 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaodan Liang
Dynamic Slimmable Network
Mar 24, 2021
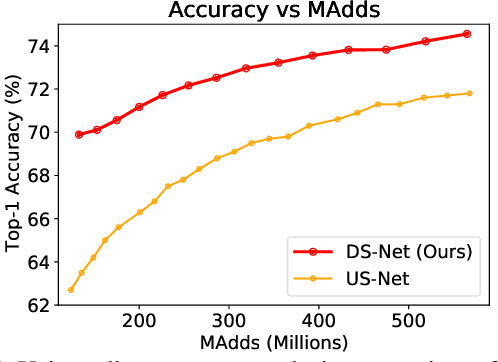

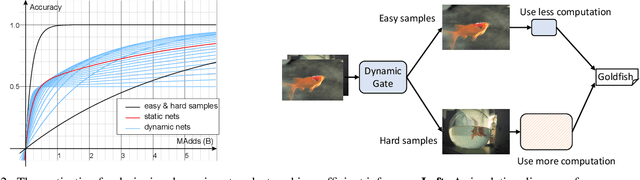
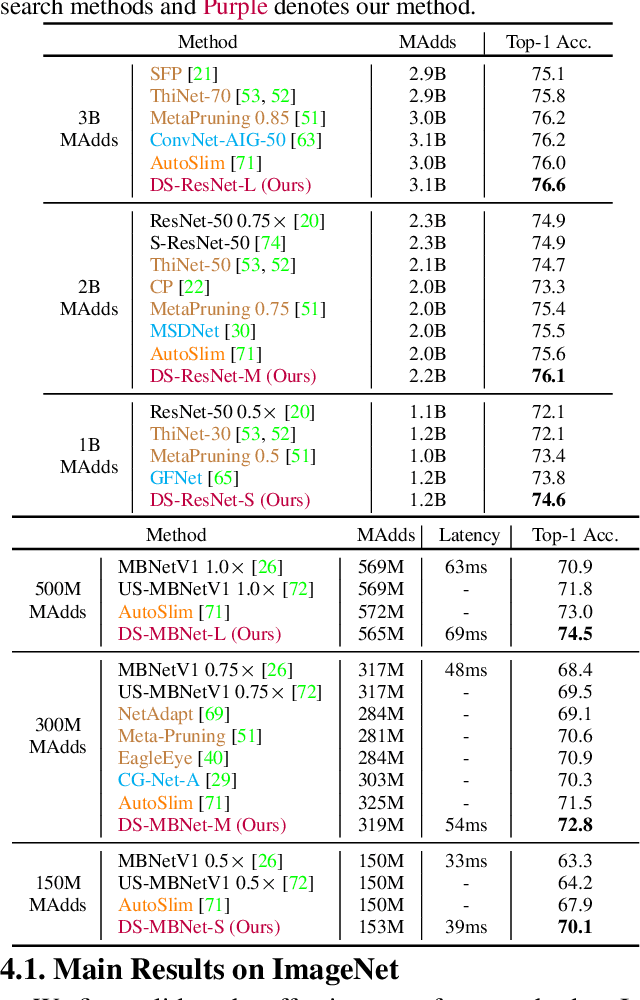
Current dynamic networks and dynamic pruning methods have shown their promising capability in reducing theoretical computation complexity. However, dynamic sparse patterns on convolutional filters fail to achieve actual acceleration in real-world implementation, due to the extra burden of indexing, weight-copying, or zero-masking. Here, we explore a dynamic network slimming regime, named Dynamic Slimmable Network (DS-Net), which aims to achieve good hardware-efficiency via dynamically adjusting filter numbers of networks at test time with respect to different inputs, while keeping filters stored statically and contiguously in hardware to prevent the extra burden. Our DS-Net is empowered with the ability of dynamic inference by the proposed double-headed dynamic gate that comprises an attention head and a slimming head to predictively adjust network width with negligible extra computation cost. To ensure generality of each candidate architecture and the fairness of gate, we propose a disentangled two-stage training scheme inspired by one-shot NAS. In the first stage, a novel training technique for weight-sharing networks named In-place Ensemble Bootstrapping is proposed to improve the supernet training efficacy. In the second stage, Sandwich Gate Sparsification is proposed to assist the gate training by identifying easy and hard samples in an online way. Extensive experiments demonstrate our DS-Net consistently outperforms its static counterparts as well as state-of-the-art static and dynamic model compression methods by a large margin (up to 5.9%). Typically, DS-Net achieves 2-4x computation reduction and 1.62x real-world acceleration over ResNet-50 and MobileNet with minimal accuracy drops on ImageNet. Code release: https://github.com/changlin31/DS-Net .
