 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Language Navigation Pretraining via Prompt-based Environmental Self-exploration
Mar 08, 2022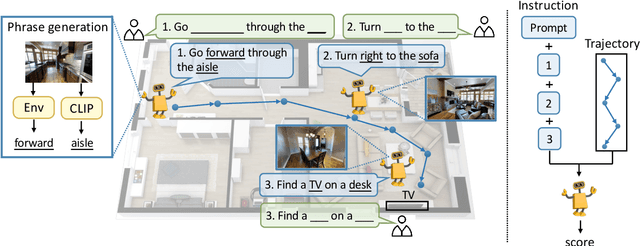

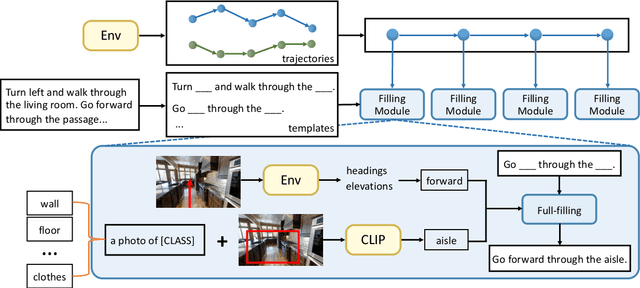
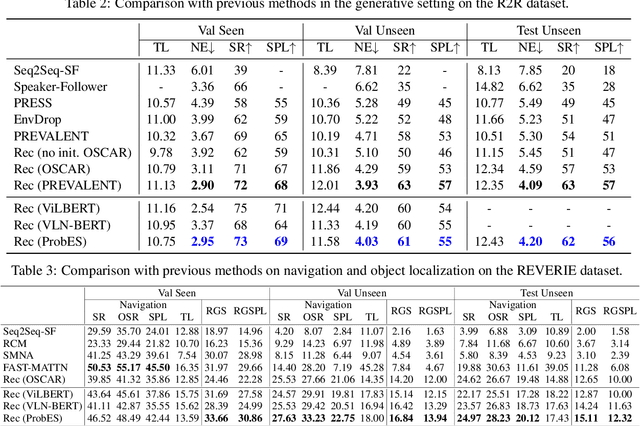
Vision-language navigation (VLN) is a challenging task due to its large searching space in the environment. To address this problem, previous works have proposed some methods of fine-tuning a large model that pretrained on large-scale datasets. However, the conventional fine-tuning methods require extra human-labeled navigation data and lack self-exploration capabilities in environments, which hinders their generalization of unseen scenes. To improve the ability of fast cross-domain adaptation, we propose Prompt-based Environmental Self-exploration (ProbES), which can self-explore the environments by sampling trajectories and automatically generates structured instructions via a large-scale cross-modal pretrained model (CLIP). Our method fully utilizes the knowledge learned from CLIP to build an in-domain dataset by self-exploration without human labeling. Unlike the conventional approach of fine-tuning, we introduce prompt-based learning to achieve fast adaptation for language embeddings, which substantially improves the learning efficiency by leveraging prior knowledge. By automatically synthesizing trajectory-instruction pairs in any environment without human supervision and efficient prompt-based learning, our model can adapt to diverse vision-language navigation tasks, including VLN and REVERIE. Both qualitative and quantitative results show that our ProbES significantly improves the generalization ability of the navigation model.
Modern Augmented Reality: Applications, Trends, and Future Directions
Feb 24, 2022



Augmented reality (AR) is one of the relatively old, yet trending areas in the intersection of computer vision and computer graphics with numerous applications in several areas, from gaming and entertainment, to education and healthcare. Although it has been around for nearly fifty years, it has seen a lot of interest by the research community in the recent years, mainly because of the huge success of deep learning models for various computer vision and AR applications, which made creating new generations of AR technologies possible. This work tries to provide an overview of modern augmented reality, from both application-level and technical perspective. We first give an overview of main AR applications, grouped into more than ten categories. We then give an overview of around 100 recent promising machine learning based works developed for AR systems, such as deep learning works for AR shopping (clothing, makeup), AR based image filters (such as Snapchat's lenses), AR animations, and more. In the end we discuss about some of the current challenges in AR domain, and the future directions in this area.
