 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021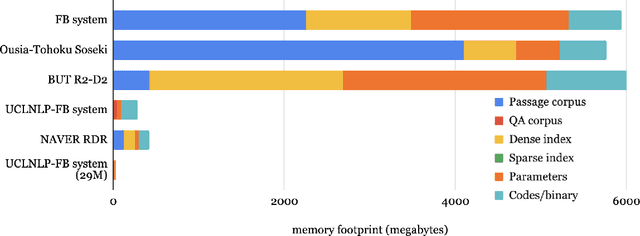
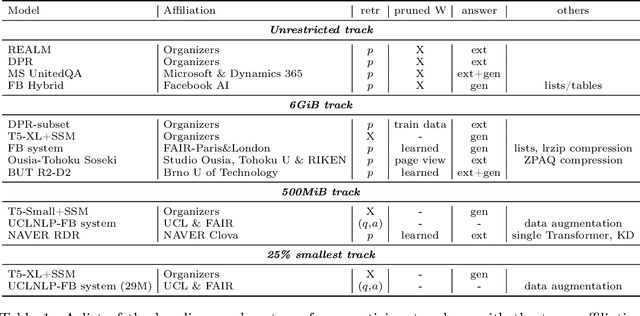
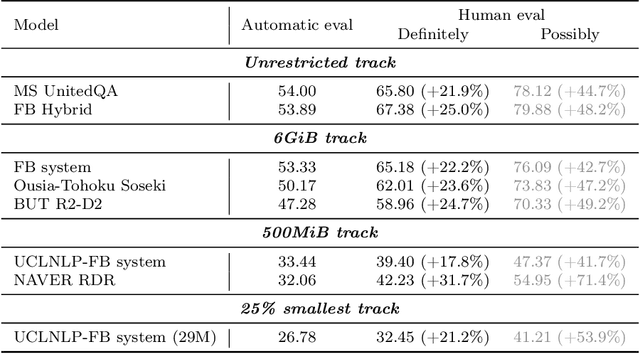
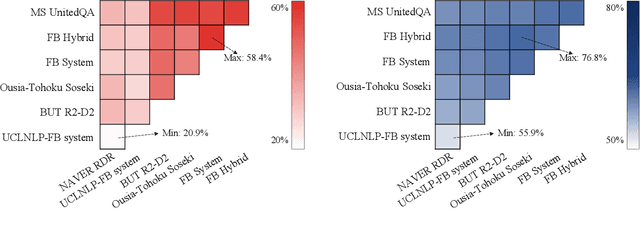
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Posterior Differential Regularization with f-divergence for Improving Model Robustness
Oct 23, 2020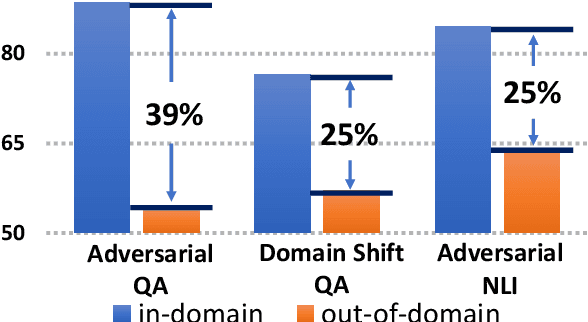

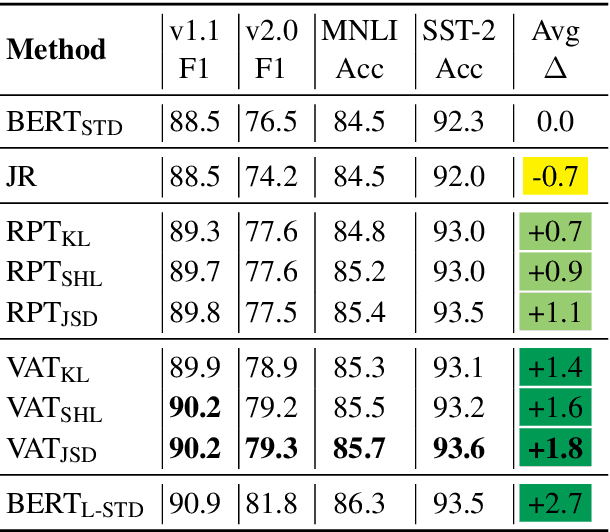
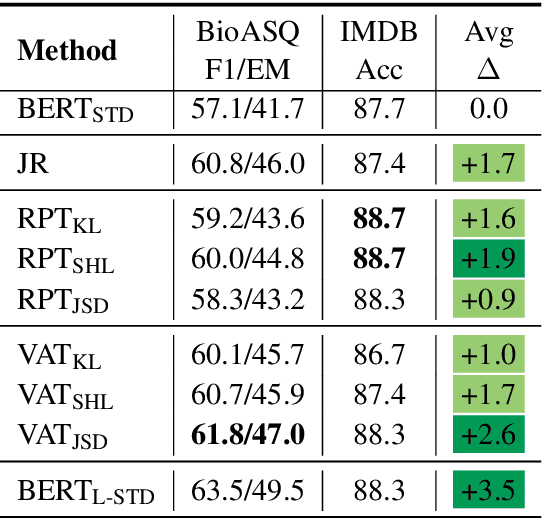
We address the problem of enhancing model robustness through regularization. Specifically, we focus on methods that regularize the model posterior difference between clean and noisy inputs. Theoretically, we provide a connection of two recent methods, Jacobian Regularization and Virtual Adversarial Training, under this framework. Additionally, we generalize the posterior differential regularization to the family of $f$-divergences and characterize the overall regularization framework in terms of Jacobian matrix. Empirically, we systematically compare those regularizations and standard BERT training on a diverse set of tasks to provide a comprehensive profile of their effect on model in-domain and out-of-domain generalization. For both fully supervised and semi-supervised settings, our experiments show that regularizing the posterior differential with $f$-divergence can result in well-improved model robustness. In particular, with a proper $f$-divergence, a BERT-base model can achieve comparable generalization as its BERT-large counterpart for in-domain, adversarial and domain shift scenarios, indicating the great potential of the proposed framework for boosting model generalization for NLP models.