A Data-Centric Framework for Composable NLP Workflows
Mar 03, 2021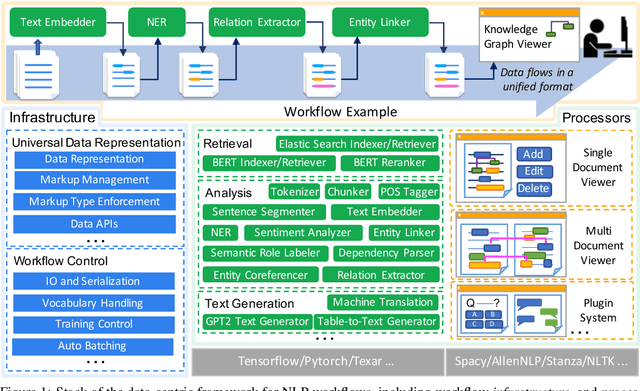
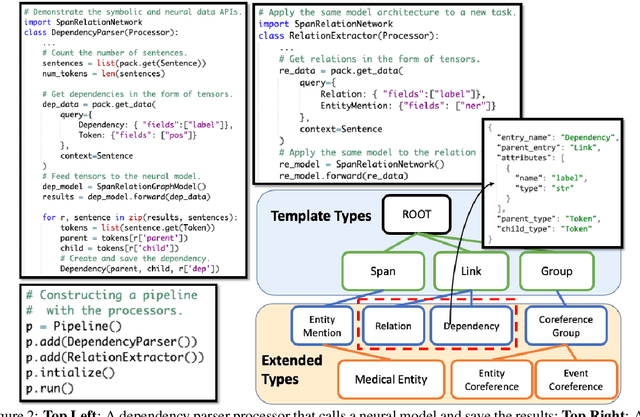
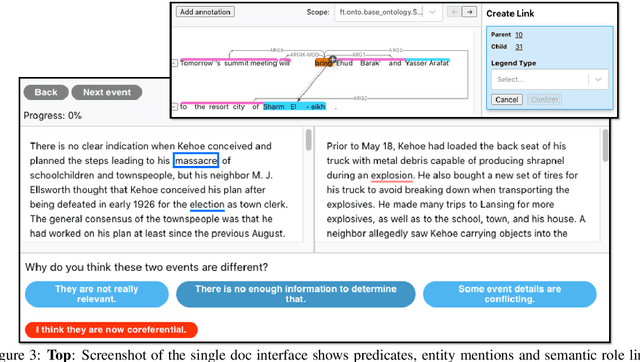
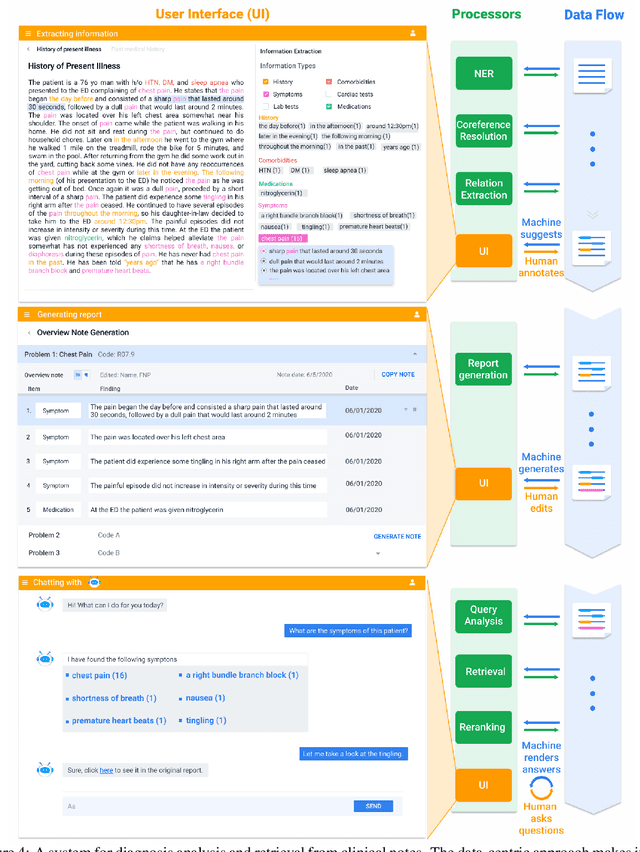
Empirical natural language processing (NLP) systems in application domains (e.g., healthcare, finance, education) involve interoperation among multiple components, ranging from data ingestion, human annotation, to text retrieval, analysis, generation, and visualization. We establish a unified open-source framework to support fast development of such sophisticated NLP workflows in a composable manner. The framework introduces a uniform data representation to encode heterogeneous results by a wide range of NLP tasks. It offers a large repository of processors for NLP tasks, visualization, and annotation, which can be easily assembled with full interoperability under the unified representation. The highly extensible framework allows plugging in custom processors from external off-the-shelf NLP and deep learning libraries. The whole framework is delivered through two modularized yet integratable open-source projects, namely Forte1 (for workflow infrastructure and NLP function processors) and Stave2 (for user interaction, visualization, and annotation).
