 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseBERT: Rethinking the Importance Analysis in Self-attention
Paper and Code

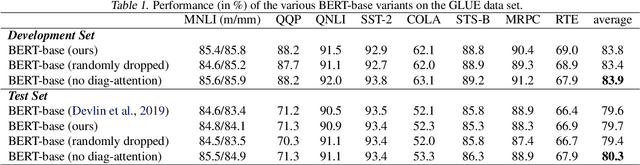
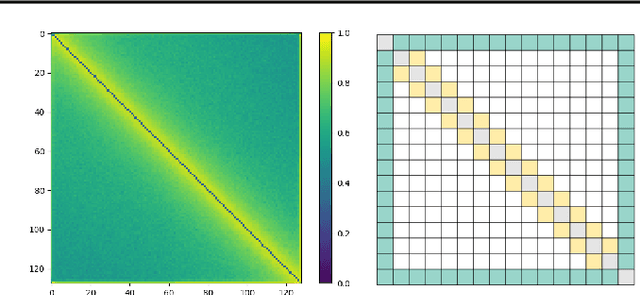
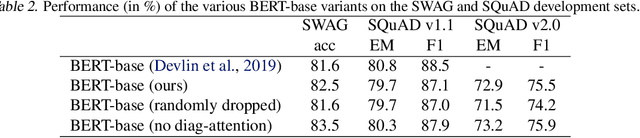
Transformer-based models are popular for natural language processing (NLP) tasks due to its powerful capacity. As the core component, self-attention module has aroused widespread interests. Attention map visualization of a pre-trained model is one direct method for understanding self-attention mechanism and some common patterns are observed in visualization. Based on these patterns, a series of efficient transformers are proposed with corresponding sparse attention masks. Besides above empirical results, universal approximability of Transformer-based models is also discovered from a theoretical perspective. However, above understanding and analysis of self-attention is based on a pre-trained model. To rethink the importance analysis in self-attention, we delve into dynamics of attention matrix importance during pre-training. One of surprising results is that the diagonal elements in the attention map are the most unimportant compared with other attention positions and we also provide a proof to show these elements can be removed without damaging the model performance. Furthermore, we propose a Differentiable Attention Mask (DAM) algorithm, which can be also applied in guidance of SparseBERT design further. The extensive experiments verify our interesting findings and illustrate the effect of our proposed algorithm.