A Tale of Two Linkings: Dynamically Gating between Schema Linking and Structural Linking for Text-to-SQL Parsing
Sep 30, 2020
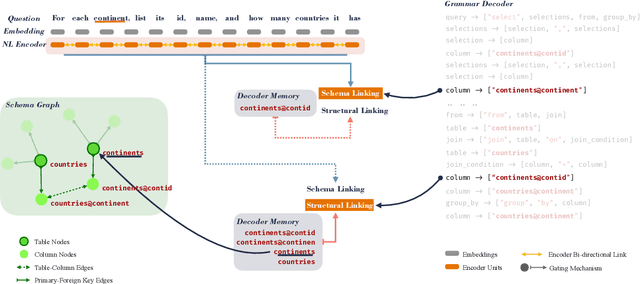
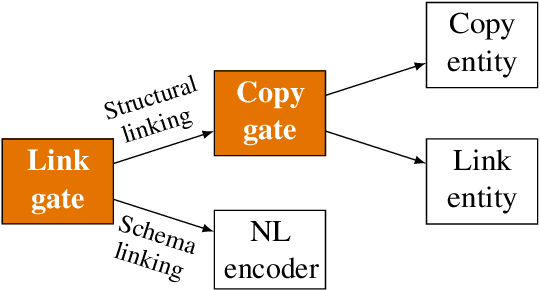

In Text-to-SQL semantic parsing, selecting the correct entities (tables and columns) to output is both crucial and challenging; the parser is required to connect the natural language (NL) question and the current SQL prediction with the structured world, i.e., the database. We formulate two linking processes to address this challenge: schema linking which links explicit NL mentions to the database and structural linking which links the entities in the output SQL with their structural relationships in the database schema. Intuitively, the effects of these two linking processes change based on the entity being generated, thus we propose to dynamically choose between them using a gating mechanism. Integrating the proposed method with two graph neural network based semantic parsers together with BERT representations demonstrates substantial gains in parsing accuracy on the challenging Spider dataset. Analyses show that our method helps to enhance the structure of the model output when generating complicated SQL queries and offers explainable predictions.