Revisiting Over-smoothing in BERT from the Perspective of Graph
Feb 17, 2022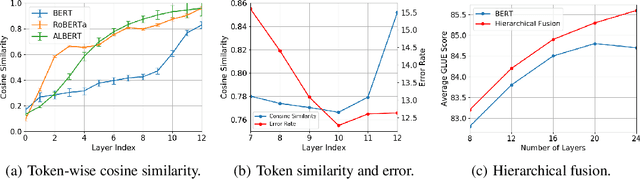
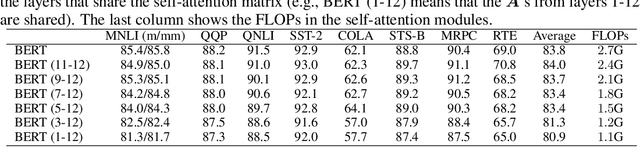
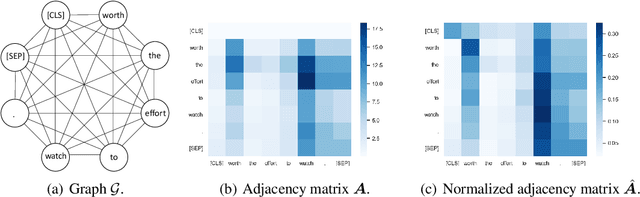
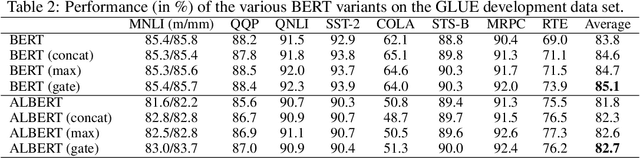
Recently over-smoothing phenomenon of Transformer-based models is observed in both vision and language fields. However, no existing work has delved deeper to further investigate the main cause of this phenomenon. In this work, we make the attempt to analyze the over-smoothing problem from the perspective of graph, where such problem was first discovered and explored. Intuitively, the self-attention matrix can be seen as a normalized adjacent matrix of a corresponding graph. Based on the above connection, we provide some theoretical analysis and find that layer normalization plays a key role in the over-smoothing issue of Transformer-based models. Specifically, if the standard deviation of layer normalization is sufficiently large, the output of Transformer stacks will converge to a specific low-rank subspace and result in over-smoothing. To alleviate the over-smoothing problem, we consider hierarchical fusion strategies, which combine the representations from different layers adaptively to make the output more diverse. Extensive experiment results on various data sets illustrate the effect of our fusion method.
Exploring Inter-Channel Correlation for Diversity-preserved KnowledgeDistillation
Feb 08, 2022

Knowledge Distillation has shown very promising abil-ity in transferring learned representation from the largermodel (teacher) to the smaller one (student).Despitemany efforts, prior methods ignore the important role ofretaining inter-channel correlation of features, leading tothe lack of capturing intrinsic distribution of the featurespace and sufficient diversity properties of features in theteacher network.To solve the issue, we propose thenovel Inter-Channel Correlation for Knowledge Distillation(ICKD), with which the diversity and homology of the fea-ture space of the student network can align with that ofthe teacher network. The correlation between these twochannels is interpreted as diversity if they are irrelevantto each other, otherwise homology. Then the student isrequired to mimic the correlation within its own embed-ding space. In addition, we introduce the grid-level inter-channel correlation, making it capable of dense predictiontasks. Extensive experiments on two vision tasks, includ-ing ImageNet classification and Pascal VOC segmentation,demonstrate the superiority of our ICKD, which consis-tently outperforms many existing methods, advancing thestate-of-the-art in the fields of Knowledge Distillation. Toour knowledge, we are the first method based on knowl-edge distillation boosts ResNet18 beyond 72% Top-1 ac-curacy on ImageNet classification. Code is available at:https://github.com/ADLab-AutoDrive/ICKD.
