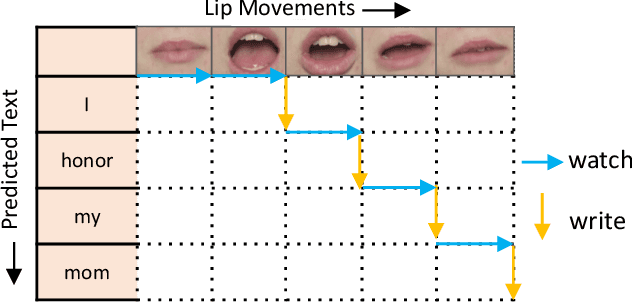
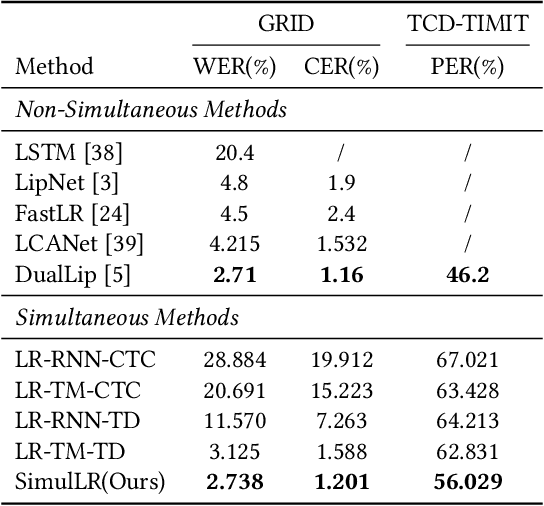
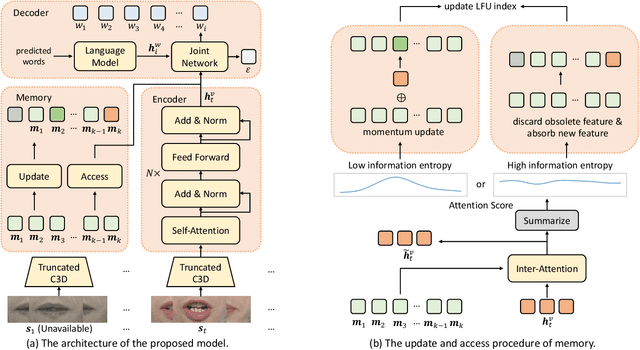
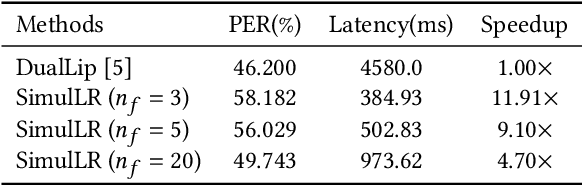
Lip reading, aiming to recognize spoken sentences according to the given video of lip movements without relying on the audio stream, has attracted great interest due to its application in many scenarios. Although prior works that explore lip reading have obtained salient achievements, they are all trained in a non-simultaneous manner where the predictions are generated requiring access to the full video. To breakthrough this constraint, we study the task of simultaneous lip reading and devise SimulLR, a simultaneous lip Reading transducer with attention-guided adaptive memory from three aspects: (1) To address the challenge of monotonic alignments while considering the syntactic structure of the generated sentences under simultaneous setting, we build a transducer-based model and design several effective training strategies including CTC pre-training, model warm-up and curriculum learning to promote the training of the lip reading transducer. (2) To learn better spatio-temporal representations for simultaneous encoder, we construct a truncated 3D convolution and time-restricted self-attention layer to perform the frame-to-frame interaction within a video segment containing fixed number of frames. (3) The history information is always limited due to the storage in real-time scenarios, especially for massive video data. Therefore, we devise a novel attention-guided adaptive memory to organize semantic information of history segments and enhance the visual representations with acceptable computation-aware latency. The experiments show that the SimulLR achieves the translation speedup 9.10$\times$ compared with the state-of-the-art non-simultaneous methods, and also obtains competitive results, which indicates the effectiveness of our proposed methods.