Generation-Augmented Retrieval for Open-domain Question Answering
Sep 17, 2020
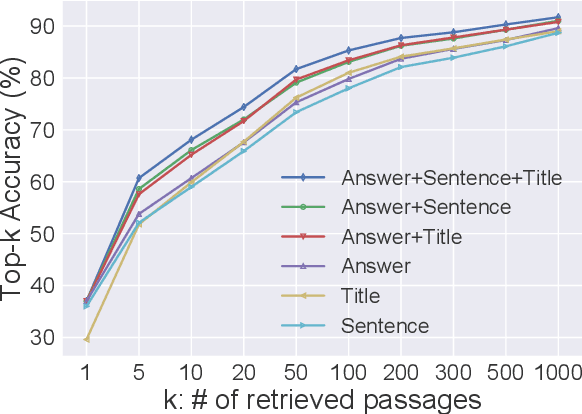
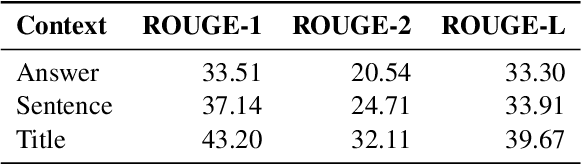
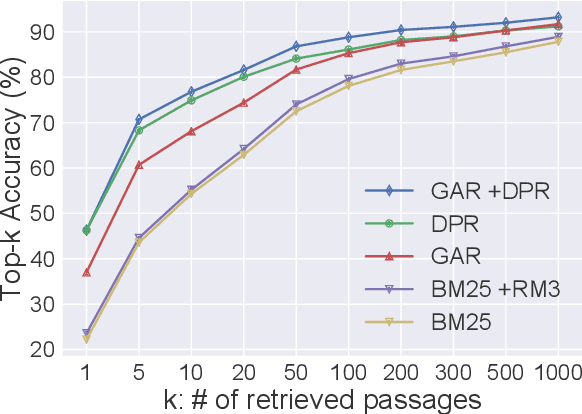
Conventional sparse retrieval methods such as TF-IDF and BM25 are simple and efficient, but solely rely on lexical overlap and fail to conduct semantic matching. Recent dense retrieval methods learn latent representations to tackle the lexical mismatch problem, while being more computationally expensive and sometimes insufficient for exact matching as they embed the entire text sequence into a single vector with limited capacity. In this paper, we present Generation-Augmented Retrieval (GAR), a query expansion method that augments a query with relevant contexts through text generation. We demonstrate on open-domain question answering (QA) that the generated contexts significantly enrich the semantics of the queries and thus GAR with sparse representations (BM25) achieves comparable or better performance than the current state-of-the-art dense method DPR \cite{karpukhin2020dense}. We show that generating various contexts of a query is beneficial as fusing their results consistently yields a better retrieval accuracy. Moreover, GAR achieves the state-of-the-art performance of extractive QA on the Natural Questions and TriviaQA datasets when equipped with an extractive reader.
HittER: Hierarchical Transformers for Knowledge Graph Embeddings
Aug 28, 2020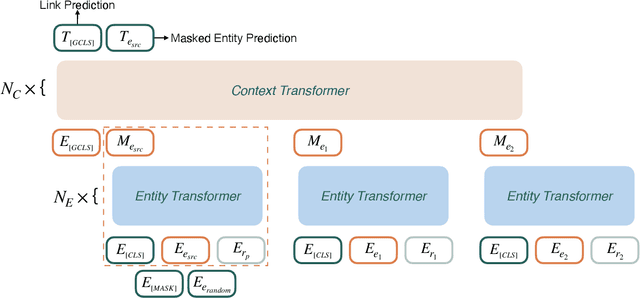
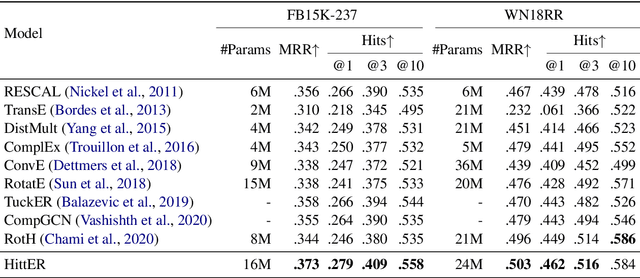

This paper examines the challenging problem of learning representations of entities and relations in a complex multi-relational knowledge graph. We propose HittER, a Hierarchical Transformer model to jointly learn Entity-relation composition and Relational contextualization based on a source entity's neighborhood. Our proposed model consists of two different Transformer blocks: the bottom block extracts features of each entity-relation pair in the local neighborhood of the source entity and the top block aggregates the relational information from the outputs of the bottom block. We further design a masked entity prediction task to balance information from the relational context and the source entity itself. Evaluated on the task of link prediction, our approach achieves new state-of-the-art results on two standard benchmark datasets FB15K-237 and WN18RR.
Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing
Aug 20, 2020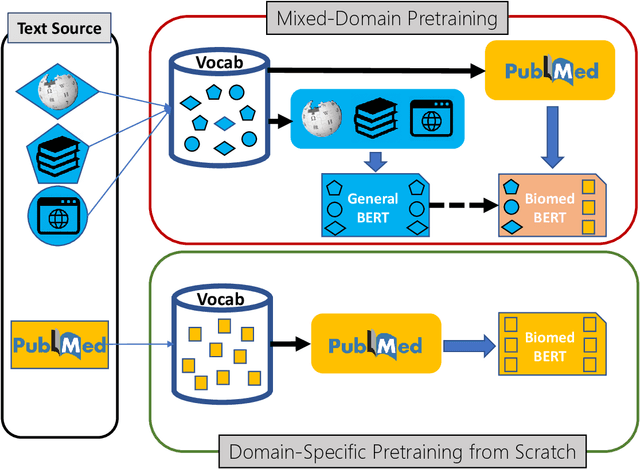
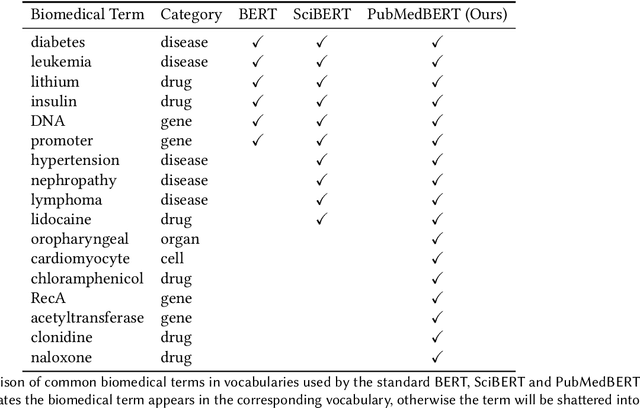
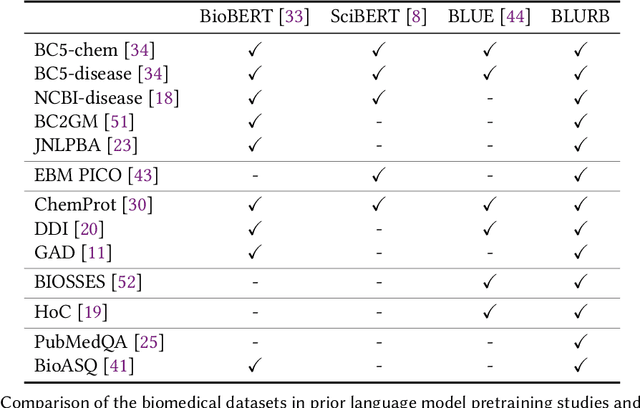
Pretraining large neural language models, such as BERT, has led to impressive gains on many natural language processing (NLP) tasks. However, most pretraining efforts focus on general domain corpora, such as newswire and Web. A prevailing assumption is that even domain-specific pretraining can benefit by starting from general-domain language models. In this paper, we challenge this assumption by showing that for domains with abundant unlabeled text, such as biomedicine, pretraining language models from scratch results in substantial gains over continual pretraining of general-domain language models. To facilitate this investigation, we compile a comprehensive biomedical NLP benchmark from publicly-available datasets. Our experiments show that domain-specific pretraining serves as a solid foundation for a wide range of biomedical NLP tasks, leading to new state-of-the-art results across the board. Further, in conducting a thorough evaluation of modeling choices, both for pretraining and task-specific fine-tuning, we discover that some common practices are unnecessary with BERT models, such as using complex tagging schemes in named entity recognition (NER). To help accelerate research in biomedical NLP, we have released our state-of-the-art pretrained and task-specific models for the community, and created a leaderboard featuring our BLURB benchmark (short for Biomedical Language Understanding & Reasoning Benchmark) at https://aka.ms/BLURB.
