 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Language Model Pre-training for Natural Language Understanding and Generation
Paper and Code
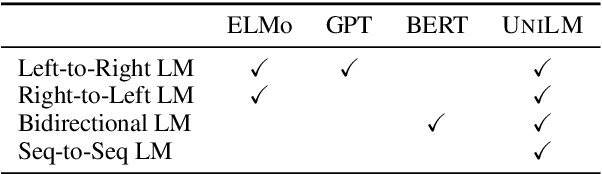
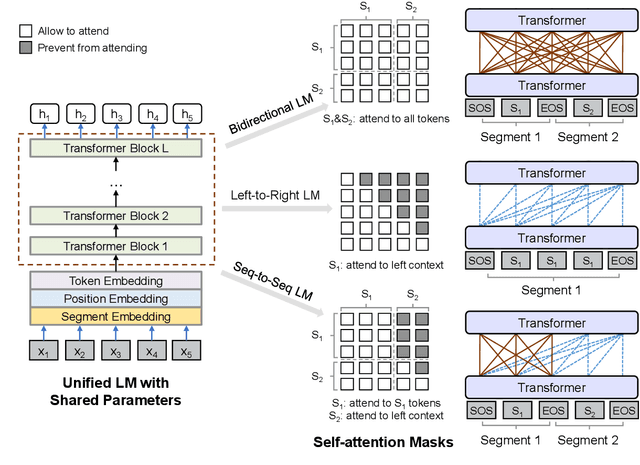


This paper presents a new Unified pre-trained Language Model (UniLM) that can be fine-tuned for both natural language understanding and generation tasks. The model is pre-trained using three types of language modeling objectives: unidirectional (both left-to-right and right-to-left), bidirectional, and sequence-to-sequence prediction. The unified modeling is achieved by employing a shared Transformer network and utilizing specific self-attention masks to control what context the prediction conditions on. We can fine-tune UniLM as a unidirectional decoder, a bidirectional encoder, or a sequence-to-sequence model to support various downstream natural language understanding and generation tasks. UniLM compares favorably with BERT on the GLUE benchmark, and the SQuAD 2.0 and CoQA question answering tasks. Moreover, our model achieves new state-of-the-art results on three natural language generation tasks, including improving the CNN/DailyMail abstractive summarization ROUGE-L to 40.63 (2.16 absolute improvement), pushing the CoQA generative question answering F1 score to 82.5 (37.1 absolute improvement), and the SQuAD question generation BLEU-4 to 22.88 (6.50 absolute improvement).