SparseBERT: Rethinking the Importance Analysis in Self-attention
Feb 25, 2021
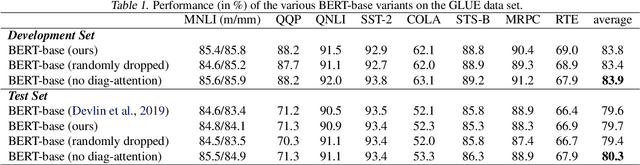
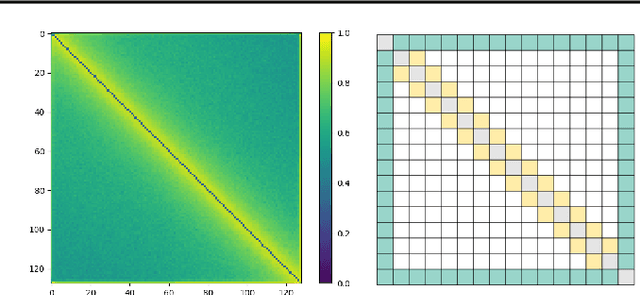
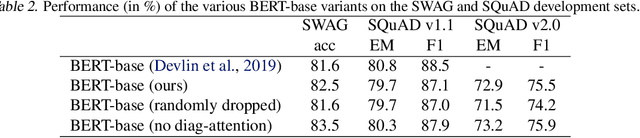
Transformer-based models are popular for natural language processing (NLP) tasks due to its powerful capacity. As the core component, self-attention module has aroused widespread interests. Attention map visualization of a pre-trained model is one direct method for understanding self-attention mechanism and some common patterns are observed in visualization. Based on these patterns, a series of efficient transformers are proposed with corresponding sparse attention masks. Besides above empirical results, universal approximability of Transformer-based models is also discovered from a theoretical perspective. However, above understanding and analysis of self-attention is based on a pre-trained model. To rethink the importance analysis in self-attention, we delve into dynamics of attention matrix importance during pre-training. One of surprising results is that the diagonal elements in the attention map are the most unimportant compared with other attention positions and we also provide a proof to show these elements can be removed without damaging the model performance. Furthermore, we propose a Differentiable Attention Mask (DAM) algorithm, which can be also applied in guidance of SparseBERT design further. The extensive experiments verify our interesting findings and illustrate the effect of our proposed algorithm.