Very Deep Transformers for Neural Machine Translation
Aug 18, 2020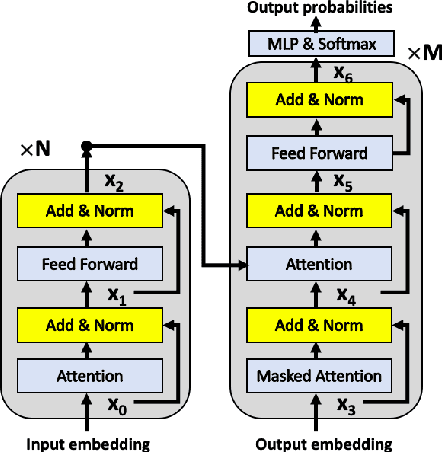
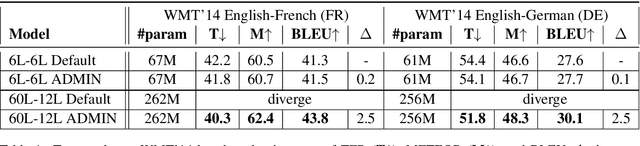
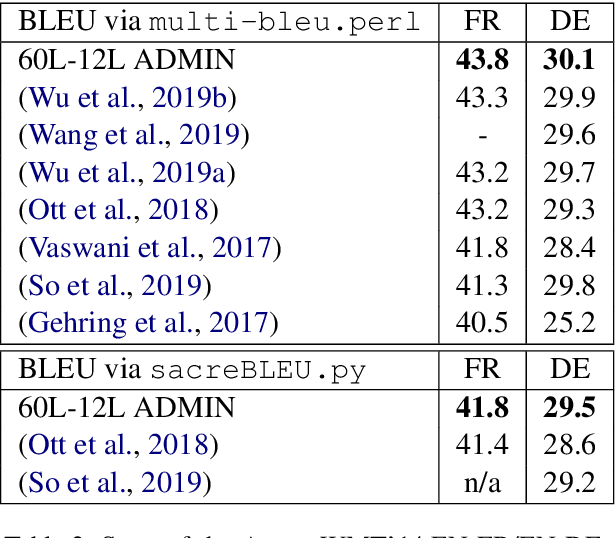
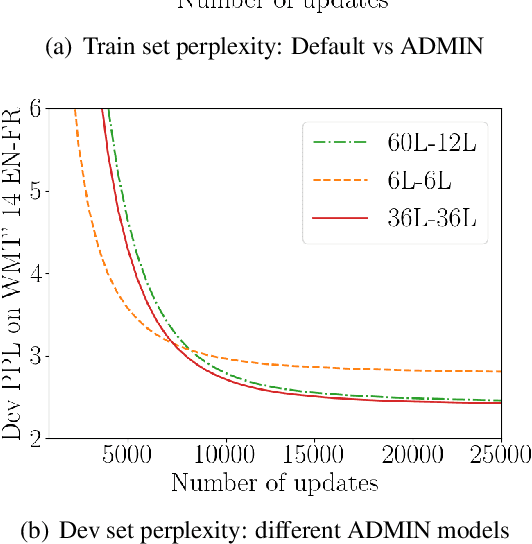
We explore the application of very deep Transformer models for Neural Machine Translation (NMT). Using a simple yet effective initialization technique that stabilizes training, we show that it is feasible to build standard Transformer-based models with up to 60 encoder layers and 12 decoder layers. These deep models outperform their baseline 6-layer counterparts by as much as 2.5 BLEU, and achieve new state-of-the-art benchmark results on WMT14 English-French (43.8 BLEU) and WMT14 English-German (30.1 BLEU).The code and trained models will be publicly available at: https://github.com/namisan/exdeep-nmt.