Contrastive Instruction-Trajectory Learning for Vision-Language Navigation
Dec 09, 2021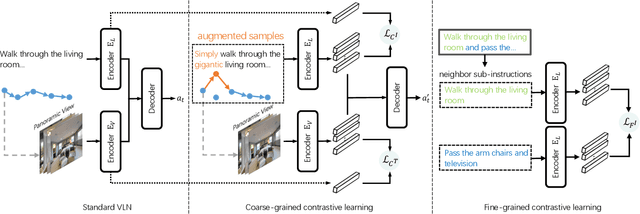
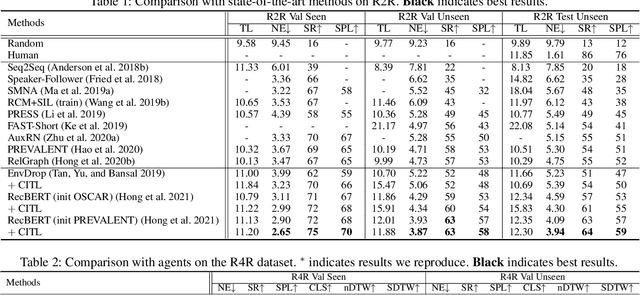
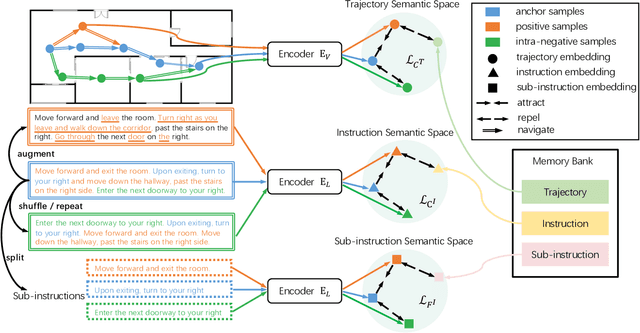
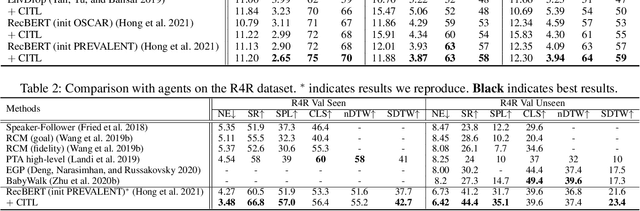
The vision-language navigation (VLN) task requires an agent to reach a target with the guidance of natural language instruction. Previous works learn to navigate step-by-step following an instruction. However, these works may fail to discriminate the similarities and discrepancies across instruction-trajectory pairs and ignore the temporal continuity of sub-instructions. These problems hinder agents from learning distinctive vision-and-language representations, harming the robustness and generalizability of the navigation policy. In this paper, we propose a Contrastive Instruction-Trajectory Learning (CITL) framework that explores invariance across similar data samples and variance across different ones to learn distinctive representations for robust navigation. Specifically, we propose: (1) a coarse-grained contrastive learning objective to enhance vision-and-language representations by contrasting semantics of full trajectory observations and instructions, respectively; (2) a fine-grained contrastive learning objective to perceive instructions by leveraging the temporal information of the sub-instructions; (3) a pairwise sample-reweighting mechanism for contrastive learning to mine hard samples and hence mitigate the influence of data sampling bias in contrastive learning. Our CITL can be easily integrated with VLN backbones to form a new learning paradigm and achieve better generalizability in unseen environments. Extensive experiments show that the model with CITL surpasses the previous state-of-the-art methods on R2R, R4R, and RxR.