Loss Function Discovery for Object Detection via Convergence-Simulation Driven Search
Feb 09, 2021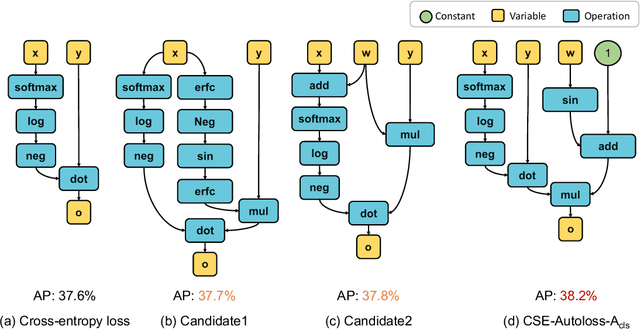
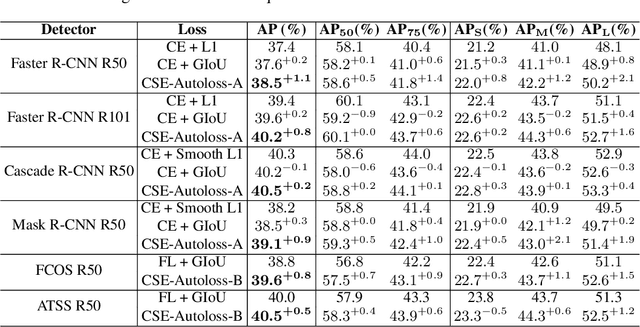
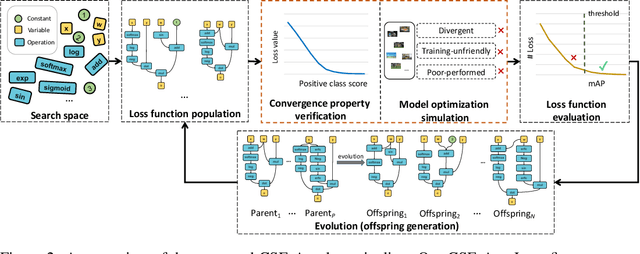

Designing proper loss functions for vision tasks has been a long-standing research direction to advance the capability of existing models. For object detection, the well-established classification and regression loss functions have been carefully designed by considering diverse learning challenges. Inspired by the recent progress in network architecture search, it is interesting to explore the possibility of discovering new loss function formulations via directly searching the primitive operation combinations. So that the learned losses not only fit for diverse object detection challenges to alleviate huge human efforts, but also have better alignment with evaluation metric and good mathematical convergence property. Beyond the previous auto-loss works on face recognition and image classification, our work makes the first attempt to discover new loss functions for the challenging object detection from primitive operation levels. We propose an effective convergence-simulation driven evolutionary search algorithm, called CSE-Autoloss, for speeding up the search progress by regularizing the mathematical rationality of loss candidates via convergence property verification and model optimization simulation. CSE-Autoloss involves the search space that cover a wide range of the possible variants of existing losses and discovers best-searched loss function combination within a short time (around 1.5 wall-clock days). We conduct extensive evaluations of loss function search on popular detectors and validate the good generalization capability of searched losses across diverse architectures and datasets. Our experiments show that the best-discovered loss function combinations outperform default combinations by 1.1% and 0.8% in terms of mAP for two-stage and one-stage detectors on COCO respectively. Our searched losses are available at https://github.com/PerdonLiu/CSE-Autoloss.
UPDeT: Universal Multi-agent Reinforcement Learning via Policy Decoupling with Transformers
Feb 07, 2021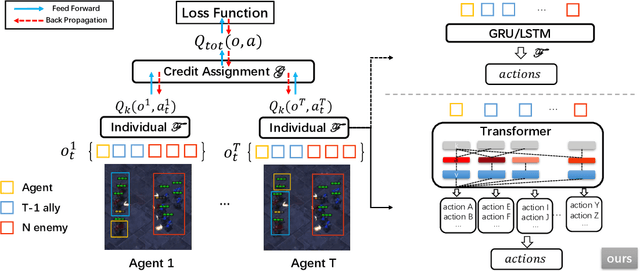
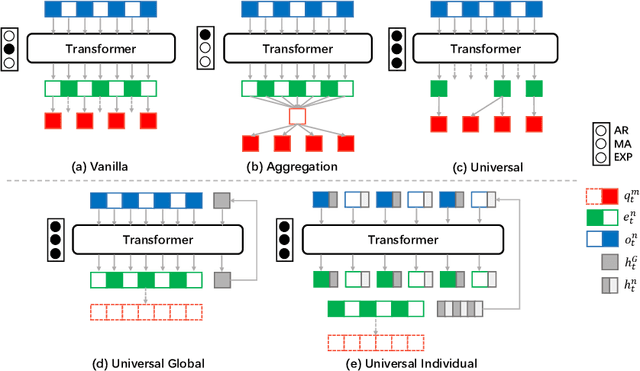
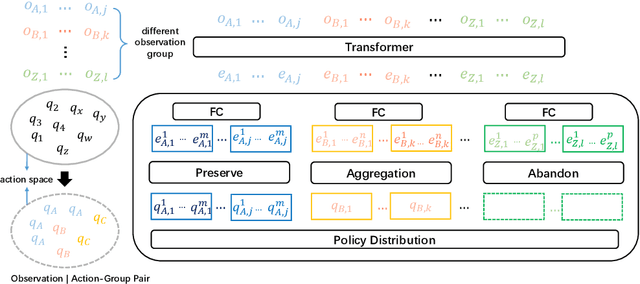
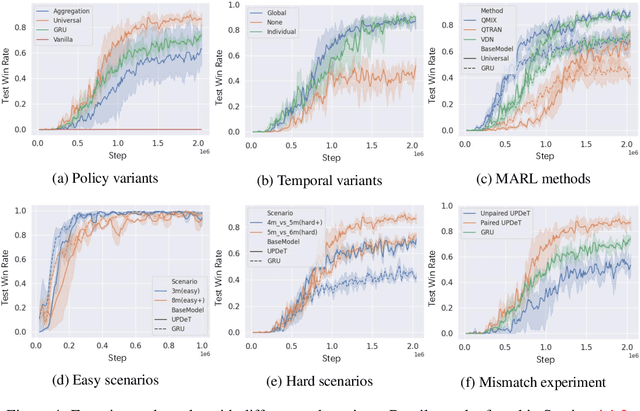