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Jun 05, 2020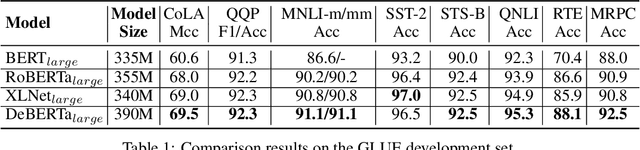
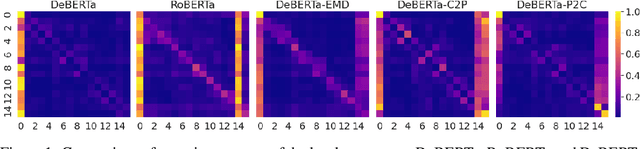
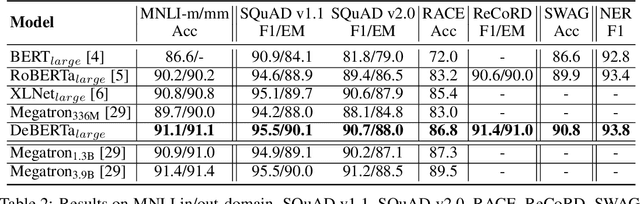
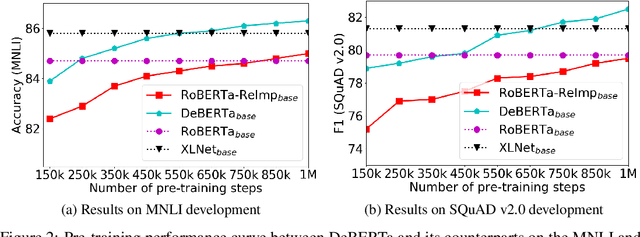
Recent progress in pre-trained neural language models has significantly improved the performance of many natural language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the disentangled attention mechanism, where each word is represented using two vectors that encode its content and position, respectively, and the attention weights among words are computed using disentangled matrices on their contents and relative positions. Second, an enhanced mask decoder is used to replace the output softmax layer to predict the masked tokens for model pretraining. We show that these two techniques significantly improve the efficiency of model pre-training and performance of downstream tasks. Compared to RoBERTa-Large, a DeBERTa model trained on half of the training data performs consistently better on a wide range of NLP tasks, achieving improvements on MNLI by +0.9% (90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%). The DeBERTa code and pre-trained models will be made publicly available at https://github.com/microsoft/DeBERTa.
Adversarial Training for Commonsense Inference
May 17, 2020

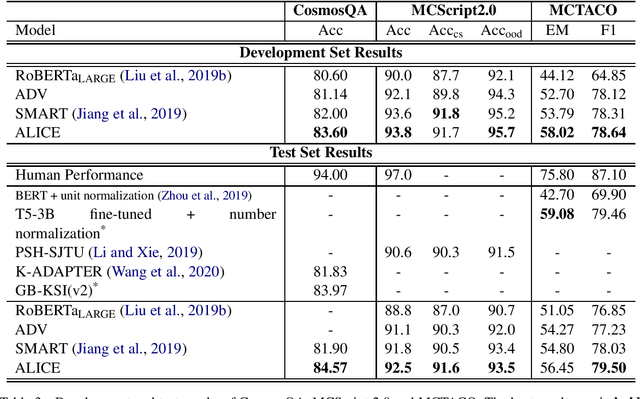
We propose an AdversariaL training algorithm for commonsense InferenCE (ALICE). We apply small perturbations to word embeddings and minimize the resultant adversarial risk to regularize the model. We exploit a novel combination of two different approaches to estimate these perturbations: 1) using the true label and 2) using the model prediction. Without relying on any human-crafted features, knowledge bases, or additional datasets other than the target datasets, our model boosts the fine-tuning performance of RoBERTa, achieving competitive results on multiple reading comprehension datasets that require commonsense inference.