Towards Scalable Unpaired Virtual Try-On via Patch-Routed Spatially-Adaptive GAN
Nov 20, 2021
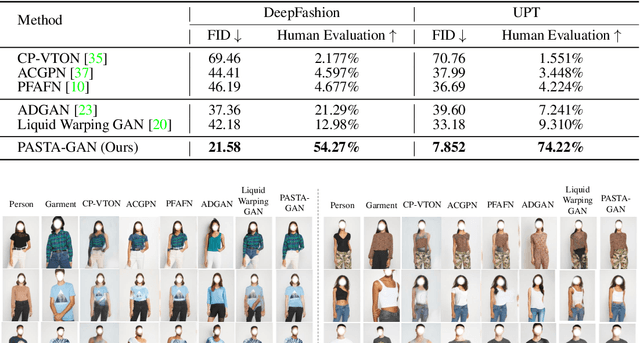
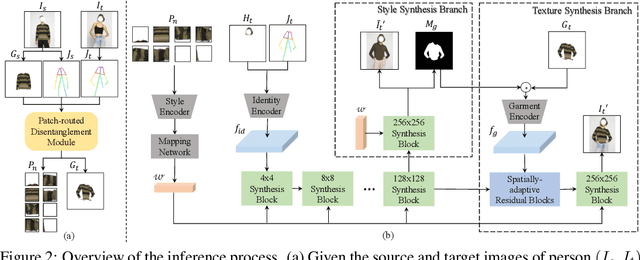

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. Yet, as most try-on approaches fit in-shop garments onto a target person, they require the laborious and restrictive construction of a paired training dataset, severely limiting their scalability. While a few recent works attempt to transfer garments directly from one person to another, alleviating the need to collect paired datasets, their performance is impacted by the lack of paired (supervised) information. In particular, disentangling style and spatial information of the garment becomes a challenge, which existing methods either address by requiring auxiliary data or extensive online optimization procedures, thereby still inhibiting their scalability. To achieve a \emph{scalable} virtual try-on system that can transfer arbitrary garments between a source and a target person in an unsupervised manner, we thus propose a texture-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN (PASTA-GAN), that facilitates real-world unpaired virtual try-on. Specifically, to disentangle the style and spatial information of each garment, PASTA-GAN consists of an innovative patch-routed disentanglement module for successfully retaining garment texture and shape characteristics. Guided by the source person keypoints, the patch-routed disentanglement module first decouples garments into normalized patches, thus eliminating the inherent spatial information of the garment, and then reconstructs the normalized patches to the warped garment complying with the target person pose. Given the warped garment, PASTA-GAN further introduces novel spatially-adaptive residual blocks that guide the generator to synthesize more realistic garment details.
FILIP: Fine-grained Interactive Language-Image Pre-Training
Nov 09, 2021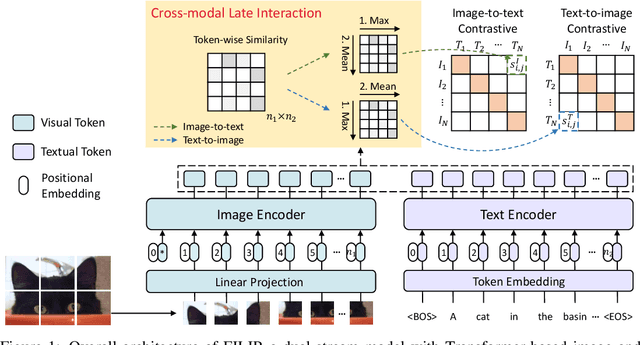
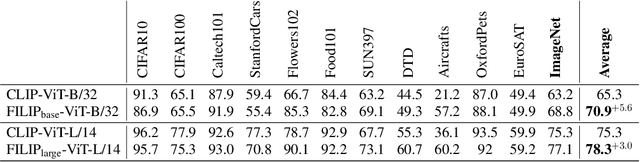
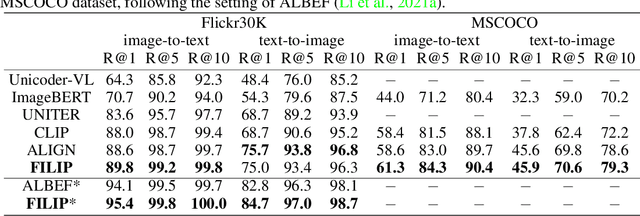

Unsupervised large-scale vision-language pre-training has shown promising advances on various downstream tasks. Existing methods often model the cross-modal interaction either via the similarity of the global feature of each modality which misses sufficient information, or finer-grained interactions using cross/self-attention upon visual and textual tokens. However, cross/self-attention suffers from inferior efficiency in both training and inference. In this paper, we introduce a large-scale Fine-grained Interactive Language-Image Pre-training (FILIP) to achieve finer-level alignment through a cross-modal late interaction mechanism, which uses a token-wise maximum similarity between visual and textual tokens to guide the contrastive objective. FILIP successfully leverages the finer-grained expressiveness between image patches and textual words by modifying only contrastive loss, while simultaneously gaining the ability to pre-compute image and text representations offline at inference, keeping both large-scale training and inference efficient. Furthermore, we construct a new large-scale image-text pair dataset called FILIP300M for pre-training. Experiments show that FILIP achieves state-of-the-art performance on multiple downstream vision-language tasks including zero-shot image classification and image-text retrieval. The visualization on word-patch alignment further shows that FILIP can learn meaningful fine-grained features with promising localization ability.
IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning
Nov 07, 2021
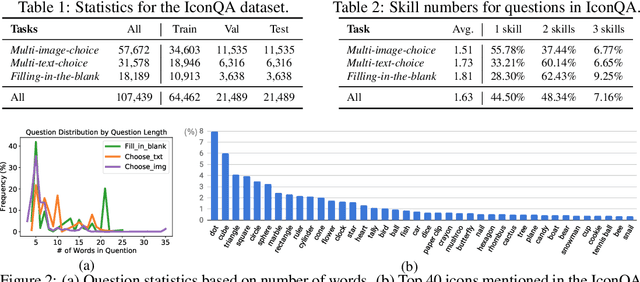
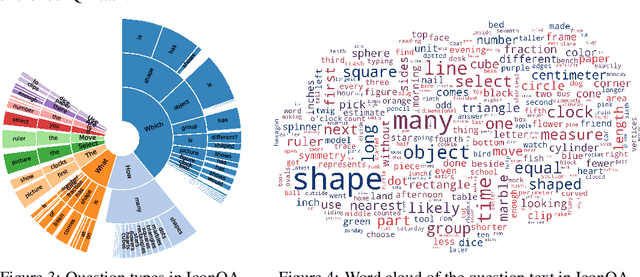

Current visual question answering (VQA) tasks mainly consider answering human-annotated questions for natural images. However, aside from natural images, abstract diagrams with semantic richness are still understudied in visual understanding and reasoning research. In this work, we introduce a new challenge of Icon Question Answering (IconQA) with the goal of answering a question in an icon image context. We release IconQA, a large-scale dataset that consists of 107,439 questions and three sub-tasks: multi-image-choice, multi-text-choice, and filling-in-the-blank. The IconQA dataset is inspired by real-world diagram word problems that highlight the importance of abstract diagram understanding and comprehensive cognitive reasoning. Thus, IconQA requires not only perception skills like object recognition and text understanding, but also diverse cognitive reasoning skills, such as geometric reasoning, commonsense reasoning, and arithmetic reasoning. To facilitate potential IconQA models to learn semantic representations for icon images, we further release an icon dataset Icon645 which contains 645,687 colored icons on 377 classes. We conduct extensive user studies and blind experiments and reproduce a wide range of advanced VQA methods to benchmark the IconQA task. Also, we develop a strong IconQA baseline Patch-TRM that applies a pyramid cross-modal Transformer with input diagram embeddings pre-trained on the icon dataset. IconQA and Icon645 are available at https://iconqa.github.io.
UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model
Oct 28, 2021

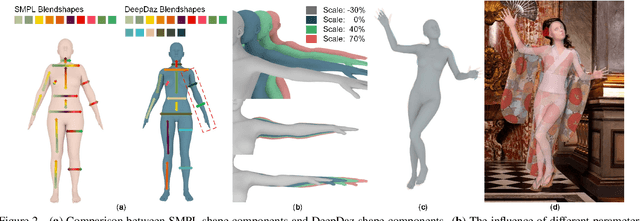
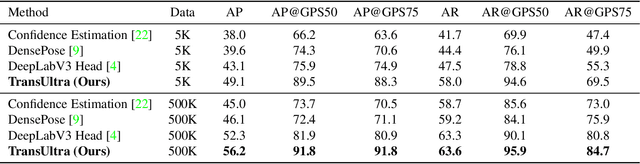
Recovering dense human poses from images plays a critical role in establishing an image-to-surface correspondence between RGB images and the 3D surface of the human body, serving the foundation of rich real-world applications, such as virtual humans, monocular-to-3d reconstruction. However, the popular DensePose-COCO dataset relies on a sophisticated manual annotation system, leading to severe limitations in acquiring the denser and more accurate annotated pose resources. In this work, we introduce a new 3D human-body model with a series of decoupled parameters that could freely control the generation of the body. Furthermore, we build a data generation system based on this decoupling 3D model, and construct an ultra dense synthetic benchmark UltraPose, containing around 1.3 billion corresponding points. Compared to the existing manually annotated DensePose-COCO dataset, the synthetic UltraPose has ultra dense image-to-surface correspondences without annotation cost and error. Our proposed UltraPose provides the largest benchmark and data resources for lifting the model capability in predicting more accurate dense poses. To promote future researches in this field, we also propose a transformer-based method to model the dense correspondence between 2D and 3D worlds. The proposed model trained on synthetic UltraPose can be applied to real-world scenarios, indicating the effectiveness of our benchmark and model.
* Accepted to ICCV 2021
Image Comes Dancing with Collaborative Parsing-Flow Video Synthesis
Oct 28, 2021
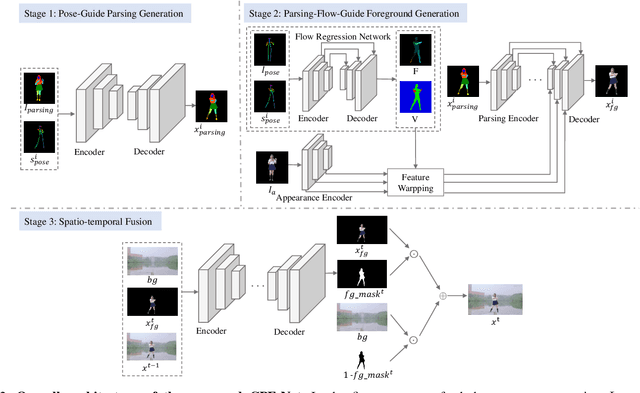


Transferring human motion from a source to a target person poses great potential in computer vision and graphics applications. A crucial step is to manipulate sequential future motion while retaining the appearance characteristic.Previous work has either relied on crafted 3D human models or trained a separate model specifically for each target person, which is not scalable in practice.This work studies a more general setting, in which we aim to learn a single model to parsimoniously transfer motion from a source video to any target person given only one image of the person, named as Collaborative Parsing-Flow Network (CPF-Net). The paucity of information regarding the target person makes the task particularly challenging to faithfully preserve the appearance in varying designated poses. To address this issue, CPF-Net integrates the structured human parsing and appearance flow to guide the realistic foreground synthesis which is merged into the background by a spatio-temporal fusion module. In particular, CPF-Net decouples the problem into stages of human parsing sequence generation, foreground sequence generation and final video generation. The human parsing generation stage captures both the pose and the body structure of the target. The appearance flow is beneficial to keep details in synthesized frames. The integration of human parsing and appearance flow effectively guides the generation of video frames with realistic appearance. Finally, the dedicated designed fusion network ensure the temporal coherence. We further collect a large set of human dancing videos to push forward this research field. Both quantitative and qualitative results show our method substantially improves over previous approaches and is able to generate appealing and photo-realistic target videos given any input person image. All source code and dataset will be released at https://github.com/xiezhy6/CPF-Net.