Recent advances in multi-agent reinforcement learning have been largely limited in training one model from scratch for every new task. The limitation is due to the restricted model architecture related to fixed input and output dimensions. This hinders the experience accumulation and transfer of the learned agent over tasks with diverse levels of difficulty (e.g. 3 vs 3 or 5 vs 6 multi-agent games). In this paper, we make the first attempt to explore a universal multi-agent reinforcement learning pipeline, designing one single architecture to fit tasks with the requirement of different observation and action configurations. Unlike previous RNN-based models, we utilize a transformer-based model to generate a flexible policy by decoupling the policy distribution from the intertwined input observation with an importance weight measured by the merits of the self-attention mechanism. Compared to a standard transformer block, the proposed model, named as Universal Policy Decoupling Transformer (UPDeT), further relaxes the action restriction and makes the multi-agent task's decision process more explainable. UPDeT is general enough to be plugged into any multi-agent reinforcement learning pipeline and equip them with strong generalization abilities that enables the handling of multiple tasks at a time. Extensive experiments on large-scale SMAC multi-agent competitive games demonstrate that the proposed UPDeT-based multi-agent reinforcement learning achieves significant results relative to state-of-the-art approaches, demonstrating advantageous transfer capability in terms of both performance and training speed (10 times faster).
GTAE: Graph-Transformer based Auto-Encoders for Linguistic-Constrained Text Style Transfer
Feb 01, 2021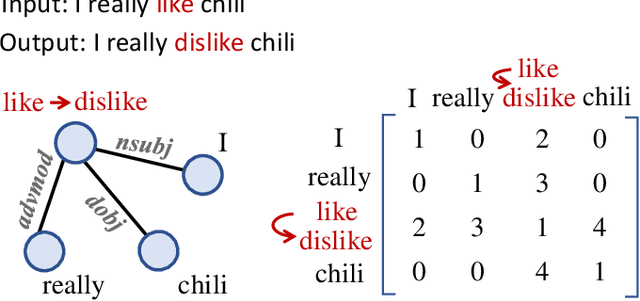
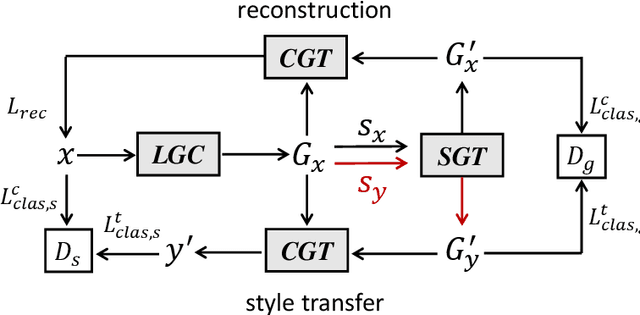
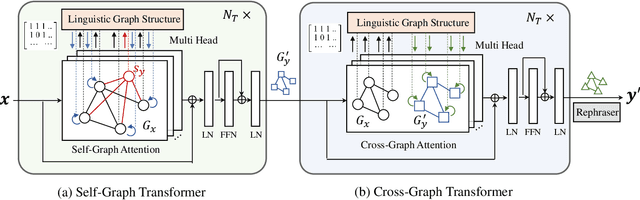
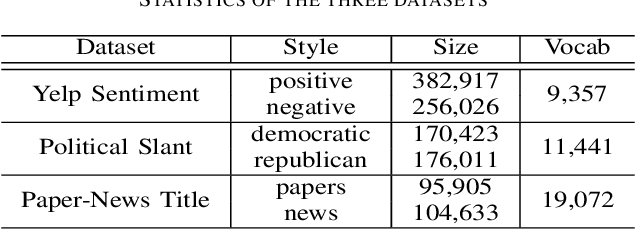
Non-parallel text style transfer has attracted increasing research interests in recent years. Despite successes in transferring the style based on the encoder-decoder framework, current approaches still lack the ability to preserve the content and even logic of original sentences, mainly due to the large unconstrained model space or too simplified assumptions on latent embedding space. Since language itself is an intelligent product of humans with certain grammars and has a limited rule-based model space by its nature, relieving this problem requires reconciling the model capacity of deep neural networks with the intrinsic model constraints from human linguistic rules. To this end, we propose a method called Graph Transformer based Auto Encoder (GTAE), which models a sentence as a linguistic graph and performs feature extraction and style transfer at the graph level, to maximally retain the content and the linguistic structure of original sentences. Quantitative experiment results on three non-parallel text style transfer tasks show that our model outperforms state-of-the-art methods in content preservation, while achieving comparable performance on transfer accuracy and sentence naturalness.