* 6 pages, Accepted to ACL2020 RepL4NLP workshop
Adversarial Training for Large Neural Language Models
Apr 29, 2020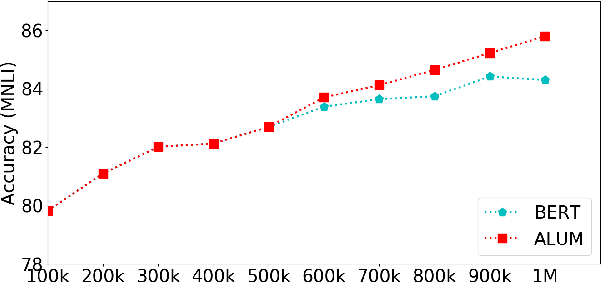

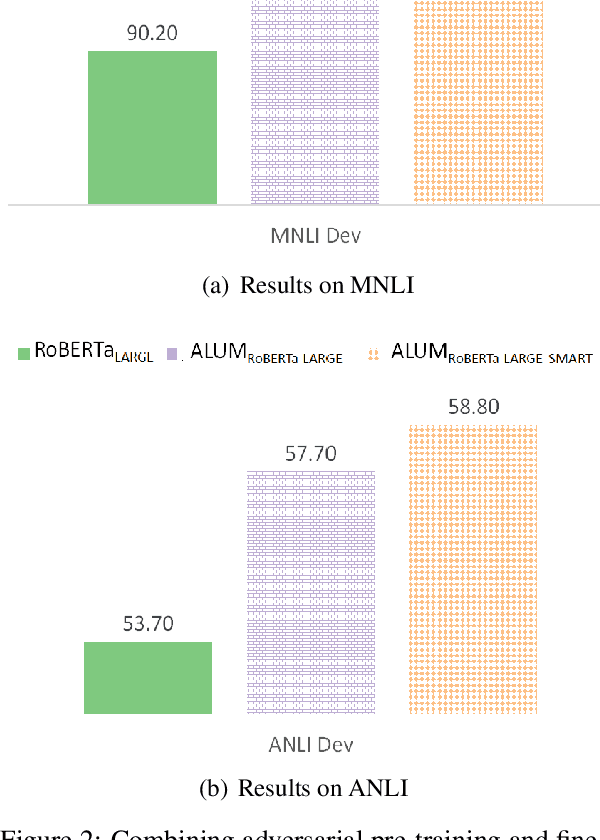
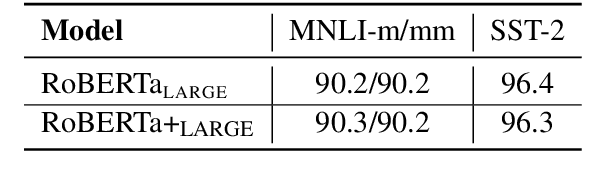
Generalization and robustness are both key desiderata for designing machine learning methods. Adversarial training can enhance robustness, but past work often finds it hurts generalization. In natural language processing (NLP), pre-training large neural language models such as BERT have demonstrated impressive gain in generalization for a variety of tasks, with further improvement from adversarial fine-tuning. However, these models are still vulnerable to adversarial attacks. In this paper, we show that adversarial pre-training can improve both generalization and robustness. We propose a general algorithm ALUM (Adversarial training for large neural LangUage Models), which regularizes the training objective by applying perturbations in the embedding space that maximizes the adversarial loss. We present the first comprehensive study of adversarial training in all stages, including pre-training from scratch, continual pre-training on a well-trained model, and task-specific fine-tuning. ALUM obtains substantial gains over BERT on a wide range of NLP tasks, in both regular and adversarial scenarios. Even for models that have been well trained on extremely large text corpora, such as RoBERTa, ALUM can still produce significant gains from continual pre-training, whereas conventional non-adversarial methods can not. ALUM can be further combined with task-specific fine-tuning to attain additional gains. The ALUM code is publicly available at https://github.com/namisan/mt-dnn.