Graphonomy: Universal Image Parsing via Graph Reasoning and Transfer
Jan 26, 2021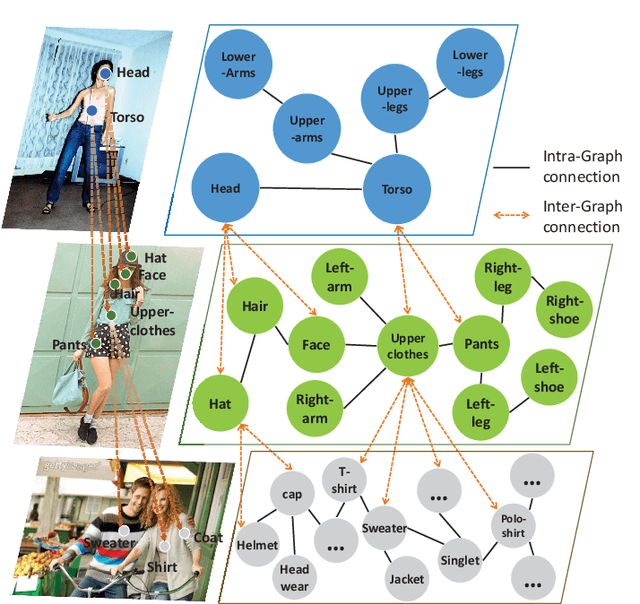

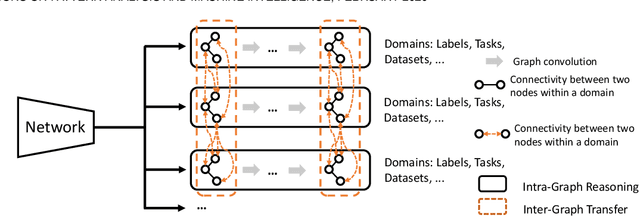
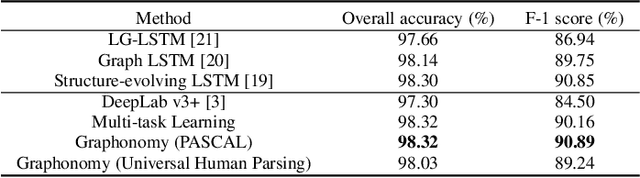
Prior highly-tuned image parsing models are usually studied in a certain domain with a specific set of semantic labels and can hardly be adapted into other scenarios (e.g., sharing discrepant label granularity) without extensive re-training. Learning a single universal parsing model by unifying label annotations from different domains or at various levels of granularity is a crucial but rarely addressed topic. This poses many fundamental learning challenges, e.g., discovering underlying semantic structures among different label granularity or mining label correlation across relevant tasks. To address these challenges, we propose a graph reasoning and transfer learning framework, named "Graphonomy", which incorporates human knowledge and label taxonomy into the intermediate graph representation learning beyond local convolutions. In particular, Graphonomy learns the global and structured semantic coherency in multiple domains via semantic-aware graph reasoning and transfer, enforcing the mutual benefits of the parsing across domains (e.g., different datasets or co-related tasks). The Graphonomy includes two iterated modules: Intra-Graph Reasoning and Inter-Graph Transfer modules. The former extracts the semantic graph in each domain to improve the feature representation learning by propagating information with the graph; the latter exploits the dependencies among the graphs from different domains for bidirectional knowledge transfer. We apply Graphonomy to two relevant but different image understanding research topics: human parsing and panoptic segmentation, and show Graphonomy can handle both of them well via a standard pipeline against current state-of-the-art approaches. Moreover, some extra benefit of our framework is demonstrated, e.g., generating the human parsing at various levels of granularity by unifying annotations across different datasets.
Unifying Relational Sentence Generation and Retrieval for Medical Image Report Composition
Jan 09, 2021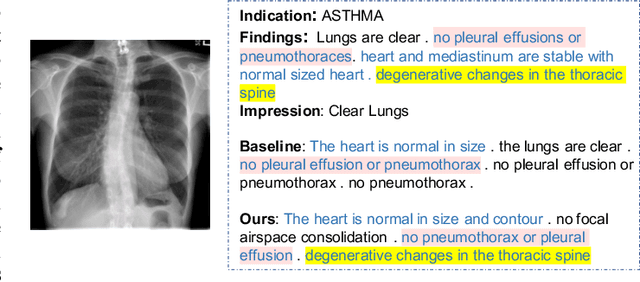
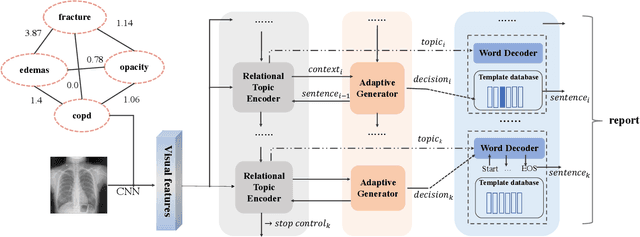
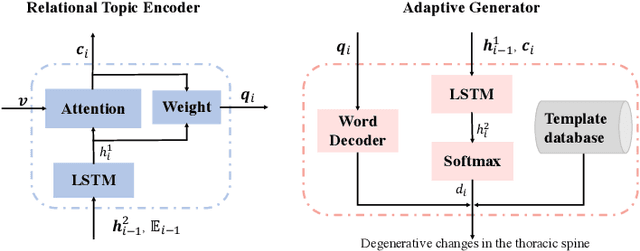
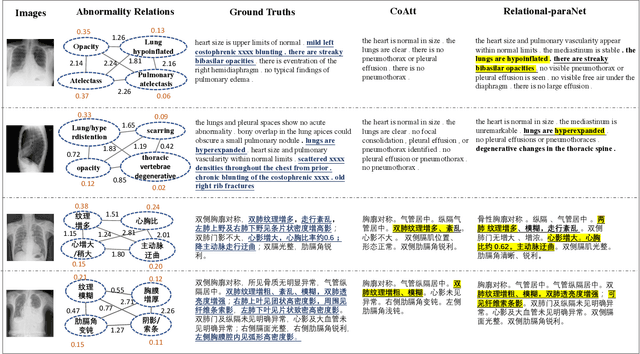
Beyond generating long and topic-coherent paragraphs in traditional captioning tasks, the medical image report composition task poses more task-oriented challenges by requiring both the highly-accurate medical term diagnosis and multiple heterogeneous forms of information including impression and findings. Current methods often generate the most common sentences due to dataset bias for individual case, regardless of whether the sentences properly capture key entities and relationships. Such limitations severely hinder their applicability and generalization capability in medical report composition where the most critical sentences lie in the descriptions of abnormal diseases that are relatively rare. Moreover, some medical terms appearing in one report are often entangled with each other and co-occurred, e.g. symptoms associated with a specific disease. To enforce the semantic consistency of medical terms to be incorporated into the final reports and encourage the sentence generation for rare abnormal descriptions, we propose a novel framework that unifies template retrieval and sentence generation to handle both common and rare abnormality while ensuring the semantic-coherency among the detected medical terms. Specifically, our approach exploits hybrid-knowledge co-reasoning: i) explicit relationships among all abnormal medical terms to induce the visual attention learning and topic representation encoding for better topic-oriented symptoms descriptions; ii) adaptive generation mode that changes between the template retrieval and sentence generation according to a contextual topic encoder. Experimental results on two medical report benchmarks demonstrate the superiority of the proposed framework in terms of both human and metrics evaluation.